A step‑by‑step guide to creating self‑contained coding agents on Google Cloud Platform that can receive a request, spin up an isolated environment, generate code, test it, and return a pull request, all while keeping costs and security under control.
Hands‑Off Coding on GCP: Building Autonomous Agents with Guardrails
{{IMAGE:2}}
By Sivakumar Dhanasekar – May 26, 2026
The problem
Development teams spend a lot of time on repetitive tasks: creating boiler‑plate files, applying a known refactor, or running a suite of tests after a small change. When those steps are performed manually, they become bottlenecks, and when they are scripted they often lack the safety nets needed for production code. The challenge is to build an automated worker that can take a high‑level request, execute the work in a clean sandbox, verify the outcome, and hand the result back to a human reviewer without ever needing interactive input.
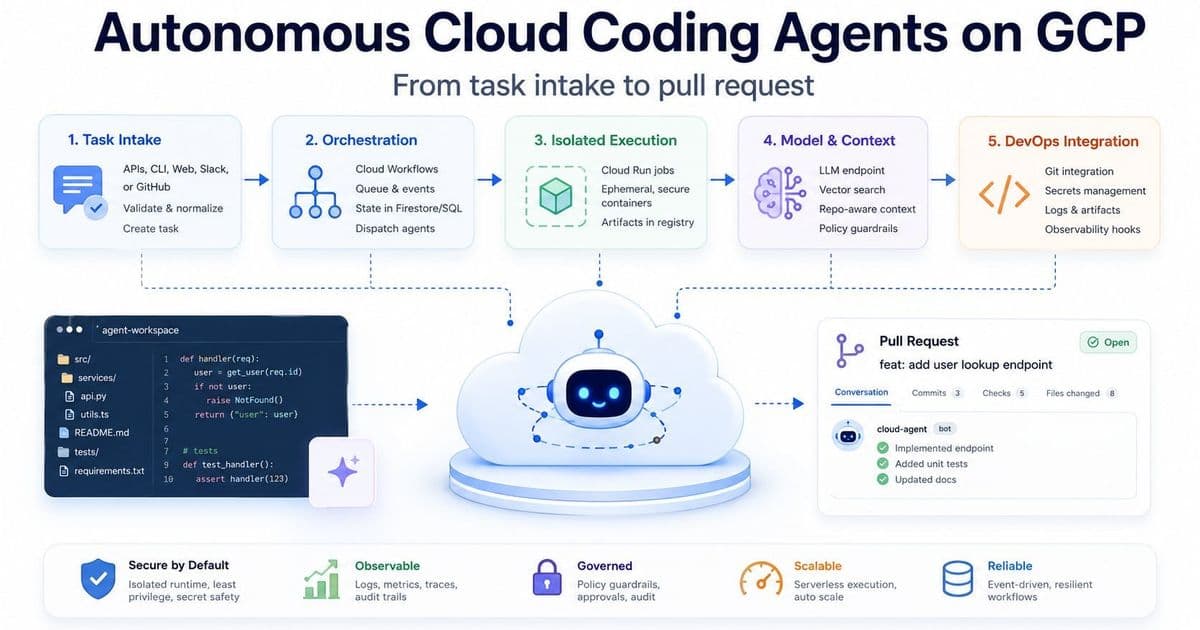
A pragmatic architecture on Google Cloud Platform
Below is a component‑by‑component breakdown that turns the abstract idea into a concrete, auditable system.
1. Task intake – a single entry point
- Cloud Run (or API Gateway + Cloud Run) exposes a REST endpoint that accepts JSON payloads describing the desired change.
- Optional front‑ends: Slack slash commands, a small CLI, GitHub issue webhooks, or a simple web form.
- The endpoint validates the payload schema and returns a task identifier immediately, so the caller does not wait for the whole workflow.
2. Durable orchestration
- Cloud Workflows defines a clear state machine: admission → context hydration → workspace provisioning → agent execution → finalization.
- Cloud Tasks queues the work, applying rate‑limiting and back‑pressure to keep costs predictable.
- Pub/Sub (optional) publishes status events that can be consumed by dashboards or notification bots.
3. Isolated compute per task
| Need | Recommended service |
|---|---|
| Short‑lived, stateless jobs | Cloud Run Jobs (default choice) |
| Stronger isolation, custom sandbox | GKE Autopilot with per‑job namespaces |
| Heavy builds or large test suites | Ephemeral Compute Engine VMs (last resort) |
Each job clones the target repository, checks out a fresh branch, installs dependencies, and runs a quick sanity check before handing control to the LLM.
4. Secrets and identity
- Secret Manager stores GitHub App tokens, API keys for LLM endpoints, and any other credentials.
- Workload Identity Federation and tightly scoped service accounts ensure that only the component that needs a secret can read it.
5. Artifact and state storage
- Cloud Storage holds logs, generated patches, test reports, and any binary artifacts.
- Firestore (or Cloud SQL) records task metadata: status, timestamps, links to the generated PR, and a small “memory” object that can be reused by later runs on the same repo.
- Artifact Registry keeps the container images used by Cloud Run Jobs, making roll‑backs trivial.
6. Observability and governance
- Cloud Logging aggregates stdout/stderr from every job.
- Cloud Monitoring tracks CPU, memory, and cost per task.
- Cloud Trace (optional) helps locate latency spikes in the workflow.
7. Model/agent runtime
- Vertex AI hosts the large language model that drives the code generation.
- For teams that prefer an external provider, a private endpoint behind a VPC‑SC connector can be used instead.
- When repository‑aware retrieval is needed, Vertex AI Search can be layered on top to fetch relevant code snippets.
The “Decision Engine” pattern – how a single request flows
- Admission (fail fast) – The orchestrator checks payload size, validates repo access, and confirms that the caller is authorized. If any check fails, the task is aborted and an error is returned to the requester.
- Context hydration – The system pulls the latest
README, contribution guidelines, and recent PR patterns from the repo. Optional “memory” from prior runs is read from Firestore and added to the prompt as structured data. - Provision an isolated workspace – A fresh Cloud Run Job starts, clones the repo, creates a new branch, and runs a lightweight lint step to ensure the environment is sane.
- Agent execution – The LLM receives the prepared prompt, emits a diff, and the job applies the diff. Unit tests and lint are executed; any failure triggers a rollback and a detailed log entry.
- Finalization – On success, the job pushes the branch, opens a pull request via the GitHub API, and attaches a summary that includes:
- What changed and why
- Test results and benchmark deltas
- A link to the full log stored in Cloud Storage The PR becomes the hand‑off point for human review.
Security non‑negotiables
- Least‑privilege service accounts for every component (Cloud Run, Cloud Tasks, Vertex AI).
- Secret Manager access limited to the exact runtime that needs a token.
- Network egress controls – deny unrestricted internet access from the job containers; allow only the endpoints required for GitHub, Vertex AI, and internal storage.
- Allow‑list of repositories – the intake API rejects any request that references a repo outside a pre‑approved list.
- Sandbox constraints – CPU, memory, and execution time limits are enforced at the Cloud Run Job level; privileged containers are prohibited.
- Audit logs – every task records who submitted it, which repo, which branch, and which artifacts were produced. If the logs cannot be reconstructed, the run must be considered a failure.
Practical tips for a quick start
- Begin with Cloud Run Jobs; they provide enough isolation for most code‑generation workloads and require minimal configuration.
- Pair them with Cloud Tasks to smooth out bursts of incoming requests.
- Keep deterministic steps (repo cloning, linting) separate from the non‑deterministic LLM call; this makes retries cheap and predictable.
- Treat the PR as a product: a clear title, a concise description, and attached evidence (test logs, screenshots).
- Store only the context that improves outcomes; never cache raw secrets or large blobs of code in Firestore.
Closing thoughts
Self‑coding agents are no longer a speculative concept; they are a practical tool for teams that can afford the discipline required to run them safely. The real advantage comes from a repeatable workflow, strong guardrails, and transparent hand‑off to a human reviewer. Whether you choose Cloud Run Jobs for simplicity or GKE Autopilot for tighter sandboxing, the core pattern remains the same: a deterministic scaffold that wraps a powerful but unpredictable LLM.
If you let me know which runtime you prefer and which model endpoint you plan to use, I can provide a detailed diagram and a checklist tailored to your stack.
Tags: #ai-coding-agents #google-cloud-platform #ai-orchestration #background-agents #ai-runtime #ai-governance #workflow-orchestration
Comments
Please log in or register to join the discussion