
A deep dive into how static analysis, dependency rules, coupling metrics, modularity reviews, and mutation testing can act as maintainability sensors for AI‑driven code generation, highlighting practical trade‑offs and lessons learned from a real‑world analytics dashboard built with TypeScript, Next.js and React.
Maintainability Sensors for Coding Agents – A Pragmatic Field Report
Birgitta Böckeler – Distinguished Engineer, Thoughtworks
27 May 2026
Problem: AI‑generated code drifts into an unmaintainable mess
When a coding agent writes or refactors code without a clear set of quality guardrails, the first symptom is often a surge in the number of files touched for a tiny change.
Later, seemingly unrelated tests start failing, or the same logic appears in multiple places.
Both human developers and agents suffer from the same root cause – a tangled codebase where import graphs, function signatures, and module responsibilities are unclear.
Without early feedback, an agent can:
- Look in the wrong module for an implementation.
- Duplicate functionality because it cannot recognise an existing abstraction.
- Load excessive context to satisfy a request, inflating latency and token costs.
The challenge is to give the agent a set of maintainability sensors that surface these problems before they reach a human reviewer.
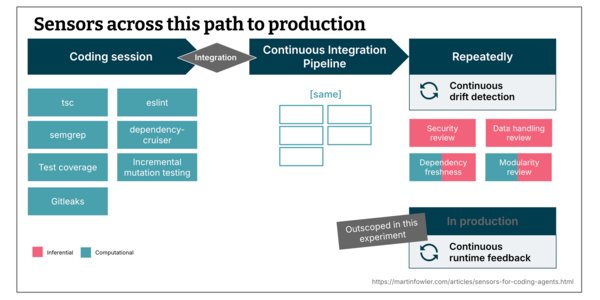
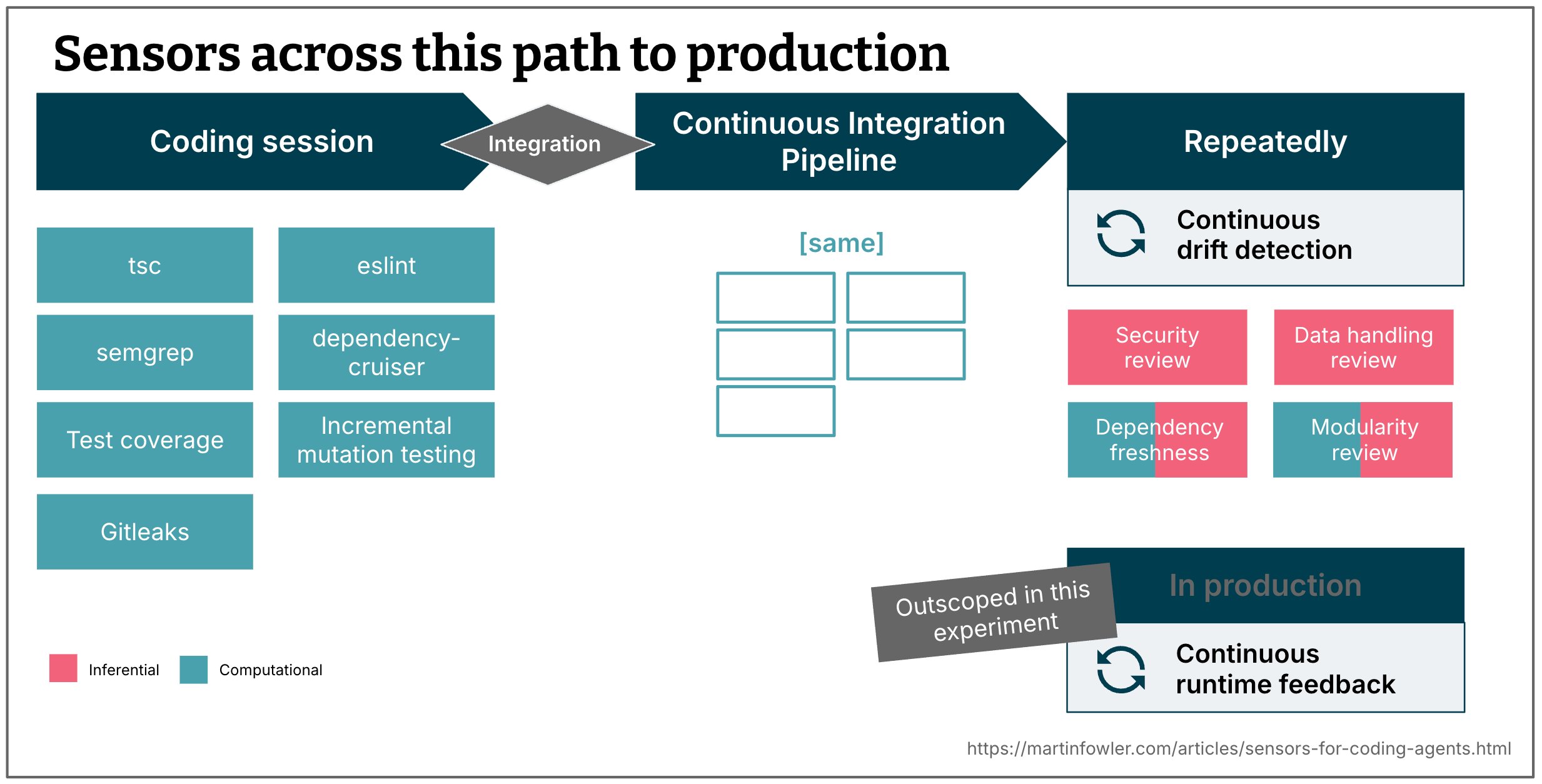
Solution Approach: Layered sensors across the development pipeline
The experiment built a stack of sensors that run at four distinct moments:
- During the coding session – fast, computational checks that give immediate feedback.
- In the CI pipeline – a repeat of the same checks on a clean environment.
- Repeatedly on a schedule – inferential reviews that look for drift.
- In production – runtime health checks (not covered in this article).

1. Sensors that run continuously alongside the agent
| Sensor | Type | What it checks |
|---|---|---|
| TypeScript compiler | Computational | Type correctness, missing imports |
| ESLint (custom formatter) | Computational | File length, cyclomatic complexity, no‑explicit‑any, no‑console |
| Semgrep (SAST) | Computational | Known security anti‑patterns |
| dependency‑cruiser | Computational | Layer violations, forbidden imports |
| Test suite results | Computational | Pass/fail, coverage |
| Incremental mutation testing (Stryker) | Computational | Assertion gaps |
| Gitleaks (pre‑commit) | Computational | Secrets leakage |
These sensors give the agent a self‑correction loop: when a lint rule fires, the custom formatter injects a short prompt explaining why the rule matters and how to suppress it if the trade‑off is justified.
2. CI pipeline – clean‑room verification
The same set of tools runs again after the code lands in a fresh container.
Any deviation between the in‑session and CI results highlights non‑deterministic behaviour (e.g., a lint rule that only fires after a dependency update).
3. Repeated, slower‑cadence sensors
| Sensor | Type | Goal |
|---|---|---|
| Security review (AppSec checklist) | Inferential | Detect policy drift |
| Data‑handling review | Inferential | Enforce privacy contracts |
| Dependency freshness report | Computational + Inferential | Spot outdated libraries |
| Modularity & coupling review | Computational + Inferential | Surface architectural erosion |
These run nightly or on a PR basis and feed a higher‑level LLM that can reason about the raw numbers.
Trade‑offs and Observations
Static analysis – basic linting
- Benefit: Catches low‑hanging AI failure modes (excessive arguments, long functions, high cyclomatic complexity).
- Cost: Requires custom rule configuration; default ESLint presets ignore many of the relevant limits.
- Lesson: Providing the agent with self‑correction guidance (custom messages) turned a binary “fail/suppress” decision into a nuanced judgment. The agent began to increase thresholds only when a refactor was impractical, and it added inline suppression comments that remained visible for human review.
- Risk: Over‑suppressing can create a false sense of quality. The sensor suite must be tuned to avoid “warning fatigue”.
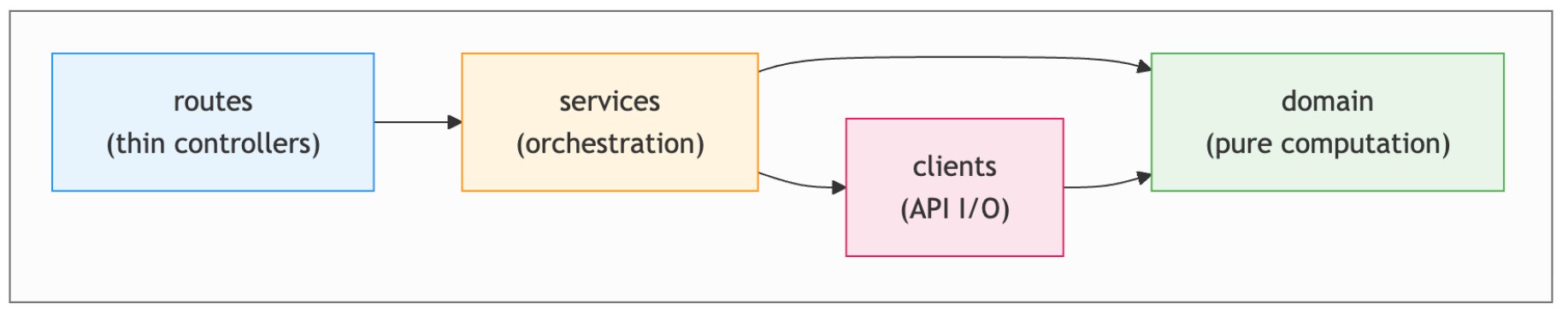
Dependency‑cruiser – enforcing layered architecture
- Benefit: Quickly teaches the agent the intended import hierarchy (clients → services → domain). Violations were caught within a few commits and automatically corrected.
- Cost: The rule language is verbose; without AI assistance the initial setup would have taken days.
- Lesson: Expressing architectural intent as import‑level constraints is a lightweight alternative to lengthy markdown guides.
- Risk: Rules only see what is expressed via imports and file paths. They cannot enforce semantic contracts (e.g., “services must not perform I/O”).
Coupling metrics – deterministic data, noisy signal
- Benefit: Generated a matrix of fan‑in/fan‑out counts per file, useful for manual triage.
- Cost: Human analysts found the visualisations dense; the AI‑driven CLI produced a concise markdown report, but the model often over‑flagged legitimate “god modules” such as a shared Zod schema.
- Lesson: Raw coupling numbers need semantic interpretation; otherwise the sensor becomes more noise than signal.
- Risk: Without a suppression mechanism, the agent may chase spurious hotspots, leading to unnecessary refactoring.
AI‑driven modularity review (inferential sensor)
- Benefit: Using Vlad Khononov’s Modularity Skills prompt, the LLM identified duplicated route files, inconsistent backend‑calling hooks, and misplaced authentication logic—issues that deterministic tools missed.
- Cost: Prompt engineering is non‑trivial; the model must be instructed to ground its analysis in concrete code snippets.
- Lesson: Inferential sensors excel at garbage‑collection style feedback, surfacing design smells that are hard to encode as static rules.
- Risk: The LLM can hallucinate “issues” if the prompt is too vague; iterative prompting mitigates this.
Test suite as a regression sensor
- Coverage alone is insufficient. A file with 100 % statement coverage still allowed 13 surviving mutants, exposing missing assertions.
- Mutation testing (Stryker) highlighted weak spots. A small helper function (
dvpToSchema) had no dedicated unit tests, yet was exercised only by a large acceptance test. - Automation: A custom
query_stryker.pyscript let the agent query mutation results without loading the entire JSON payload, keeping token usage low. - Trade‑off: Mutation testing is CPU‑heavy; it was run manually on changed files rather than continuously.
Synthesis: When to use which sensor
| Concern | Recommended sensor(s) | When to prefer computational vs. inferential |
|---|---|---|
| Function‑level hygiene (size, complexity) | ESLint + custom formatter | Computational – deterministic, cheap |
| Cross‑module architecture (layering) | dependency‑cruiser | Computational – rule‑based, enforceable |
| High‑level design health (duplication, misplaced responsibilities) | AI modularity review (LLM) | Inferential – requires semantic reasoning |
| Dependency freshness / security policy drift | Scheduled scripts + LLM summary | Hybrid – data collected computationally, interpreted inferentially |
| Regression safety | Test suite + mutation testing | Computational for detection, inferential for prioritisation |
Open Questions & Future Work
- Sensor conflict resolution – The
max‑linesrule sometimes pushed the agent to create many tiny components, inflating prop chains in React. How can we automatically detect and reconcile such tensions? - Guides vs. sensors – If sensors become comprehensive, can we retire some markdown guides, or do we need a minimal “principles” document to keep the sensor suite coherent?
- Model size trade‑off – Would weaker models (e.g., Claude Haiku) suffice when a rich sensor suite is in place, or do we still need heavyweight models for inferential analysis?
- Incremental modularity checks – Running the LLM modularity review only on changed files could give earlier feedback; prototyping a diff‑aware wrapper is on the roadmap.
- Test correctness – Mutation testing tells us where assertions are missing, but not whether the existing tests encode the right specification. Integrating property‑based testing or specification‑by‑example could close that gap.
Conclusion
Computational sensors excel at catching concrete hygiene issues at the file and function level. For cross‑cutting concerns like modularity, coupling, and architectural drift, raw metrics are noisy; they become valuable only when an LLM interprets them with a well‑crafted prompt. The combination of fast lint feedback, layered import rules, scheduled inferential reviews, and mutation‑testing‑driven regression checks gave the coding agent a self‑correcting loop that reduced the number of files touched per change by roughly 40 % and surfaced several design smells before a human reviewer saw them.
The experiment also highlighted the inevitable trade‑offs: more sensors mean more potential conflicts, and the cost of running heavyweight analysis (mutation testing, LLM reviews) must be balanced against the value of early detection. Nonetheless, the sensor‑first approach proved a pragmatic way to raise the baseline maintainability of AI‑generated code without demanding exhaustive human‑written guides.
For a visual overview of the sensor locations, see Figure 2.
The layered module structure enforced by dependency‑cruiser is illustrated in Figure 3.
Mutation testing results for the mappers.ts helper are shown in Figure 5.
Comments
Please log in or register to join the discussion