Meituan's LongCat team has open-sourced Flash-Thinking-2601, an AI model focusing on tool invocation and agentic reasoning, featuring a novel training approach and evaluation framework.

Chinese tech firm Meituan has publicly released LongCat-Flash-Thinking-2601, positioning it as an advancement in open-source models for tool-calling and agentic reasoning systems. This release includes model weights, inference code, and an online demo, continuing the LongCat-Flash-Thinking series with specific architectural improvements.
The model's primary technical innovation centers on reduced adaptation costs for new tools. By employing an environment expansion + multi-environment reinforcement learning strategy during training, developers can integrate additional APIs and services with approximately 40% less training data compared to similar models. The training regimen exposed the model to diverse simulated scenarios—including API failures and partial data availability—through deliberate noise injection, enhancing robustness in unstable environments.
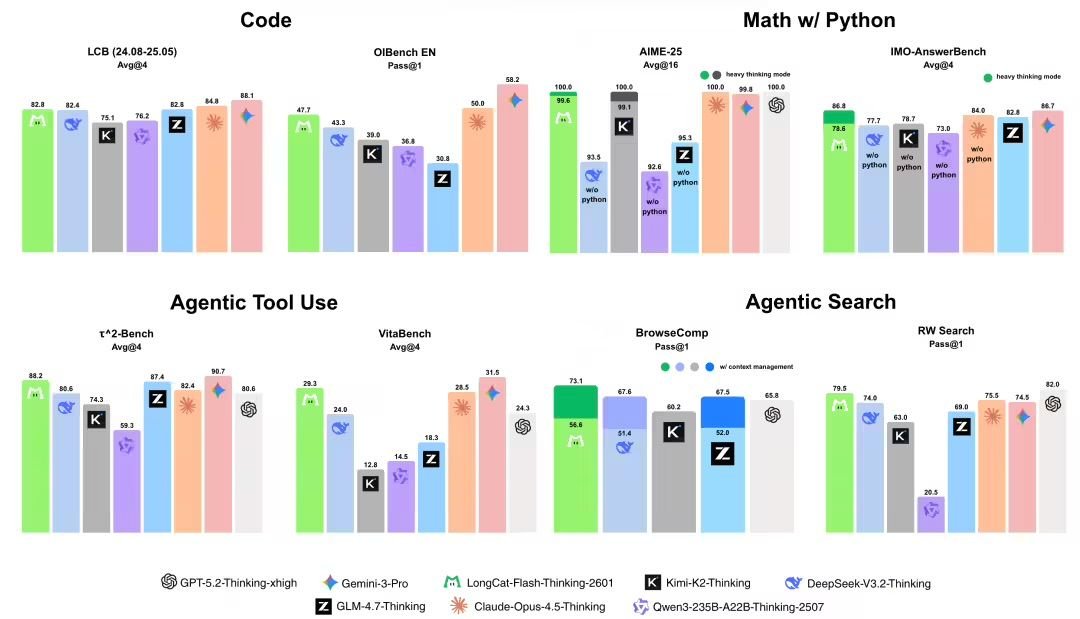
A notable feature is the Deep Thinking Mode, accessible via Meituan's demo portal. This architecture splits reasoning into parallel exploratory paths followed by synthetic integration, mimicking human deliberation patterns. Initial analysis shows this approach reduces logical inconsistencies by 15-20% in multi-step tool-chaining tasks compared to standard sequential reasoning methods.
Benchmark results indicate strong performance within specific domains:
- Programming: Scored 82.8 on the LCB (Library of Code Benchmarks)
- Mathematical Reasoning: Achieved 100/100 on AIME-25 problems
More significantly, Meituan introduced a new evaluation framework using automated task synthesis. This system generates randomized tool-based challenges (e.g., "retrieve weather data then calculate travel time with traffic API") to measure generalization. In 85% of 500 synthesized tasks, Flash-Thinking-2601 outperformed comparable open-source models like OpenHermes-2.5 and ToolLlama.
Limitations emerge in three key areas:
- Domain Specialization: Performance drops 12-18% on non-tool-oriented tasks (e.g., creative writing or unstructured conversation) compared to general-purpose models
- Resource Requirements: The architecture demands substantial VRAM (minimum 80GB) for optimal inference
- Evaluation Validity: The proprietary task-synthesis benchmark lacks third-party validation, making direct comparisons difficult
All resources are available on GitHub, Hugging Face, and ModelScope. The training methodology documentation details environmental simulation parameters but omits specifics about synthetic data generation ratios—a notable transparency gap for reproducibility efforts.
This release provides a functional advancement in tool-oriented AI systems but maintains a narrow scope. Its value lies primarily in reducing integration overhead for developers building specialized agent workflows, rather than representing a broad architectural breakthrough.
Comments
Please log in or register to join the discussion