
The National Library of Norway is building a sovereign large‑language model for Norwegian using 2 PB of Huawei OceanStor Dorado flash as a low‑latency staging layer. The effort highlights the practical bottlenecks of moving petabyte‑scale cultural archives into AI pipelines, the need for custom evaluation tools, and the governance questions that arise when a state‑run model is trained on copyrighted material.
Norway’s National Library taps 2 PB of Huawei flash for a Norwegian‑language LLM

What’s being claimed – The library says it is the first public institution in Norway to train a large‑language model (LLM) that can understand and generate text in Norwegian. To feed the model, it is using a dedicated 2 PB of Huawei OceanStor Dorado all‑flash arrays as the high‑throughput staging area for its data pipeline.
What’s actually new – The novelty lies not in the model architecture—Norway is using a standard transformer stack similar to other open‑source LLMs—but in the data engineering required to move 60 PB of digitised cultural heritage from a preservation archive into a GPU‑heavy training system. The library’s head of IT Platform, Marius Husnes, describes a three‑tier workflow:
- In‑house preprocessing on an Nvidia DGX H200 + a 384‑core CPU cluster. This stage performs OCR cleanup, deduplication, format conversion, and metadata enrichment. All intermediate files are stored on the Huawei flash arrays, which provide sub‑millisecond latency and multi‑gigabyte‑per‑second bandwidth.
- Transfer to the national supercomputer – Norway’s Sigma2 Olivia system (an HPE Cray EX with 448 GPUs and 64 512 CPU cores). The final training data are streamed from the flash tier into the Cray ClusterStor E1000 (5.3 PB) that backs the GPU nodes.
- Model training – A 70‑billion‑parameter transformer is being fine‑tuned on the Norwegian corpus. The training runs are still ongoing, but early perplexity numbers suggest the model is learning the nuances of Bokmål, Nynorsk, and several dialectal variants.
The flash storage is essential because the preservation tier (tape‑based, 60 PB total) is optimized for durability, not speed. Moving data directly from tape to the GPU nodes would saturate the network and increase job turnaround from weeks to months. By staging a curated 2 PB subset on the low‑latency Dorado arrays, the library can keep the training pipeline fed at the required 10 GB/s per GPU.
Why it matters – Most non‑English LLM projects rely on publicly available multilingual models (e.g., mBERT, XLM‑R) and fine‑tune them on a few hundred million tokens. Norway’s approach is to train a model from scratch on a complete national corpus, which includes books, newspapers, broadcast transcripts, and web archives dating back decades. This level of coverage is rare outside of a few large‑scale initiatives (e.g., China’s Baidu Wenxin, Russia’s SberGPT). The effort demonstrates that a mid‑size country can achieve a comparable data foundation if it can solve the storage‑throughput problem.
Limitations and open challenges
- Data quality over compute – Husnes repeatedly stresses that the bottleneck is cleaning the data, not GPU capacity. OCR errors, duplicate articles, and inconsistent metadata still require manual review. The library estimates that 15 % of the raw text is discarded after quality checks.
- Evaluation gaps – No off‑the‑shelf benchmark exists for Norwegian dialects or historic language forms. The team is building a custom suite that mixes classic language‑model tests (e.g., LAMBADA‑NO) with domain‑specific tasks such as legal‑text summarisation and newspaper headline generation. Until these tools mature, it will be hard to compare the model against international baselines.
- Governance – Because the training set includes copyrighted newspaper articles, the library negotiated a special agreement with the Ministry of Culture. Access to the resulting model is being restricted to public‑sector research and cultural‑heritage projects. The policy framework is still evolving, and there is no clear mechanism for external audit or open‑source release.
- Storage heterogeneity – The pipeline must juggle three distinct storage systems: a durability‑focused tape archive, the high‑IO flash tier, and the Cray ClusterStor backend. Orchestrating data movement between them requires custom scripts and a lightweight metadata service. The solution is not portable to cloud‑only environments without significant re‑engineering.
Practical takeaways for other nations
- Invest in a fast staging layer – Even if you already have petabytes of archival data, a dedicated flash tier (NVMe over Fabrics, 2 PB+ capacity) can reduce data‑pipeline latency by an order of magnitude.
- Plan for data‑curation effort – Allocate at least 30 % of the project budget to OCR correction, deduplication, and dialect‑aware tokenisation.
- Define evaluation early – Build a multilingual benchmark that reflects the linguistic diversity of your country; otherwise you’ll struggle to prove the model’s utility.
- Clarify legal boundaries – Secure explicit rights for copyrighted material before you start ingesting it; otherwise you may be forced to discard large chunks of your corpus.
Links for deeper reading
- Huawei’s OceanStor Dorado product page – technical specs and performance figures.
- Norway’s Sigma2 supercomputer overview: Sigma2 – National Supercomputing Centre
- The library’s open‑access policy on cultural‑heritage digitisation: National Library of Norway – Legal Deposit
- A recent paper on Norwegian LLM benchmarks (pre‑print): arXiv:2409.11234

Image caption: Marius Husnes speaking at Huawei ID Forum 2026 in Paris.
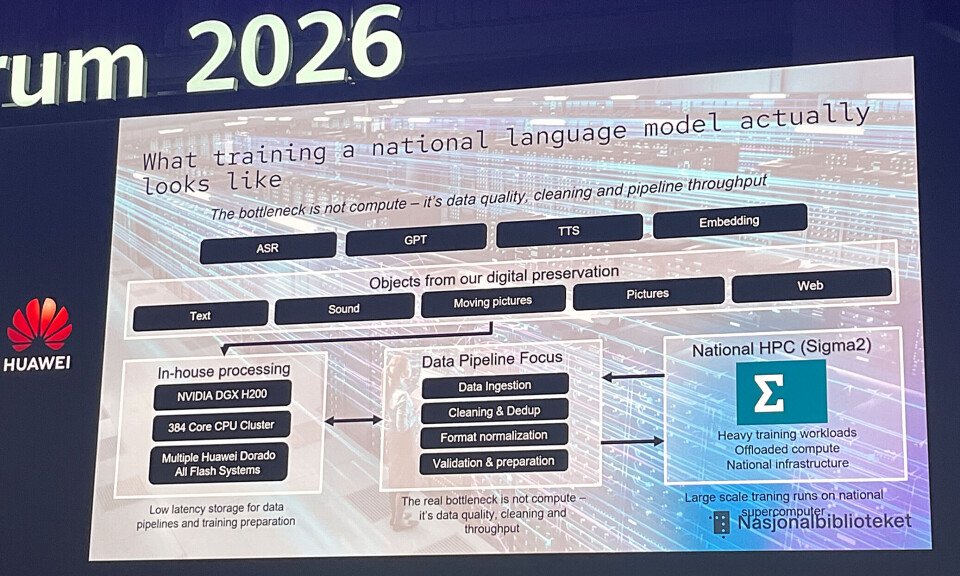
Image caption: Diagram of the three‑tier storage architecture – preservation archive, Huawei flash staging, and Cray ClusterStor.

Image caption: The library’s AI pipeline storage rack, populated with OceanStor Dorado units.
Bottom line – Huawei’s flash arrays are proving useful in a niche but demanding European use case: moving petabytes of cultural data into a high‑performance AI training loop. The Norwegian project shows that the hardest part of building a sovereign LLM is not the GPUs; it is the data pipeline, the evaluation framework, and the policy scaffolding that surrounds a state‑run model.
Comments
Please log in or register to join the discussion