This article explores how NVIDIA Dynamo integrates with Azure Kubernetes Service to address the complex challenge of autoscaling GPU resources for Large Language Model inference workloads, balancing cost efficiency with performance requirements.
The rapid transition of Large Language Models from experimentation to production has created significant challenges for infrastructure teams. While training often receives attention, inference at scale presents unique complexities when balancing performance, cost, and user experience under unpredictable traffic patterns. Azure Kubernetes Service (AKS) combined with NVIDIA Dynamo offers a solution for scalable, production-ready LLM inference with intelligent autoscaling capabilities.
The Challenge of LLM Inference Autoscaling
Unlike traditional applications, LLM inference presents unique scaling challenges that require specialized approaches. First, the metrics involved are variable and non-linear. Each request can vary significantly in compute cost depending on model size, precision, input and output token length, and KV cache hit rate. Traditional metrics like GPU or memory utilization alone cannot represent the actual load.
Second, LLM inference consists of multi-phase pipelines with distinct performance characteristics. The prefill phase processes context, followed by routing, and then the decode phase generates tokens. Each phase has different resource requirements, making coordinated scaling essential.
Finally, GPUs present specific constraints for autoscaling. They are slower to provision than CPUs, less elastic, and more expensive with limited availability. Efficient packing, maintaining warm capacity, and making informed scaling decisions become critical factors in production environments.
Azure's GPU Infrastructure for AI Workloads
Azure offers a comprehensive portfolio of AI-optimized virtual machines designed specifically for inference and training workloads. Selecting the appropriate GPU SKU depends on several factors including model size, throughput requirements, latency Service Level Objectives (SLOs), and cost targets.
AKS enables the management of these GPUs through autoscaling node pools, forming the foundation for elastic inference platforms. The integration allows teams to leverage Azure's GPU infrastructure while maintaining the flexibility and operational benefits of Kubernetes.
NVIDIA Dynamo: Purpose-Built for Production LLM Workloads
NVIDIA Dynamo is specifically designed to address the complexities of production LLM inference workloads. It provides several key capabilities:
Smart routing efficiently distributes requests across workers based on current load and capacity. KV cache management improves memory efficiency by maximizing cache reuse across requests. Low-latency communication optimizes GPU-to-GPU and service communication to minimize bottlenecks. The GPU planner coordinates capacity decisions across the entire inference pipeline.
Together, these components enable Dynamo to treat inference as a complete system rather than just a collection of pods, which is essential for effective autoscaling.
The Integration: Dynamo and AKS
The power of this architecture lies in how Dynamo integrates natively with Kubernetes and Azure:
Dynamo exposes Kubernetes scale subresources, allowing it to work seamlessly with Kubernetes Horizontal Pod Autoscaler (HPA), KEDA, and custom controllers. AKS automatically scales GPU node pools based on pending pod demand using the cluster autoscaler. The solution includes built-in observability through integration with Azure Managed Prometheus and Grafana, providing real-time inference metrics, visibility into latency and throughput, and enabling data-driven scaling decisions.
Autoscaling Strategies for Dynamo Workloads
Dynamo supports multiple autoscaling approaches to suit different requirements:
Kubernetes HPA works well for simple CPU or memory-based scaling and frontend services. KEDA (Event-Driven Autoscaling) is ideal when external or custom metrics are required, for scale-to-zero scenarios, or when a preset maximum number of replicas is needed.
Dynamo Planner provides LLM-aware autoscaling specifically designed for production inference. It offers adaptive scaling without preset maximum replica limits, disaggregated scaling of prefill and decode workers, uses live metrics and profiling data, and supports SLA-driven goals like Time to First Token (TTFT) below 500ms.
Custom controllers can be implemented for advanced or bespoke scaling logic when standard options are insufficient.
Metric Alignment: Scaling Based on Actual Pressure
A critical lesson in production inference is metric alignment—each service type should scale on signals that actually reflect pressure:
Frontend services should scale based on CPU utilization and request rate. Prefill workers should respond to queue depth and Time to First Token (TTFT). Decode workers should monitor KV cache utilization and inter-token latency (ITL).
When metrics match service behavior, scaling becomes both faster and more stable, preventing unnecessary resource consumption while maintaining performance.
Avoiding Common Autoscaling Pitfalls
Several best practices can prevent weeks of troubleshooting:
Use only one autoscaler per service to avoid multiple autoscalers fighting over the same workload. Properly configure stabilization windows to prevent rapid scale-down that causes resource thrashing. Set appropriate minimum and maximum replica limits to protect the cluster from unbounded scaling or accidental scale-to-zero scenarios. Understand traffic patterns, as short, spiky workloads require different strategies than steady-state serving.
Case Study: TTFT-Driven Autoscaling with KEDA
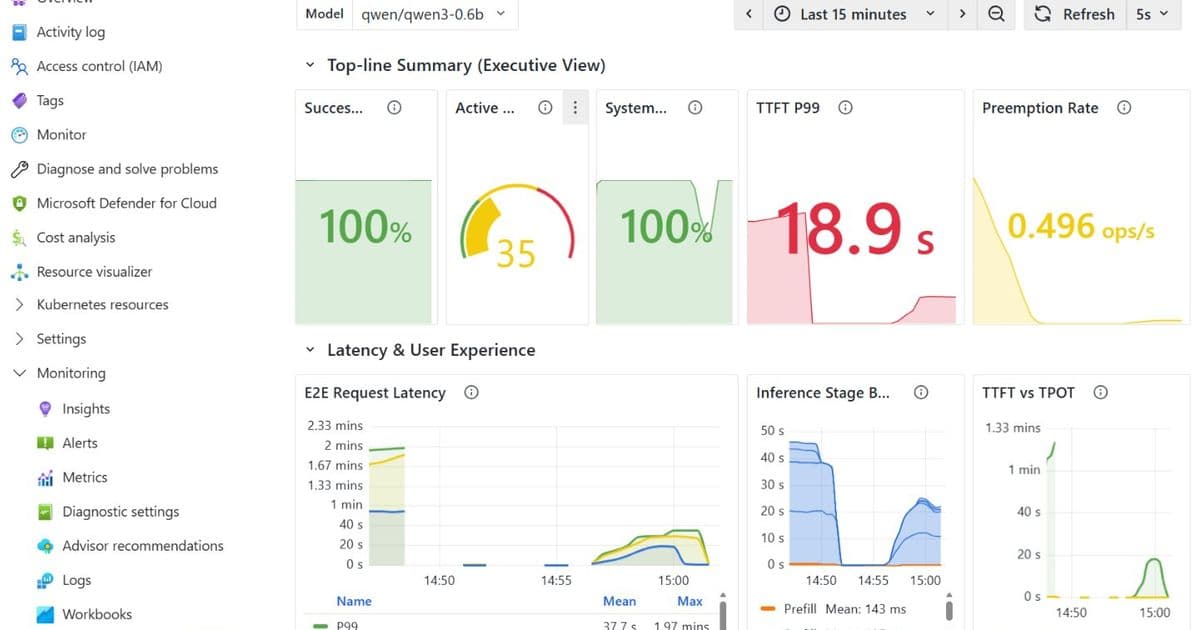
An example implementation shows NVIDIA Dynamo aggregated serving on AKS, where Prefill and Decode run in the same GPU worker pod. Autoscaling is handled by KEDA, using the 95th percentile Time to First Token (TTFT) from Prometheus as the scaling signal instead of traditional CPU or GPU utilization.
The configuration includes:
- Serving mode: Aggregated (Prefill + Decode per pod)
- Autoscaler: KEDA
- Scaling signal: TTFT p95 > 300ms
- Worker replicas: 2 → 4
- Scale-down cooldown: 120 seconds
- GPU: NC-H100
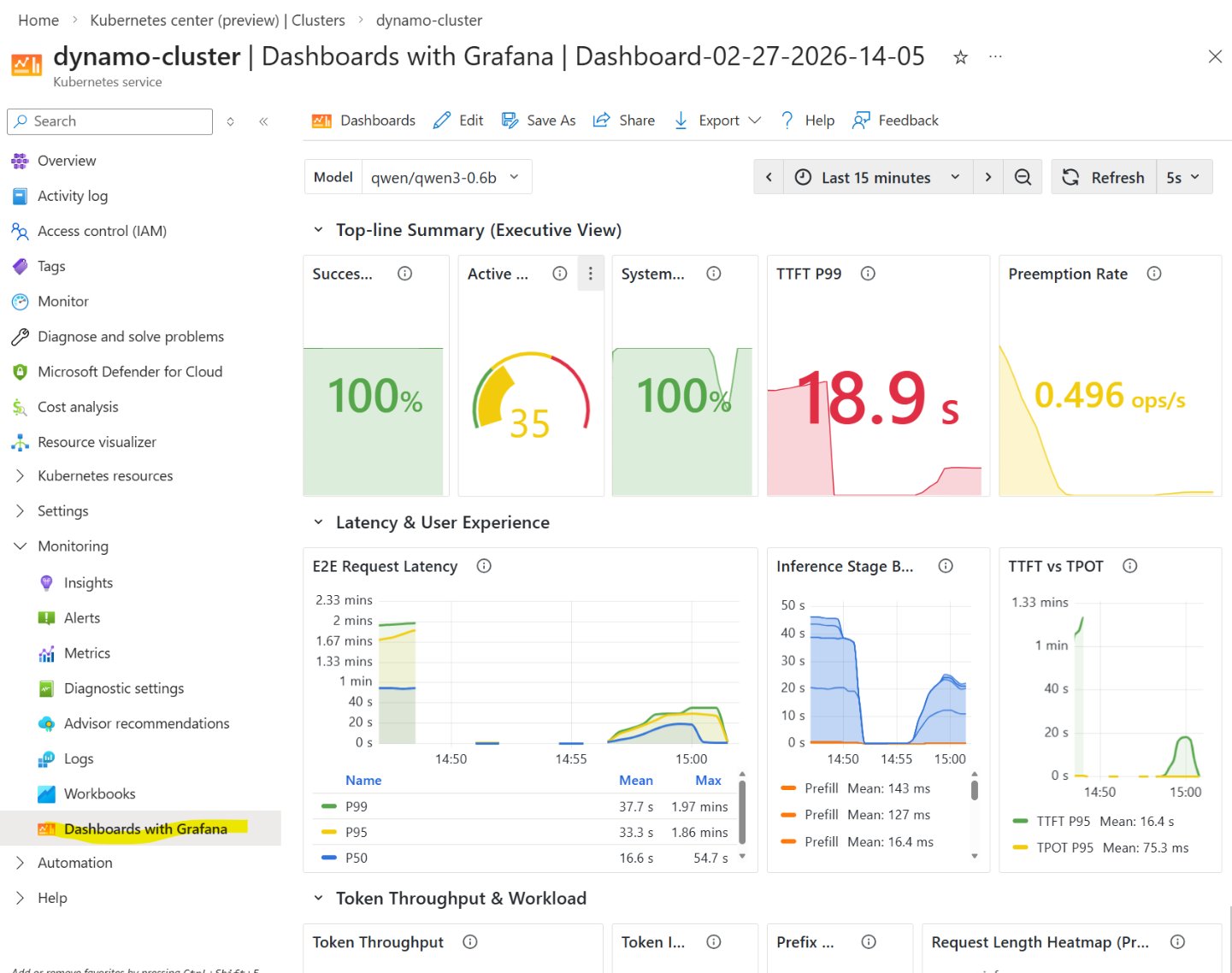
Testing with a Qwen3-0.6B model under constant load (36 RPS) with large input sizes (approximately 3000 tokens) revealed important insights about cold versus warm scaling. The first scale-up required approximately 8 minutes for new GPU nodes to be provisioned and initialized. Subsequent scale-ups were faster because the nodes remained "warm" with drivers loaded and models cached.
This demonstrates the importance of maintaining warm capacity in GPU environments to minimize the performance impact of scaling events. The implementation is available through the Dynamo on AKS GitHub repository, which provides end-to-end tutorials for running NVIDIA Dynamo on Azure Kubernetes Service.
Business Impact and Considerations
Implementing an intelligent autoscaling solution for LLM inference on AKS with NVIDIA Dynamo offers several business benefits:
Cost optimization by eliminating overprovisioning while maintaining performance SLAs. Improved user experience through consistent latency even under variable load. Operational efficiency through automated scaling decisions based on actual metrics. Resource flexibility to handle unpredictable traffic patterns without manual intervention.
Organizations considering this approach should evaluate their specific requirements for model size, throughput targets, latency expectations, and cost constraints. The solution is particularly valuable for applications with variable traffic patterns where manual capacity planning would be challenging.
For organizations already invested in Azure and Kubernetes, this integration provides a path to production-ready LLM inference without requiring entirely new infrastructure or operational paradigms. The combination of Azure's GPU infrastructure, Kubernetes orchestration, and NVIDIA's specialized LLM optimization creates a powerful platform for AI inference workloads.
The implementation guides and example configurations available through the GitHub repository provide a practical starting point for teams looking to implement similar solutions. As LLM inference continues to evolve from experimentation to production, these specialized autoscaling approaches will become increasingly important for maintaining the balance between cost efficiency and performance that modern AI applications require.
Comments
Please log in or register to join the discussion