
Nvidia has unveiled its Vera Rubin platform, a comprehensive silicon stack of seven co-designed chips that form the foundation of the company's AI factory supercomputers. The system scales from individual racks to 40-rack PODs delivering 60 exaflops of compute, representing a fundamental shift in how Nvidia packages and sells its hardware.
Nvidia's Vera Rubin Platform: Seven Chips Powering 60 Exaflop AI Factory
At GTC 2026, Nvidia announced the full production of seven chips that compose the Vera Rubin platform, designed to ship in the second half of 2026. Rather than a single product launch, these announcements cover the complete silicon stack required to build what Nvidia now calls an AI factory. The seven chips—GPUs, CPUs, inference accelerators, networking ASICs, data processing units, and Ethernet switches—are designed to operate as a single co-designed system across five rack types, scaling from individual racks to 40-rack PODs delivering 60 exaflops of compute.

This AI factory represents a significant shift in how Nvidia packages and sells its hardware. The unit of compute is no longer a GPU or even a server; it's the rack, and increasingly, the POD. Each of the seven chips fills a specific architectural role, and understanding what each does provides insight into what Vera Rubin fundamentally is.
The Compute Layer: Rubin GPU, Vera CPU, and Groq 3
Three chips handle the core compute workload, each optimized for a different phase of the AI pipeline.
Rubin GPU
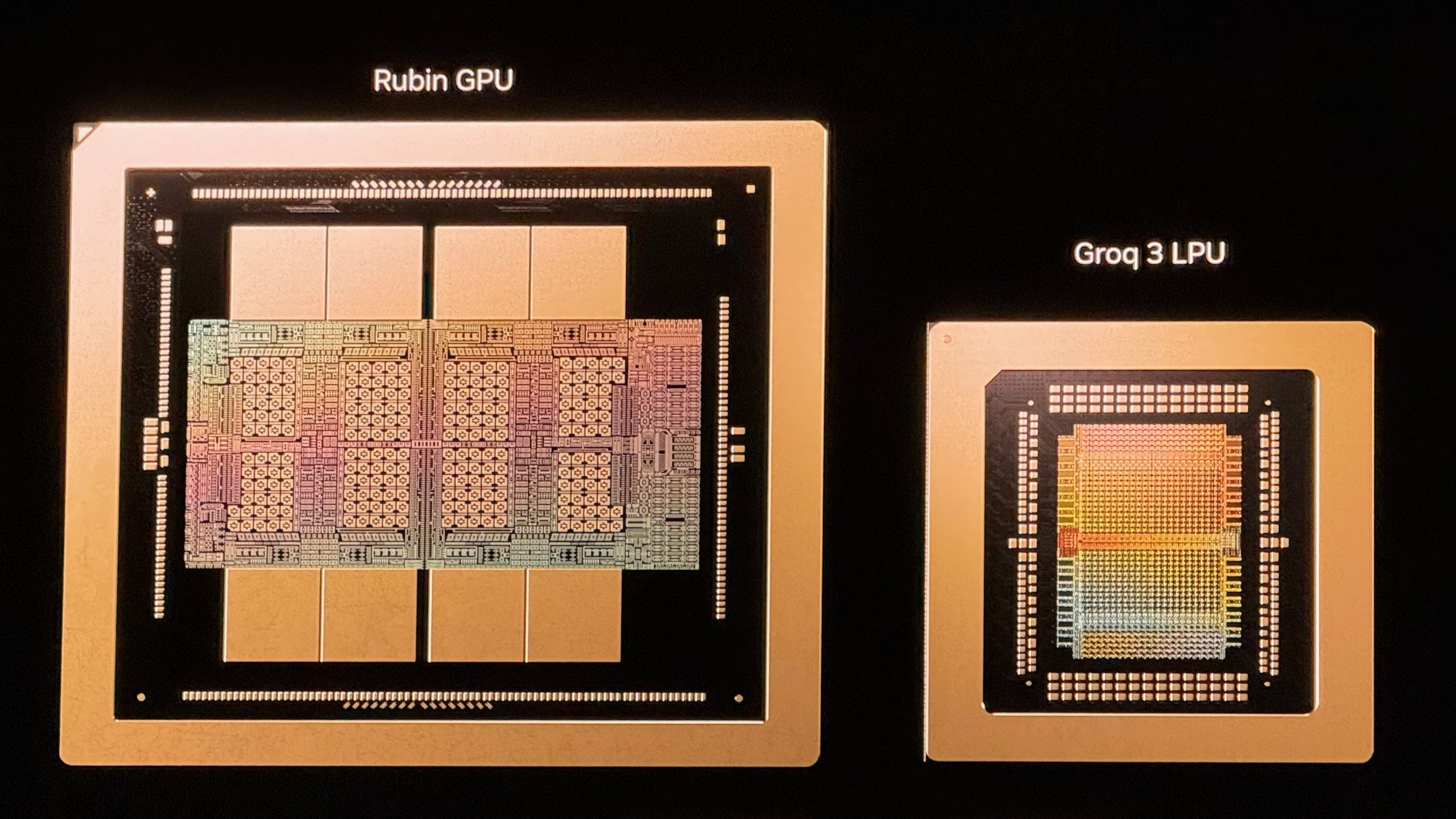
The Rubin GPU serves as the training and inference workhorse, built on TSMC's 3nm process. Each GPU uses a dual-die design packing 336 billion transistors, carries 288 GB of HBM4 memory with 22 TB/s of bandwidth, and delivers 50 PFLOPS of inference compute and 35 PFLOPS of training compute in the NVFP4 format. These figures represent 5 and 3.5 times improvements over Blackwell, respectively.
In the flagship Vera Rubin NVL72 rack, 72 Rubin GPUs connect via NVLink 6 to behave as a single accelerator. Nvidia claims that the NVL72 can train Mixture-of-Experts models with one quarter the GPU count required by Blackwell, and cut inference token costs by 10 times.
Vera CPU
The Vera CPU marks Nvidia's first data center CPU built from the ground up. It uses 88 custom Arm-based Olympus cores with Spatial Multithreading for 176 threads, up to 1.5TB of SOCAMM LPDDR5X memory, and 1.2 TB/s of memory bandwidth. Vera connects to Rubin GPUs via NVLink-C2C at 1.8 TB/s of coherent bandwidth, which is seven times faster than PCIe Gen 6.

Its role in the rack is orchestration: scheduling workloads, routing KV cache data, managing context, and running the control plane for agentic AI workflows. It also handles reinforcement learning environments and CPU-native workloads.
Groq 3 LPU
The Groq 3 LPU is purpose-built for low-latency decode-phase inference and represents a direct product of Nvidia's $20 billion acquisition of Groq in December. Where Rubin GPUs offer massive memory capacity through HBM4, the Groq 3 trades capacity for bandwidth: Each LPU can carry roughly 500MB of stacked SRAM and delivers approximately 80 TB/s of bandwidth per chip.
The Groq 3 LPX rack houses 256 LPUs with about 128GB of aggregate on-chip SRAM and 640 TB/s of scale-up bandwidth. Rubin GPUs handle the compute-heavy prefill phase of inference, processing long input contexts, with the Groq 3 LPUs stepping in to handle the decode phase, generating output tokens at low latency. Nvidia claims the combination delivers 35 times higher inference throughput per megawatt and 10 times more revenue opportunity for trillion-parameter models compared with running both phases on GPUs alone.
The Fabric: NVLink 6, ConnextX-9, and Spectrum-6

Moving data between chips at rack scale and between racks at cluster scale is handled by three dedicated networking ASICs.
NVLink 6 Switch
The NVLink 6 Switch, due to be upgraded to a 7th generation, handles scale-up connectivity within the rack. Each switch delivers 3.6 TB/s of bidirectional bandwidth per GPU, doubling Blackwell's NVLink performance, while a single switch tray provides 28.8 TB/s of total switching bandwidth and 14.4 TFLOPS of FP8 in-network compute, which accelerates collective operations like the all-to-all communication patterns used in MoE routing. Nine switch trays per NVL72 rack deliver 260 TB/s of aggregate scale-up bandwidth.
ConnectX-9 SuperNIC
The ConnectX-9 SuperNIC provides a scale-out networking endpoint at 1.6 Tb/s throughput per GPU. Where NVLink 6 connects GPUs within a rack, ConnectX-9 connects racks, linking NVL72 systems into multi-rack clusters via either Nvidia's Spectrum-X Ethernet or Quantum-X800 InfiniBand fabrics. Each compute tray uses eight ConnectX-9 NICs to deliver the aggregate bandwidth quoted for the tray's four GPUs.
Spectrum-6 Ethernet Switch
The Spectrum-6 Ethernet Switch delivers 102.4 Tb/s of aggregate bandwidth and is Nvidia's first switch to use co-packaged optics, employing silicon photonics to reduce optical power consumption. Nvidia claims five times improved power efficiency and 10 times improved resiliency over prior Spectrum-X generations. Available in two configurations, the SN6800 offers 512 ports of 800G Ethernet or 2,048 ports at 200G.
The Infrastructure Layer: BlueField-4

The final chip, BlueField-4 DPU, functions as a specialized processor that handles networking and storage tasks that would otherwise consume CPU and GPU cycles. A dual-die package that combines a 64-core Grace CPU with an integrated ConnectX-9 NIC, the BlueField-4 DPU offloads networking, storage, encryption, virtual switching, telemetry, and security enforcement from the main compute path, running Nvidia's DOCA software framework for infrastructure services.
Nvidia says it features twice the bandwidth, three times the memory bandwidth, and six times the compute of BlueField-3. BlueField-4 underpins the new BlueField-4 STX storage rack, which implements Nvidia's CMX context memory storage platform, essentially extending GPU memory into NVMe storage to cache the key-value data generated by agentic AI workflows.
As context windows grow to hundreds of thousands, and in some cases millions, of tokens, operations on the KV cache are becoming a bottleneck, and the STX rack is designed to break through it. Nvidia claims up to five times higher inference throughput when the STX storage tier is deployed alongside compute racks, via the new DOCA Memos software framework.
Five Racks, One Supercomputer
All seven chips map into five rack types that compose the Vera Rubin POD:
- The NVL72 for core training and inference (72 Rubin GPUs, 36 Vera CPUs)
- The Groq 3 LPX rack for decode acceleration (256 LPUs)
- The Vera CPU rack for RL and orchestration (256 Vera CPUs)
- The BlueField-4 STX rack for KV cache storage
- The Spectrum-6 SPX rack for Ethernet networking
A full POD spans 40 racks, 1,152 Rubin GPUs, nearly 20,000 Nvidia dies, 1.2 quadrillion transistors, and 60 exaflops. Vera Rubin-based products are scheduled to ship in the second half of 2026.
Market Implications
The Vera Rubin platform represents a significant evolution in Nvidia's AI hardware strategy. By co-designing all components of the system—from compute to networking to storage—Nvidia is creating increasingly integrated solutions that reduce the integration burden on customers while potentially improving performance and efficiency.
The inclusion of the Groq 3 LPU, acquired through the $20 billion Groq purchase, demonstrates Nvidia's commitment to addressing the specific bottlenecks in large language model inference, particularly the decode phase that requires low latency rather than massive compute capacity.
The platform's focus on context memory management through the BlueField-4 STX rack addresses another critical challenge in AI: the growing size of context windows and the associated KV cache management. As AI models continue to scale, this capability could become increasingly valuable.
Vera Rubin-based products are scheduled to ship in the second half of 2026, positioning Nvidia to maintain its leadership in the AI accelerator market as demand for increasingly powerful AI infrastructure continues to grow.
Comments
Please log in or register to join the discussion