Pinterest has launched a next-generation database ingestion framework using Change Data Capture (CDC) that reduces data latency from over 24 hours to as low as 15 minutes while processing only changed records.
Pinterest has launched a next-generation database ingestion framework to address the limitations of its legacy batch-based systems and improve real-time data availability. The previous infrastructure relied on multiple, independently maintained pipelines and full-table batch jobs, resulting in high latency, operational complexity, and inefficient resource utilization. Critical use cases, including analytics, machine learning, and product features, required faster, more reliable access to data.
The Problem with Legacy Systems
The legacy system faced several key challenges. Data latency often exceeded 24 hours, delaying analytics and ML workflows. Daily changes for many tables were below 5%, yet full-table batch processes reprocessed unchanged records, wasting compute and storage resources. Row-level deletions were not natively supported, and operational fragmentation across pipelines caused inconsistent data quality and high maintenance overhead.
As emphasized by a Pinterest engineer, "A unified DB ingestion framework built on Change Data Capture (Debezium/TiCDC), Kafka, Flink, Spark, and Iceberg provides access to online database changes in minutes (not hours or days) while processing only changed records, resulting in significant infrastructure cost savings."
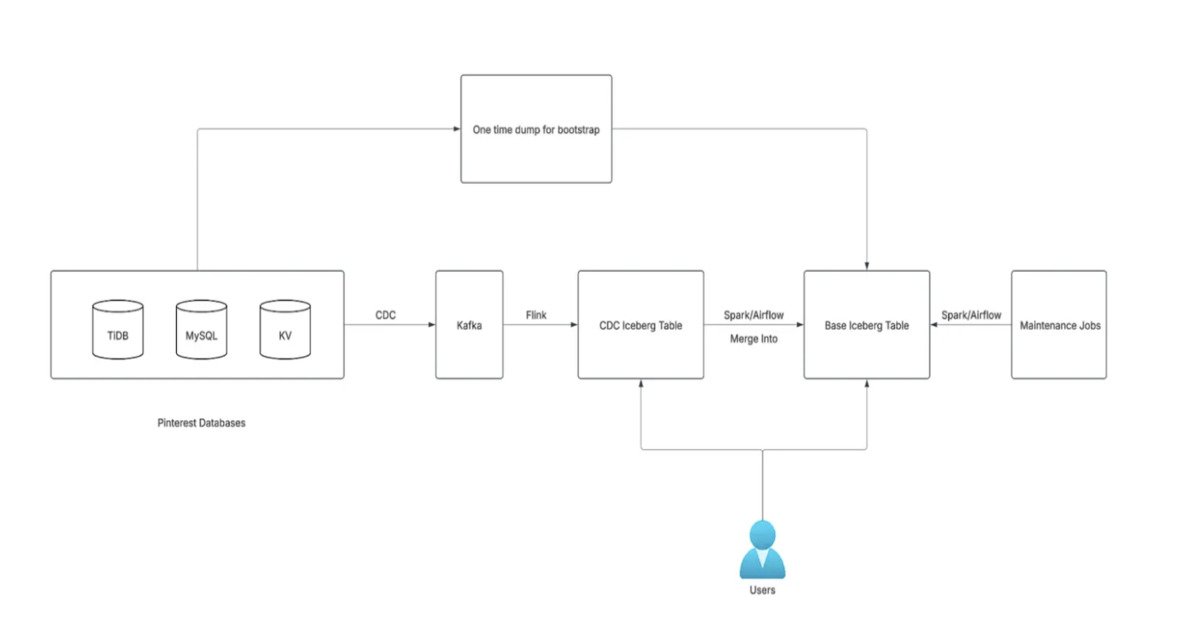
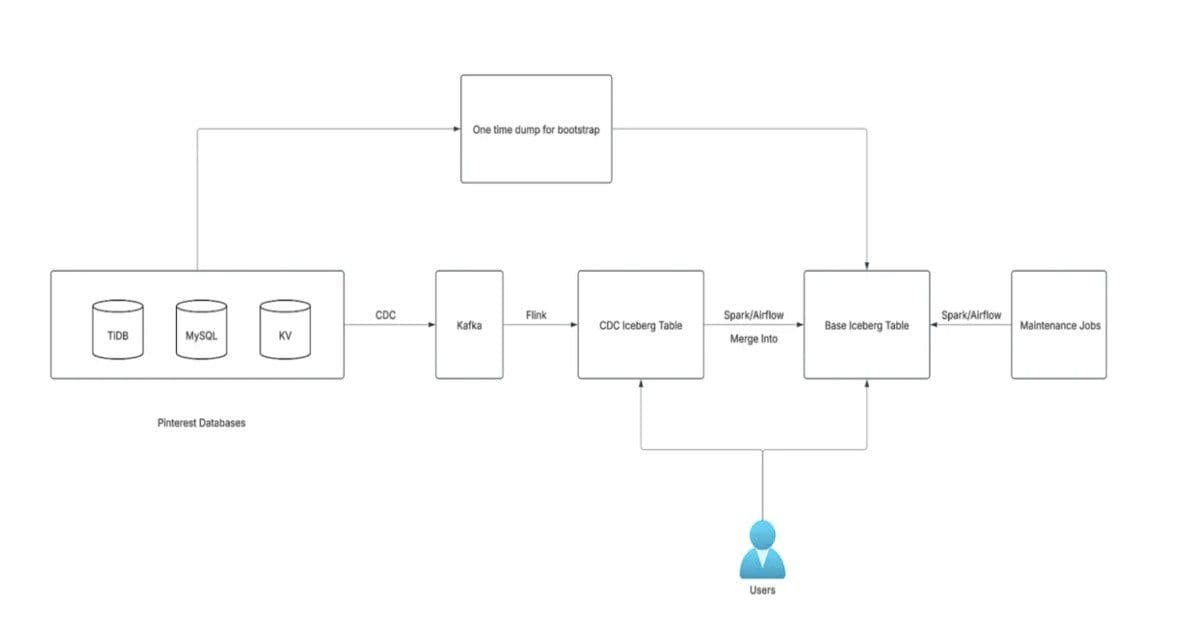
Next-Gen Architecture Overview
The framework is generic, supporting MySQL, TiDB, and KVStore, is configuration-driven for easy onboarding, and integrates monitoring with at-least-once delivery guarantees. The architecture separates CDC tables from base tables. CDC tables act as append-only ledgers, recording each change event with typical latency under five minutes. Base tables maintain a full historical snapshot, updated via Spark Merge Into operations every 15 minutes to an hour.
Iceberg's Merge Into operation provides two update strategies: Copy on Write (COW) and Merge on Read (MOR). Copy on Write rewrites entire data files during updates, increasing storage and compute overhead. Merge on Read writes changes to separate files and applies them at read time, reducing write amplification. After evaluating both strategies, Pinterest standardized on Merge on Read because Copy on Write introduced significantly higher storage costs that outweighed its benefits for most workloads.
The selected approach enables incremental updates while keeping infrastructure costs manageable at the petabyte scale. Spark jobs first deduplicate the latest changes from CDC tables and then apply updates or deletions to base tables. Historical data is loaded initially through a bootstrap pipeline, and ongoing maintenance jobs handle compaction and snapshot expiration.
Optimizations and Performance Gains
Optimizations include partitioning base tables by a hash of the primary key using Iceberg bucketing, allowing Spark to parallelize upserts and reduce data scanned per operation. The framework also addresses the small files problem by instructing Spark to distribute writes by partition, reducing overhead caused by multiple small files per task.
Measured outcomes include reducing data availability latency from more than 24 hours to as low as 15 minutes, processing only the 5% of records that change daily, and lowering infrastructure costs by avoiding unnecessary full-table operations. The system handles petabyte-scale data across thousands of pipelines while supporting incremental updates and deletions.
Pinterest's CDC-based ingestion framework delivers real-time access to database changes, with Iceberg tables on AWS S3 and Flink-Spark handling streaming and batch workloads. Future improvements will focus on automated schema evolution, safely propagating upstream changes downstream to enhance the reliability and maintainability of large-scale pipelines.
Technical Implementation Details
The CDC layer captures changes using Debezium for MySQL and TiCDC for TiDB, streaming events through Kafka topics. Flink processes these streams in real-time, applying transformations and deduplication before writing to staging tables. Spark then performs the Merge Into operations on Iceberg tables, leveraging the Merge on Read strategy for efficient updates.
For deletion support, the framework implements a tombstone mechanism where delete operations are recorded in CDC tables and propagated through the pipeline. This allows the system to maintain accurate historical snapshots while supporting point-in-time queries.
The configuration-driven approach uses YAML-based definitions that specify source tables, transformation rules, and target schemas. This enables rapid onboarding of new data sources without code changes, reducing the operational burden on engineering teams.
Business Impact and Use Cases
The reduced latency has enabled new real-time analytics capabilities, allowing product teams to make data-driven decisions based on current user behavior rather than stale information. Machine learning models can now be retrained more frequently with fresher data, improving prediction accuracy for recommendations and content personalization.
Operational efficiency has improved significantly, with data engineers spending less time maintaining pipelines and more time on value-added activities. The cost savings from processing only changed records rather than full table scans have been substantial, particularly for large tables with low change rates.
The framework has become a foundational component of Pinterest's data infrastructure, supporting thousands of pipelines across the organization and enabling new products and features that require real-time data access.
For more information about CDC and streaming architectures, see the Apache Kafka documentation and Debezium user guide.
Comments
Please log in or register to join the discussion