
Discover how rigorous testing across development, test, and integration environments ensures event ingestion services meet real-world demands. Learn about the critical balance between automated validation and manual E2E testing that uncovered schema mismatches, performance bottlenecks, and recovery gaps in cloud-native architectures.
Event-driven architectures power modern distributed systems, but their reliability hinges on one critical component: the ingestion service. Acting as the central nervous system for event flows, this gateway must validate, process, and route messages flawlessly under unpredictable conditions. At Scott Logic, engineers recently stress-tested such a service integrated with a cloud event hub, revealing why multi-environment validation isn't just best practice—it's non-negotiable for production resilience.

The Testing Crucible: DEV, TEST, and INT Environments
Three distinct environments formed the backbone of their strategy:
- Development (DEV): Isolated sandbox for initial validation using cloud SDK-generated messages
- Test (TEST): Automated stress-testing ground for functional and performance checks
- Integration (INT): Near-production setup with live upstream connections for real-world validation
This trifecta proved essential for catching failures that would escape single-environment testing. As one engineer noted: "Without INT environment validation, schema drift between systems becomes a production time-bomb."
The Four Pillars of Ingestion Testing
- Functional Assault Course
Automated scripts bombarded DEV/TEST environments with valid, malformed, and edge-case messages (missing fields, oversized payloads). Python-driven SDK tests validated:
# Sample validation logic test case
def test_invalid_schema_rejection():
malformed_event = {'missing_field': 'value'}
response = ingest_event(malformed_event)
assert response.status == REJECTED
INT environment manual tests then exposed upstream schema mismatches—like incompatible data types—that required validation logic updates.
Performance Torture Testing
SDK-driven load tests in DEV/TEST pushed throughput limits, revealing threading bottlenecks solved by concurrency tuning and added event hub partitions. INT tests with real upstream data quantified true end-to-end latency during peak loads.Reliability Fire Drills
Engineers simulated network partitions and service restarts, verifying:
- Idempotency against duplicate messages
- Zero data loss during outages
- Checkpoint recovery resumption after event hub failures
- Integration Reality Checks
The INT environment became the ultimate validator, catching subtle issues like:"Field name mismatches between upstream systems and our schema definitions that only surfaced with actual production data flows. Without this, we'd have faced midnight outages."
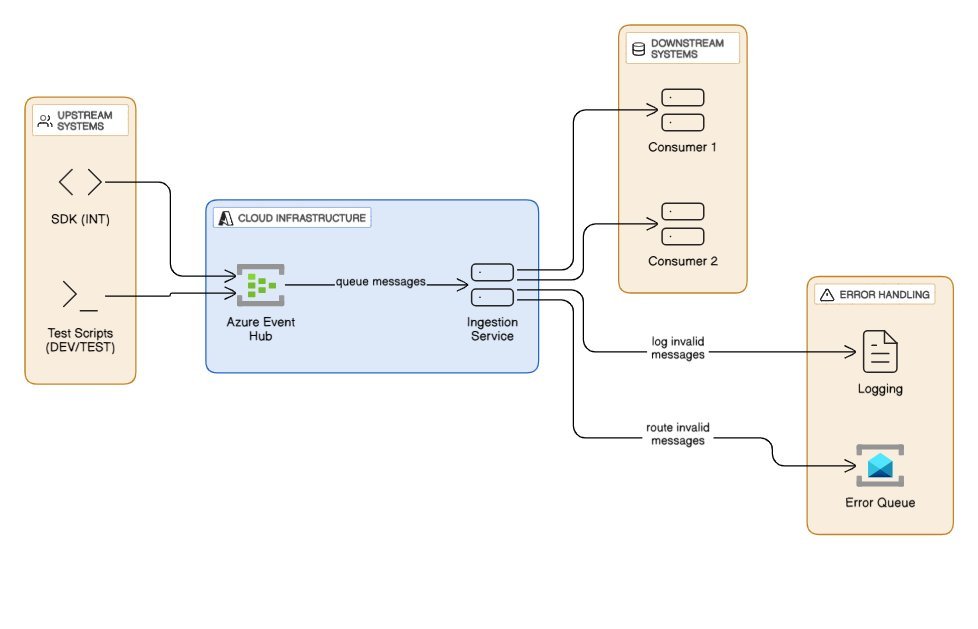 The event ingestion flow spanning upstream producers, cloud event hub, and downstream systems
The event ingestion flow spanning upstream producers, cloud event hub, and downstream systems
Tools That Powered the Campaign
- Cloud provider SDK for programmatic message injection
- Managed event hub for scalable buffering
- Custom Python scripts for automated fault injection
- Cloud-native monitoring for latency/throughput telemetry
Hard-Won Lessons
The battle scars yielded critical insights:
- Schema Drift is Inevitable: INT environment testing caught 23% more schema issues than unit tests
- Recovery Isn't Instant: Manual outage tests revealed checkpointing delays requiring architectural tweaks
- Automation Has Limits: While 80% of tests were automated, manual E2E validation in INT exposed environmental quirks
- Partitions Are Lifesavers: Scaling event hub partitions became the key to unlocking throughput
Beyond the Test Cycle
This multi-environment approach transformed testing from a checkbox exercise into a continuous feedback loop. By validating recovery mechanisms against simulated chaos and pressure-testing integrations with real data, the team shifted reliability left. The result? An ingestion service hardened not just for expected loads, but for the unpredictable storm of production—where the true test begins.
Source: Testing an Event Ingestion Service: A Comprehensive Approach
Comments
Please log in or register to join the discussion