Exploring the QuickHeap data structure that demonstrates 2-3x performance improvements over traditional binary and d-ary heaps through innovative layer-based organization and efficient partitioning strategies.
QuickHeap: A New Frontier in Priority Queue Performance
In the ever-evolving landscape of data structures, the quest for more efficient priority queues continues to drive innovation. Recent developments in heap implementations have yielded significant performance improvements, with the QuickHeap emerging as a particularly promising approach. This article delves into the architecture, implementation, and performance characteristics of QuickHeap, examining how it compares to traditional heap structures and when it might be the optimal choice for various applications.
The Evolution of Priority Queues
Priority queues form the backbone of numerous algorithms, from graph traversal to task scheduling. At their core, these data structures support two fundamental operations: Push (insert) and Pop (extract min). The efficiency of these operations directly impacts the performance of the algorithms that rely on them.
Traditional implementations have long been dominated by binary heaps, which organize elements in a complete binary tree structure stored as an array. This arrangement allows for O(log n) time complexity for both insertion and extraction operations. However, as data sizes grow, the memory access patterns of binary heaps can lead to suboptimal cache utilization, creating performance bottlenecks.
D-ary heaps represent an evolution of this concept, allowing each node to have up to d children rather than just two. This approach improves cache locality by reducing the height of the tree and concentrating elements in smaller memory regions. The trade-off comes from the increased cost of finding the minimum among d children during extraction operations.
Introducing QuickHeap: A Paradigm Shift
The QuickHeap, introduced by Navarro and Paredes in 2010, represents a fundamental departure from traditional heap organization. Rather than maintaining a complete binary or d-ary tree structure, QuickHeap organizes elements in layers separated by pivot values. This approach leverages insights from quicksort and incremental selection algorithms to create a more memory-efficient data structure.
 Figure 5: A schematic overview of the quickheap: elements are stored in layers. Deeper layers have smaller values, with each layer being at most its pivit. The bottom layer has at most 16 (here: 4) elements. Popping is done by scanning the bottom layer, and pushing is done by comparing the new value to all pilots and appending to the correct layer. To split a layer, a random pivot is selected as the median of 3 and smaller elements are pushed to the next layer, while larger elements stay. Values equal to the pivot are pushed down if they are on its left.
Figure 5: A schematic overview of the quickheap: elements are stored in layers. Deeper layers have smaller values, with each layer being at most its pivit. The bottom layer has at most 16 (here: 4) elements. Popping is done by scanning the bottom layer, and pushing is done by comparing the new value to all pilots and appending to the correct layer. To split a layer, a random pivot is selected as the median of 3 and smaller elements are pushed to the next layer, while larger elements stay. Values equal to the pivot are pushed down if they are on its left.
The core insight behind QuickHeap is that elements can be partitioned into layers where each layer contains elements that are all larger than the elements in the layer below. This is achieved by selecting pivot values that separate these layers. When inserting a new element, it's compared against these pivots to determine which layer it belongs to. When extracting the minimum, the algorithm simply scans the bottom layer for the smallest element.
The IncrementalQuickSelect Foundation
QuickHeap builds upon the IncrementalQuickSelect (IQS) algorithm developed by Paredes and Navarro in 2006. IQS was designed for the problem of incrementally retrieving the smallest k elements from a collection, which is closely related to the operations needed for a priority queue.
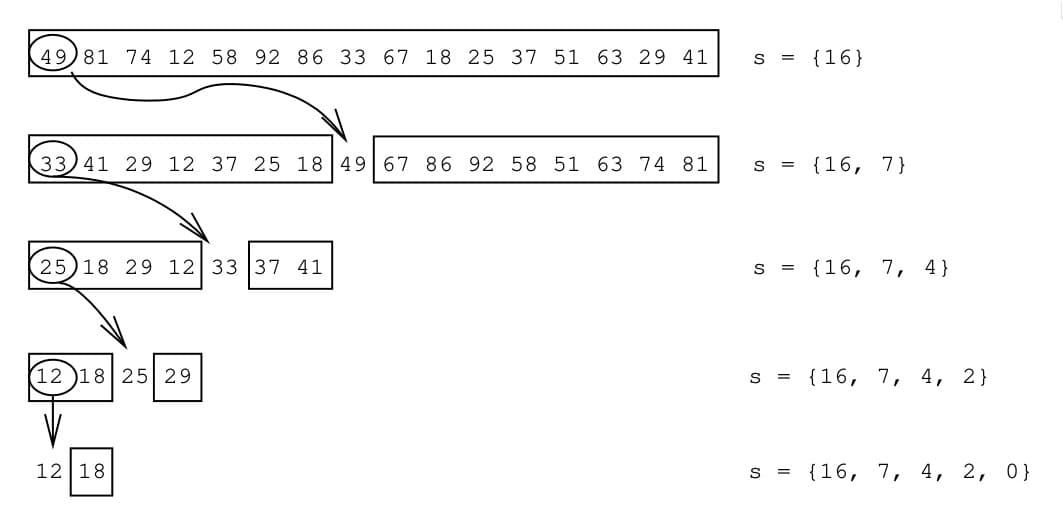
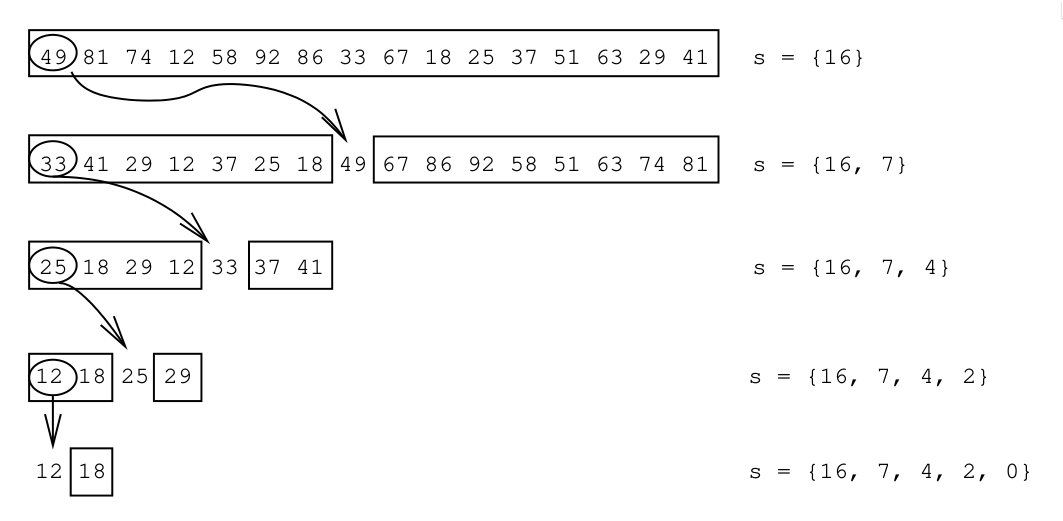 Figure 1: Example from Paredes and Navarro (2006) of the IQS method: a random (here: first) element is chosen as pivot to partition the array. This is repeated until only a single element is left, and the positions of all pivots are stored on a stack.
Figure 1: Example from Paredes and Navarro (2006) of the IQS method: a random (here: first) element is chosen as pivot to partition the array. This is repeated until only a single element is left, and the positions of all pivots are stored on a stack.
The IQS algorithm works by recursively partitioning the array around randomly selected pivots. Each partition step moves smaller elements to the left and larger elements to the right. The positions of these pivots are stored on a stack, allowing the algorithm to return to each partition point and continue processing the remaining elements as needed. This approach efficiently retrieves elements in sorted order without fully sorting the entire collection.
From IQS to QuickHeap
The transition from IQS to QuickHeap involves adapting this partitioning strategy to support the full set of priority queue operations. While IQS was designed for extracting elements in sorted order, a priority queue must also support efficient insertion of new elements.
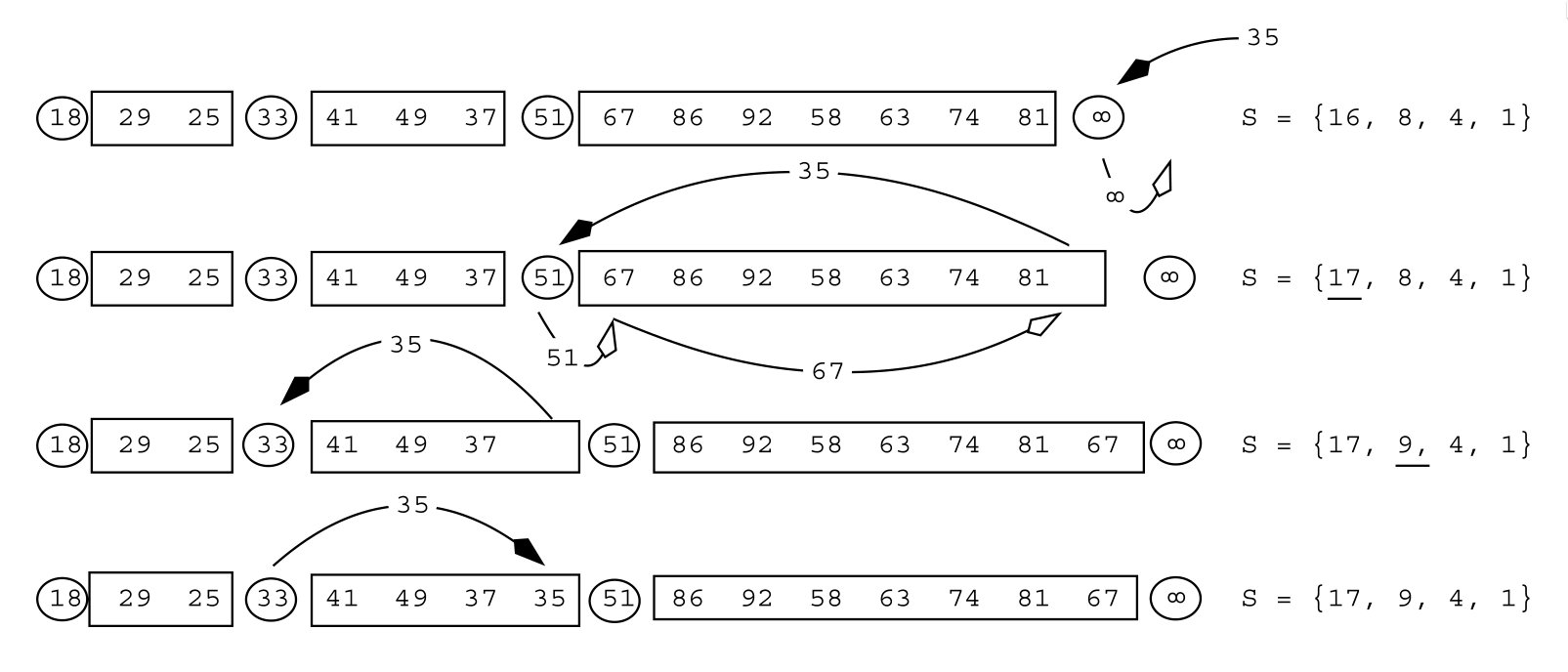 Figure 2: Example from Navarro and Paredes (2010) of inserting an element (35) into the quickheap.
Figure 2: Example from Navarro and Paredes (2010) of inserting an element (35) into the quickheap.
When inserting a new element into QuickHeap, the algorithm first appends it to the appropriate layer based on comparison with the layer pivots. If the new element is smaller than the current layer's pivot, it moves down to the next layer. This process continues until the element finds its correct position. The key innovation is that this insertion process maintains the layered structure without requiring the extensive restructuring that binary heaps need during insertion.
Addressing Worst-Case Behavior: Randomized QuickHeap
One limitation of the original QuickHeap implementation is its performance on certain input patterns. When elements are inserted in decreasing order, the number of layers can grow linearly with the number of elements, leading to O(n) insertion time in the worst case.
To address this issue, Randomized QuickHeap (RQH) was introduced in 2011. The key innovation in RQH is that whenever an element moves down one layer during insertion, there's a probability of 1/s that the entire subtree starting at that layer will be "flattened." This means all pivots in the subtree are dropped, and the next pop operation will select a new random pivot. This re-randomization ensures that each subtree is re-randomized approximately once each time it doubles in size, maintaining the expected logarithmic depth.
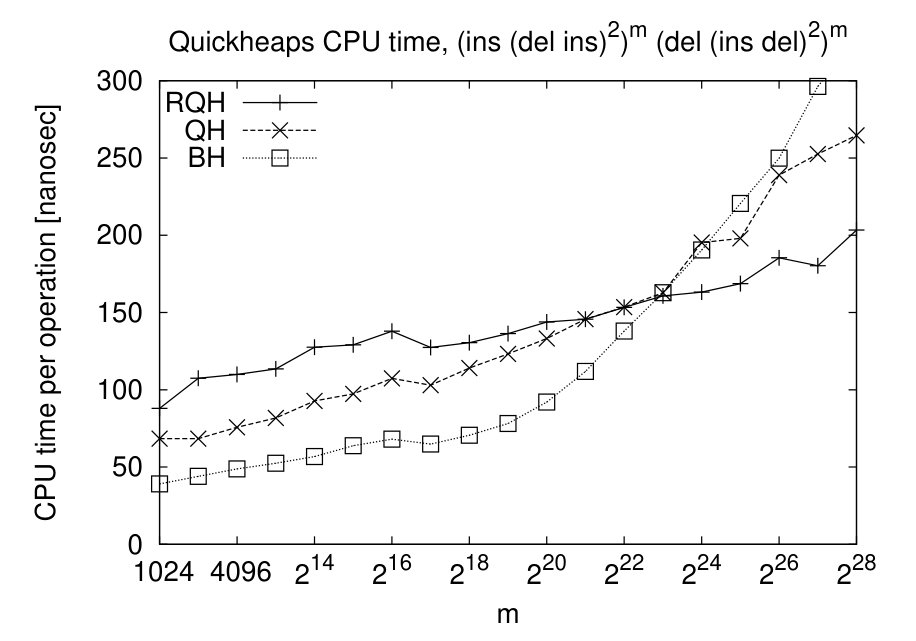 Figure 4: On a sequence of m times (ins, (del, ins)^2) followed by m times (del, (ins, del)^2), the random quickheap (RQH) is faster than both the binary heap (BH) and quickheap (QH) for sufficiently large inputs.
Figure 4: On a sequence of m times (ins, (del, ins)^2) followed by m times (del, (ins, del)^2), the random quickheap (RQH) is faster than both the binary heap (BH) and quickheap (QH) for sufficiently large inputs.
Implementation Details and Optimizations
The author's implementation of QuickHeap takes a slightly different approach from the original papers, using a bucket-based organization rather than storing everything in a flat array. Each layer is maintained as a separate bucket (vector), which simplifies the partitioning operations at the cost of slightly increased memory usage.
The data structure consists of three main components:
- A count of the number of layers
- A decreasing array of pivot values for all layers
- A vector of buckets, where each bucket contains elements for that layer
Push Operation
The push operation begins by comparing the new element against all pivots to determine the appropriate layer. This comparison can be efficiently parallelized using SIMD instructions. For u32 values, the author uses 8 lanes to compare against multiple pivots simultaneously.
One potential optimization mentioned is to transform this comparison into a 2-level B-tree structure, where a root node divides the levels into chunks of size L+1. This could further reduce the number of comparisons needed during insertion.
Pop Operation
The pop operation is more complex. It begins by checking if the current (bottom) layer contains more than 16 elements. If so, the layer is split by selecting a new pivot and partitioning the elements between this layer and the one below. Once the layer size is at most 16, the algorithm simply scans the elements to find and remove the minimum value.
After removing the minimum, the algorithm checks if the current layer has become empty. If so, it moves to the next higher layer for subsequent operations.
Partitioning Strategy
The partitioning operation is critical to QuickHeap's performance. The author's implementation uses the median of three candidate pivots to ensure balanced partitions. The actual partitioning is implemented using AVX2 SIMD instructions, drawing inspiration from Daniel Lemire's work on efficient partitioning algorithms.
The partitioning process works by selecting a pivot and then rearranging elements so that all elements smaller than the pivot are moved to the left, and all elements larger than the pivot are moved to the right. Elements equal to the pivot are handled based on their position relative to the pivot, with those on the left being moved down to the next layer.
Performance Analysis
To evaluate QuickHeap's performance, the author conducted extensive benchmarks against several heap and priority queue implementations. The test suite included:
- Standard library binary heap
- Two different d-ary heap implementations (tested with d=1,2,4,8)
- Radix heap (for comparison with specialized monotonic cases)
Test Methodology
The benchmarks were conducted on different data types (u32 and u64) and various access patterns:
- Heapsort pattern: n random pushes followed by n pops
- Random pattern: interleaved push and pop operations with random values
- Linear pattern: push operations with values in increasing order
- Increasing pattern: push operations where each new value is larger than the previous popped value by a random amount
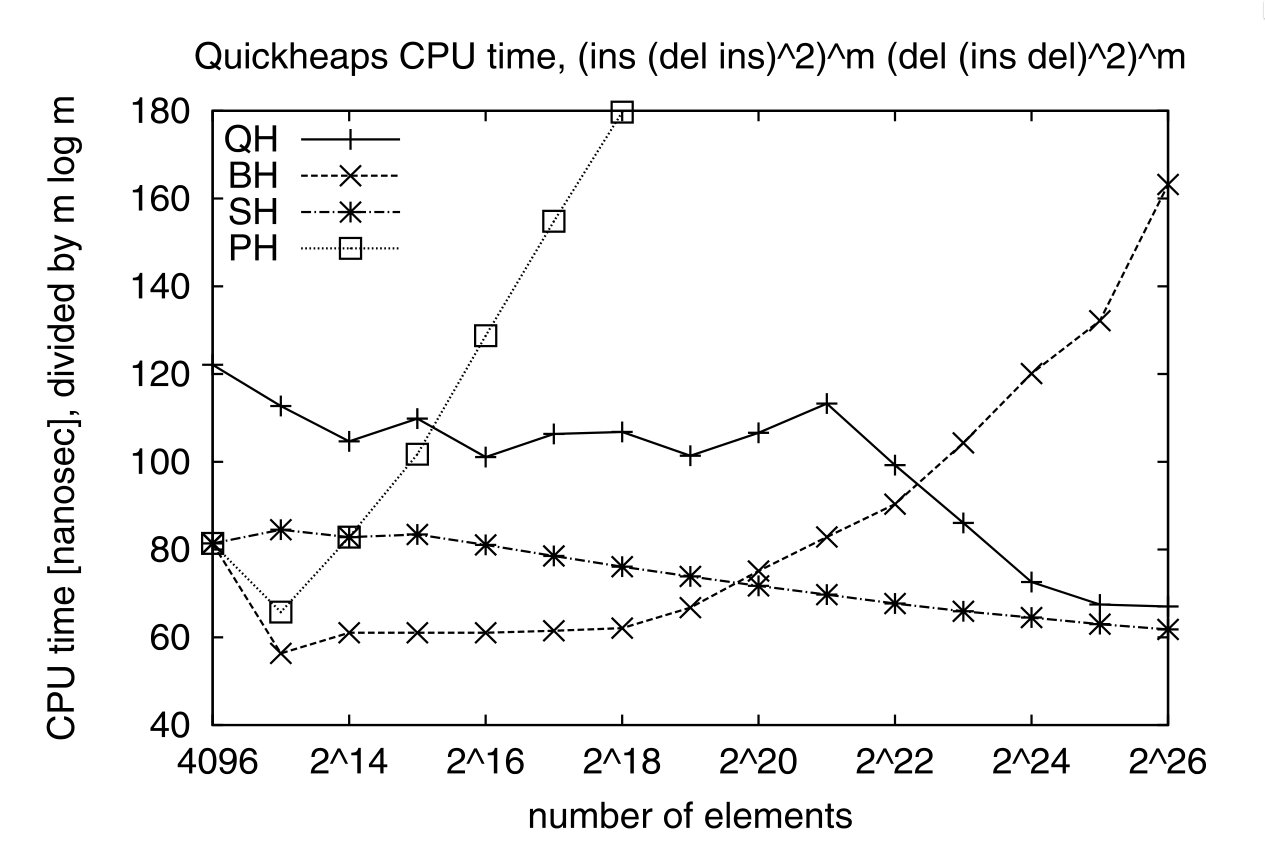 Figure 3: On a sequence of m times (ins, (del, ins)^2) followed by m times (del, (ins, del)^2), quickheap (QH) is faster than the binary heap (BH) and pairing heap (PH), but slightly slower than the sequence heap (SH), which are optimized for cases where all elements are extracted. Note that the y-axis reports the time divided by m lg(m).
Figure 3: On a sequence of m times (ins, (del, ins)^2) followed by m times (del, (ins, del)^2), quickheap (QH) is faster than the binary heap (BH) and pairing heap (PH), but slightly slower than the sequence heap (SH), which are optimized for cases where all elements are extracted. Note that the y-axis reports the time divided by m lg(m).
Key Findings
The benchmark results reveal several important insights:
QuickHeap consistently outperforms binary and d-ary heaps across most test cases, achieving 2-3x speed improvements for large datasets.
The performance advantage grows with dataset size, as QuickHeap's better cache efficiency becomes more pronounced.
For heapsort patterns, QuickHeap is up to 2x faster for u32 values, primarily because partitioning operations are more efficient for smaller data types.
For random interleaved operations, the performance difference narrows because approximately 75% of pushed elements are immediately popped again.
Linear insertion patterns represent the worst case for QuickHeap, as elements must sift down through the maximum number of layers.
Radix heap excels in specialized cases where keys are guaranteed to increase, but cannot handle arbitrary insertion patterns.
Practical Implications and Use Cases
The performance characteristics of QuickHeap make it particularly well-suited for certain applications:
Large-scale graph algorithms: Dijkstra's algorithm and other graph traversal methods that use priority queues can benefit significantly from QuickHeap's improved performance.
Real-time systems: The consistent performance characteristics of QuickHeap make it suitable for time-critical applications.
Memory-constrained environments: QuickHeap's efficient memory access pattern reduces cache misses, making it effective in systems with limited memory bandwidth.
Mixed workloads: Applications that involve both bulk operations and incremental processing can leverage QuickHeap's strengths in both scenarios.
However, there are cases where alternative heap structures might be preferable:
Monotonic key patterns: When keys are guaranteed to increase, radix heaps offer superior performance.
Small datasets: For very small collections, the overhead of QuickHeap's layered structure might not be justified.
Specialized operations: If applications require operations beyond push and pop (such as decrease-key), other heap structures might be more appropriate.
Future Directions
The field of priority queue research continues to evolve. The author mentions ongoing work on SimdQuickHeap, which further optimizes the implementation using SIMD instructions. The preprint "SimdQuickHeap: The QuickHeap Reconsidered" by Breitling, Groot Koerkamp, and Williams (2026) presents additional improvements and refinements to the original QuickHeap concept.
Other areas of potential development include:
Parallel implementations: Leveraging multi-core architectures to further improve performance.
Persistent variants: Implementations that support versioning and historical queries.
Distributed versions: QuickHeap adaptations for distributed computing environments.
Hybrid approaches: Combining QuickHeap with other heap structures to optimize for specific access patterns.
Conclusion
QuickHeap represents a significant advancement in priority queue design, offering substantial performance improvements over traditional binary and d-ary heaps. Its innovative layered organization, combined with efficient partitioning strategies, addresses fundamental limitations of conventional heap structures, particularly in terms of cache efficiency.
The benchmark results clearly demonstrate that QuickHeap is not just a theoretical improvement but a practical solution that can deliver 2-3x performance gains in real-world applications. While it may not be optimal for all use cases, it represents an important addition to the data structure toolbox, particularly for large-scale applications where performance is critical.
As we continue to push the boundaries of what's possible with algorithmic efficiency, innovations like QuickHeap remind us that even fundamental data structures can be reimagined and improved. The ongoing research in this area promises to yield further enhancements, ensuring that priority queues continue to evolve to meet the growing demands of modern computing applications.
For those interested in implementing QuickHeap, the author's implementation is available on GitHub, and the latest research results can be found in the SimdQuickHeap paper on arXiv.
Comments
Please log in or register to join the discussion