A small RAG chunker bug shows why enterprises should treat ingestion logic as a governed cloud platform decision, especially when moving between AWS, Azure, and Google managed AI stacks.
What changed
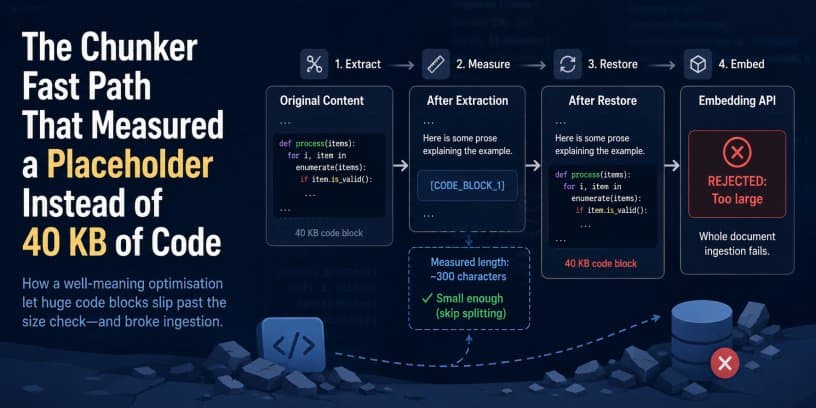
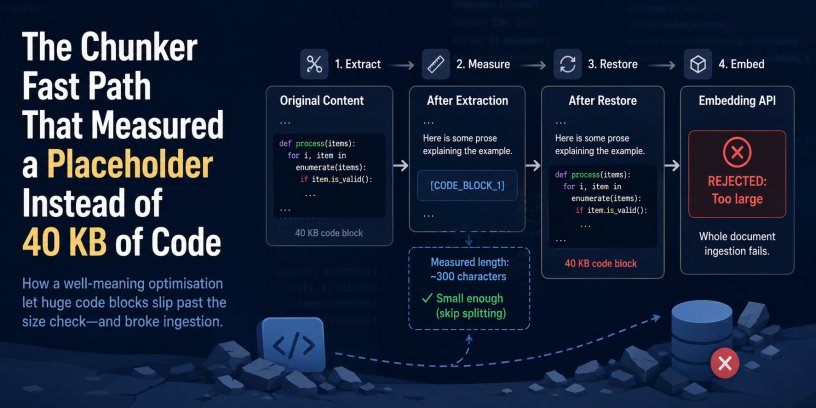
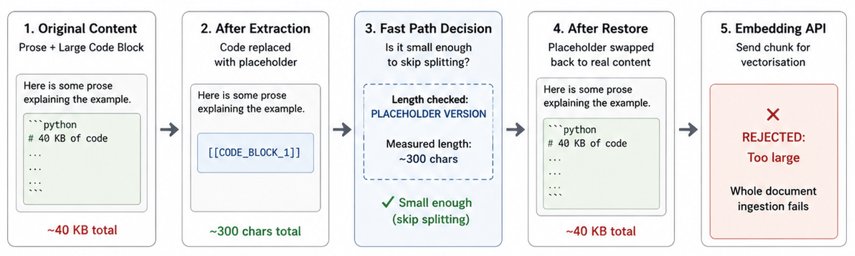
Jamie Maguire’s write-up on a RAG chunker fast path bug looks at first like a local implementation defect: a pipeline replaced large fenced code blocks with short placeholders, measured the placeholder text, decided the document was small enough, then restored the real 40 KB code block before calling the embedding API. The result was predictable but easy to miss in production. Small pages with a little prose and a large code sample became oversized chunks, and those chunks failed during vectorisation.
The business lesson is broader than the bug. RAG ingestion is no longer just application plumbing. It is now part of the cloud architecture contract. The chunker decides what gets embedded, what gets dropped, what costs money, what can be cited, and what fails during migration. A bad length check can turn a technically valid document into an ingestion outage. A poor token estimate can make spend forecasts inaccurate. A provider default can change retrieval quality without any change to the source content.
The specific failure had three parts. First, the fast path measured a stand-in, not the restored text that would actually be sent to the model. Second, the rule to preserve code blocks had no upper bound. Preserving a code block is sensible until the block is larger than the model input budget. Third, the pipeline used the common four characters per token estimate, which works better for prose than for code, XML, JSON, YAML, or Markdown-heavy documentation. Code has dense punctuation, short identifiers, braces, indentation, and separators, so token counts can rise faster than character counts imply.
In a single-cloud prototype, this can be fixed with tests and better guardrails. In an enterprise RAG estate, the decision is more strategic. Teams need to decide whether chunking remains custom code, moves into a managed platform, or is split between a cloud-native ingestion service and application-owned preprocessing. That choice affects cost, portability, auditability, search quality, and operational support.
Provider comparison
AWS, Microsoft Azure, and Google Cloud all provide managed building blocks for RAG, but they draw the boundary between provider responsibility and customer responsibility differently. That boundary matters when the issue is not embedding quality, but the validity of the text sent into the embedding model.
AWS Bedrock Knowledge Bases is the most integrated option if the organisation already wants Bedrock as the control plane. AWS describes Knowledge Bases as a managed RAG capability that handles ingestion, chunking, embedding, vector store integration, retrieval, prompt augmentation, and source attribution. It supports multiple vector stores, including Amazon OpenSearch Serverless, Aurora, Neptune Analytics, MongoDB, Pinecone, and Redis Enterprise Cloud. That gives AWS an advantage for teams that want managed ingestion but do not want a single vector database imposed on them.
AWS also exposes several chunking modes through Knowledge Bases chunking documentation, including default, fixed-size, hierarchical, semantic, and multimodal-related behaviour. Fixed-size chunking lets teams set a token budget and overlap. Default chunking splits to roughly 300 tokens while preserving sentence boundaries. Semantic chunking can improve retrieval quality but adds foundation model cost. For a documentation-heavy corpus, that menu is useful because API references, tutorials, release notes, and architecture diagrams do not behave like the same document type.
The AWS risk is that managed abstraction can hide the exact transformation path unless teams explicitly inspect outputs. If a company has strict requirements for preserving code examples, maintaining page-level citations, or applying language-specific parsing rules, it still needs ingestion evaluation. Amazon Titan Text Embeddings V2 accepts up to 8,192 tokens or 50,000 characters according to the AWS model documentation, but that does not mean 50,000 characters is a good chunk size for retrieval. It only means the model can accept it. Good retrieval often needs smaller logical sections.
Azure takes a more composable route. Azure AI Search vector search can store and query vector fields, run hybrid keyword and vector search, apply filters, and integrate with Azure OpenAI and other Azure data sources. Microsoft’s documentation says vector search itself is available across tiers without an extra vector-search charge, although embedding generation and AI enrichment can incur model-provider charges. That distinction matters for pricing models. Azure Search capacity, replicas, partitions, and storage are one cost layer. Azure OpenAI embeddings are another.
Azure also provides explicit guidance for chunking large documents for RAG. The guidance calls out model token limits, integrated vectorisation, text split skills, overlap, fixed and variable chunking, semantic chunking, and custom skills. The text-embedding-3-small example is listed at 8,191 tokens in that chunking guidance, while the Azure model catalog lists text-embedding-3-small and text-embedding-3-large with 8,192-token maximum requests in the Foundry model documentation. The practical reading is simple: keep a safety margin. Do not design chunkers that depend on landing exactly on the published ceiling.
Azure is attractive for enterprises with existing Microsoft data gravity: Blob Storage, OneLake, Cosmos DB, SQL, Microsoft 365-adjacent workflows, and Azure governance. It is also a strong fit where hybrid search matters. Many internal knowledge systems need keyword precision for identifiers, product codes, method names, policy numbers, and error strings. Pure vector retrieval often underperforms on those. The trade-off is assembly complexity. Azure gives architects fine control, but teams must own more of the pipeline contract: indexing schema, chunk metadata, skillsets, vector dimensions, source refresh, and failure handling.
Google Cloud’s current RAG direction is centred on Gemini Enterprise Agent Platform and RAG Engine. Google describes RAG Engine as a framework for ingestion, transformation, embedding, indexing, retrieval, and generation. It supports corpus management, Google data sources such as Cloud Storage and Google Drive, metadata filtering, reranking, and multiple vector database choices. The documentation also makes some platform constraints explicit, including region availability, allowlist status in some US regions, CMEK support, VPC-SC support, and billing for a RAG Engine-managed Spanner instance in supported managed modes.
Google’s embedding model details are especially relevant to this bug class. The Gemini text embeddings documentation lists gemini-embedding-001 at 3,072 dimensions by default, with a 2,048-token max sequence length in the model table. The same page explains API request limits and notes truncation behaviour controlled by autoTruncate. That is an architectural decision point. Silent truncation can protect an ingestion job from failing, but it can also index incomplete content. For compliance, support knowledge bases, developer documentation, and policy retrieval, silent loss may be worse than a visible failure.
Google pricing also uses a different shape in places. The Agent Platform pricing page lists Gemini Embedding input at $0.00015 per 1,000 input tokens for online requests and $0.00012 for batch requests, while older text embedding pricing is character-based. That difference makes migration planning more than a rate-card comparison. If a corpus is code-heavy, token-based billing can expose density that character-based estimation hides. If a corpus is prose-heavy, the economics may look different.
Pricing and migration considerations
The tempting response to the Jamie Maguire bug is to say: use managed RAG and avoid custom parser defects. That is only partly true. Managed services reduce the amount of code your team maintains, but they do not remove the need for ingestion acceptance tests. The key question is not whether a provider can chunk documents. They all can. The question is whether the provider chunks your documents in a way that matches your retrieval, cost, citation, and failure semantics.
Start migration planning with a document test pack, not a provider feature matrix. Include the awkward files: short pages with giant code blocks, Markdown with nested fences, generated API references, XML configuration, JSON schemas, Terraform modules, Kubernetes manifests, notebooks, PDFs with tables, and pages that mix prose with logs. For each provider, measure chunk count, max token count, average token count, overlap, citation fidelity, metadata retention, ingestion failure mode, and retrieval quality for known queries.
For AWS, test whether built-in chunking modes preserve the sections your users search for. Hierarchical chunking can be useful when users ask broad questions but still need precise snippets. Semantic chunking can improve boundaries, but it adds model cost and may create larger chunks than expected. If the team uses Bedrock Knowledge Bases with a non-AWS vector store such as Pinecone or Redis Enterprise Cloud, include network path, security review, data residency, and operational ownership in the design. The model call, vector write, and retrieval path may cross more boundaries than the architecture diagram initially suggests.
For Azure, model the end-to-end cost as Search plus embeddings plus enrichment plus storage growth. Reducing embedding dimensions for text-embedding-3-large or choosing text-embedding-3-small can lower vector storage and query compute pressure, but it may alter retrieval quality. Azure’s composable design is useful when an organisation needs custom skills, private indexing flows, and hybrid retrieval. It also means migration teams should document who owns the chunking code or skillset and how it is versioned.
For Google Cloud, pay close attention to region support, managed database mode, truncation configuration, and whether the embedding model’s 2,048-token sequence length fits the corpus strategy. Smaller chunk limits are not automatically bad. They can improve retrieval precision and reduce wasted context. They do, however, increase chunk counts, index size, and metadata volume. If a team migrates from an 8,192-token embedding budget to a 2,048-token budget, it should expect different overlap settings, more chunks, and a fresh retrieval evaluation.

The hardest migration issue is embedding incompatibility. Vectors from different models are not interchangeable. Moving from Amazon Titan to Azure OpenAI embeddings, or from Azure embeddings to Gemini embeddings, requires re-embedding the corpus and usually rebuilding the index. Even switching between embedding models on the same provider can require regeneration. Azure’s documentation is direct on this point for moving from text-embedding-ada-002 to text-embedding-3-large: teams need to generate new embeddings. That means migration windows must account for ingestion throughput, model rate limits, batch pricing, rollback strategy, and dual-running if production search cannot pause.
There is also a governance angle. Chunking logic should be treated as versioned production behaviour. Store the chunker version, embedding model, vector dimensions, tokenizer assumptions, source document hash, parser mode, and timestamp with every chunk. When retrieval quality changes, this metadata is how teams distinguish a content change from a pipeline change. Without it, cloud migration becomes forensic guesswork.
Business impact
This class of bug changes how executives should evaluate RAG platform maturity. The issue is not that one oversized chunk failed. The issue is that a pipeline made a business decision using the wrong measurement. It measured the placeholder, not the content sent to the paid provider API. In cloud terms, that is a control failure. The same pattern appears in cost estimation, security filtering, data residency tagging, document classification, and retention rules. Any time a system substitutes a cheaper representation for the real payload, the architecture needs a check that decisions still apply to the restored artifact.
For CIOs and platform leaders, the recommendation is to separate three responsibilities. Application teams should own domain-specific parsing rules because they know whether a code block, legal clause, table, or diagram must remain intact. Platform teams should own shared ingestion controls: token counting, maximum payload enforcement, retry behaviour, dead-letter queues, observability, and cost attribution. Cloud providers should be used for managed primitives where they reduce operational load: embeddings, vector indexing, managed retrieval, reranking, security integration, and scalable batch processing.
The better operating model is not fully custom or fully managed. It is policy-driven ingestion with provider-aware adapters. Define rules once: measure the restored content, cap atomic sections, use token-aware counting for code-heavy content, reject or split oversized chunks before the embedding call, and record the transformation metadata. Then implement those rules against AWS, Azure, or Google depending on workload placement.
For a multi-cloud enterprise, provider choice should follow the data and operating model. Choose AWS Bedrock Knowledge Bases when Bedrock is already the AI control plane, S3 is the primary corpus source, and the team wants managed RAG with several vector store options. Choose Azure AI Search with Azure OpenAI when Microsoft data integration, hybrid search, and index control are more important than a single managed RAG abstraction. Choose Google RAG Engine when Gemini agent workflows, Google data sources, and managed corpus tooling fit the platform direction, while validating region and token-limit constraints early.
The Jamie Maguire incident is a reminder that RAG quality is decided before the model responds. It is decided when the source document is parsed, when placeholders are inserted, when length is measured, when code is split or preserved, when truncation is allowed, and when metadata is attached. Cloud providers can manage more of that workflow than they could a few years ago, but they cannot infer every enterprise rule from a PDF or Markdown page.
The practical next step is an ingestion review. Pull the top failing documents, the largest documents, and the smallest documents with the largest embedded artifacts. Run them through the current pipeline and at least one managed provider path. Compare not only whether ingestion succeeds, but what the index actually contains. If the indexed chunks do not match what a human would expect to retrieve, the cloud architecture is not ready for production scale, no matter how strong the embedding model looks on a benchmark.
Comments
Please log in or register to join the discussion