A new Linux software RAID patch targets the hot parity path, giving Zen 5 a measurable win where homelab builders actually feel it: RAID5 and RAID6 rebuilds, checks, and parity-heavy writes.
{{IMAGE:2}}
Product
Eric Biggers has posted an AVX-512 optimized xor_gen() implementation for the Linux kernel software RAID path, aimed at speeding up parity generation and validation for RAID5 and RAID6 arrays. The short version for builders: this is not a new RAID feature, a new mdadm mode, or a filesystem tweak. It is a lower-level CPU implementation change inside the Linux kernel that makes an existing operation faster on CPUs with the right vector hardware.
The relevant component is Linux MD RAID, documented in the kernel's RAID administration guide, with userspace management typically handled through mdadm. RAID5 and RAID6 rely on parity math. Every time the array needs to generate parity, validate parity, reconstruct missing data, or perform certain reshape and scrub operations, the CPU spends time XORing blocks together. xor_gen() is one of those unglamorous functions that rarely appears on a box label, yet can become painfully visible during rebuilds, consistency checks, and write-heavy parity workloads.
The patch adds an AVX-512 version using 512-bit ZMM registers. It also uses vpternlogq where applicable, which matters because ternary logic can combine three input operands in one vector instruction. For RAID parity, that is useful because the work is fundamentally about combining multiple block streams. The more data each instruction can process, and the fewer passes required over cache lines, the less time the CPU spends grinding through parity.
This is exactly the kind of optimization that looks small in a changelog and large on a watt meter when the array is busy. A six-drive RAID6 media pool doing light sequential reads may not care. A parity array backed by fast NVMe, a rebuild after a disk swap, or a nightly check run on a homelab server absolutely can.
Relevant upstream code areas include the kernel's MD RAID implementation under drivers/md and the x86 XOR routines under arch/x86. For instruction-set background, Intel documents AVX-512 in its architecture instruction set extensions reference, while AMD's Zen 4 and Zen 5 support makes this especially interesting for consumer AM5 and workstation builds.
Performance Data
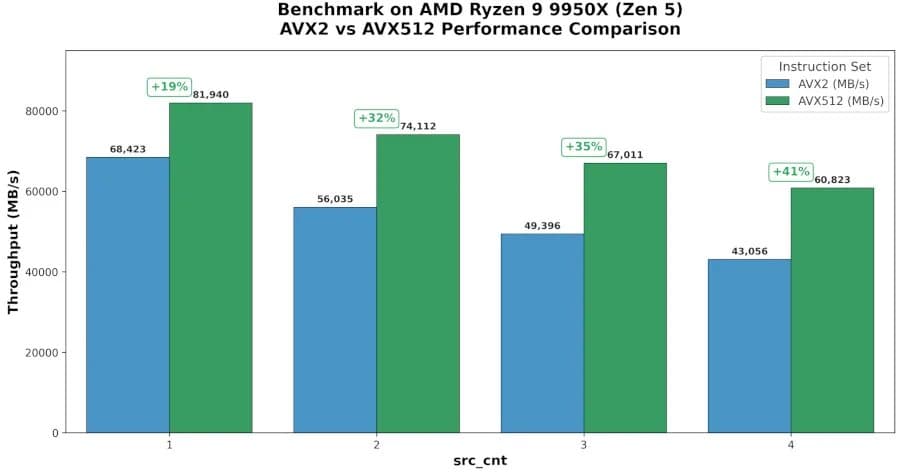
Phoronix reports testing on an AMD Ryzen 9 9950X, a Zen 5 desktop CPU, with improvements ranging from 19% to 41% for the optimized RAID XOR path. That is a large spread, but it makes sense. XOR throughput is sensitive to block size, memory bandwidth, cache residency, number of source operands, and whether the storage stack above it is fast enough to expose CPU-side parity cost.
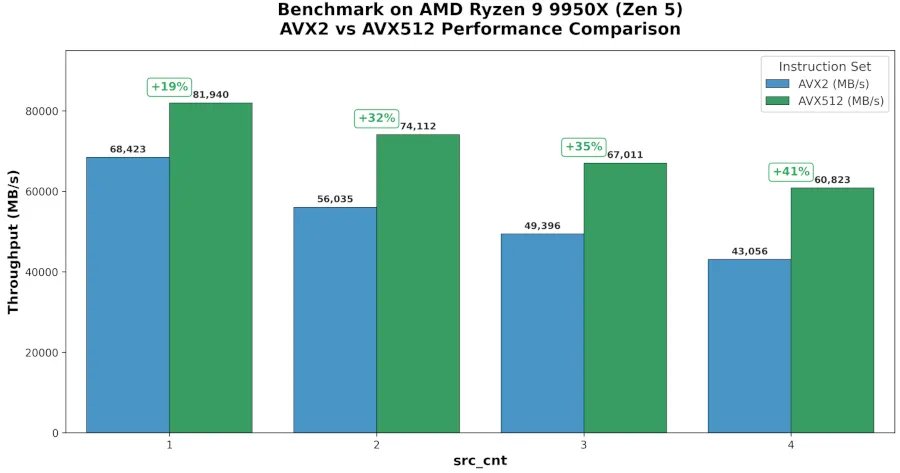
| Test Context | Reported Result | Builder Interpretation |
|---|---|---|
Linux RAID xor_gen() with AVX-512 on Ryzen 9 9950X |
+19% to +41% | Best case is parity math moving enough data to benefit from 512-bit vectors |
| RAID5 or RAID6 parity generation | Directly relevant | Writes, rebuilds, checks, and recovery paths can benefit |
| Simple RAID1 mirroring | Not the target | Mirroring copies data rather than calculating distributed parity |
| RAID0 striping | Not the target | No parity, no XOR parity generation bottleneck |
| Hardware RAID controller | Usually not relevant | Controller firmware and ASICs handle parity outside Linux MD |
The important detail is where this speedup sits. It does not make a hard drive seek faster. It does not fix SMR drive write stalls. It does not turn a 1 GbE NAS into a 25 GbE storage server. It accelerates parity calculation in the kernel when the CPU is on the critical path.
That distinction matters for real builds. On a small SATA HDD RAID6 array, disk latency and sequential drive throughput often dominate. On a mixed-use home server with NVMe cache, SSD arrays, fast networking, or rebuilds across many disks, parity math becomes more visible. A Ryzen 9 9950X has enough memory bandwidth and core frequency that AVX-512 can show a clean gain in microbenchmarks and parity-heavy paths.
The vpternlogq angle is also more than trivia. A normal XOR chain over three inputs can require multiple operations, for example A xor B, then result xor C. Ternary logic can express the three-input operation directly. In a parity routine that repeatedly combines source blocks, shaving instructions and improving vector width both count. It is not glamorous, but neither is waiting 14 hours for a rebuild that could have finished sooner.
Power Consumption And Thermals
AVX-512 always deserves a power discussion. Wide vector instructions can increase instantaneous package power, and some older Intel AVX-512 implementations were notorious for frequency drops when ZMM registers entered the chat. Biggers' patch reportedly follows the same policy used by other Linux crypto and CRC code: enable the ZMM implementation only on x86_64 CPUs with AVX512F and without PREFER_YMM.
That compatibility gate is doing real work. It avoids older AVX-512 implementations such as Intel Skylake Server and Ice Lake where heavy 512-bit vector use can be a poor trade for general system throughput. The target list is much cleaner:
| CPU Family | Expected Status | Practical Note |
|---|---|---|
| AMD Zen 4 and newer | Supported by policy | Good fit for Ryzen 7000, EPYC Genoa/Bergamo, Threadripper 7000, and newer |
| AMD Zen 5 | Supported by policy | Ryzen 9000 and EPYC Turin class systems are the obvious winners |
| Intel Sapphire Rapids and newer server CPUs | Supported by policy | Relevant for Xeon homelabs and small storage servers |
| Intel Rocket Lake client CPUs | Supported by policy | Narrower client-side case, but technically interesting |
| Intel Nova Lake and newer client CPUs | Supported by policy | Future client platform target |
| Intel Skylake Server and Ice Lake | Excluded by policy | Avoids known ZMM downclock behavior |
For power measurement, I would not assume lower watts just because the operation completes faster. The better metric is joules per completed parity job. A RAID check that pulls 120 W package power for 20 minutes can still beat 85 W for 35 minutes. Homelab power math should be measured at the wall with the array under a repeatable workload.
A useful test plan after this lands in a distro kernel would look like this:
| Measurement | Tooling | What To Watch |
|---|---|---|
| Array check duration | /sys/block/mdX/md/sync_action plus timestamps |
Total wall-clock time for check or repair |
| CPU package power | RAPL via perf, turbostat, or board telemetry |
Package watts during parity-heavy work |
| Wall power | Smart plug or UPS telemetry | Whole-system energy cost, including drives |
| CPU frequency | turbostat or watch grep MHz /proc/cpuinfo |
Any sustained AVX-related clock behavior |
| Storage saturation | iostat -x 1 |
Whether disks or CPU are the current limit |
| Thermals | sensors |
Whether the NAS chassis can exhaust AVX load heat |
For a 9950X NAS, I would treat this as a performance gain that may need sane platform limits. Eco Mode, a PPT cap, or a tuned fan curve can make sense if the box sits in a closet and runs parity checks overnight. Zen 4 and Zen 5 AVX-512 support is much friendlier than the bad old Intel downclock stories, but 512-bit integer work still consumes power. Measure it.
Compatibility
This patch is for Linux software RAID. If your array is managed by mdadm and appears as /dev/md0, /dev/md1, or similar, you are in the right neighborhood. If you are using ZFS RAIDZ, Btrfs RAID profiles, Windows Storage Spaces, or a hardware RAID card, this particular kernel MD optimization is not your direct fast path.
RAID levels matter too. RAID5 and RAID6 are the interesting cases because parity must be generated and checked. RAID1 is dominated by duplicated writes and reads from mirrors. RAID10 is usually a better low-latency choice for VM storage, but it does not use the same distributed parity math.
Kernel availability is the remaining caveat. The patch is newly posted as of June 12, 2026, so builders should treat it as pending until it appears in a released mainline kernel or in a distro backport. For production storage, do not run a random kernel build only because one microbenchmark looks good. Wait for review, run checks, validate your backups, then test on noncritical data first.
Build Recommendations
For a homelab builder, the best fit is a Linux MD RAID5 or RAID6 box where the CPU is modern, the disks are fast enough to expose parity cost, and the workload includes rebuilds, checks, large sequential writes, or parity-heavy maintenance.
| Build Type | Recommendation |
|---|---|
| Budget SATA HDD NAS | Nice to have, not a reason to rebuild the system |
| 6 to 10 disk RAID6 archive server | Useful during checks, rebuilds, and large writes |
| All-SATA SSD RAID5 | More likely to expose CPU parity limits |
| NVMe MD RAID5 or RAID6 | Strong candidate for visible improvement |
| VM datastore | Prefer RAID10 unless capacity efficiency is the main goal |
| Production data | Wait for mainline or distro kernel support, then test |
If I were building around this, I would pair a Ryzen 9 9950X or lower-power Zen 5 chip with ECC-capable board support where available, enough airflow over the drives, and a UPS. I would also avoid pretending parity RAID is a backup. RAID6 protects availability through drive failure. It does not protect against deletion, corruption, ransomware, bad firmware, or a user with rm -rf and confidence.
For software tuning, start with boring correctness before chasing throughput. Confirm array health through /proc/mdstat, schedule regular scrubs, monitor SMART data, and keep mdadm email or alerting configured. Then benchmark with real workloads. fio, iostat, perf, and wall-power logging will tell you more than a forum screenshot.
The wider pattern is that Linux keeps getting faster in the places storage builders used to ignore. Crypto, CRC, checksums, parity, and copy routines all sit below the filesystem glamour layer, yet they define how much useful work a server can do per watt. This AVX-512 RAID patch is another example: not a headline feature in mdadm, not a new filesystem, just a hot loop getting wider, cleaner, and measurably faster on the CPUs many homelab builders are already buying.
Comments
Please log in or register to join the discussion