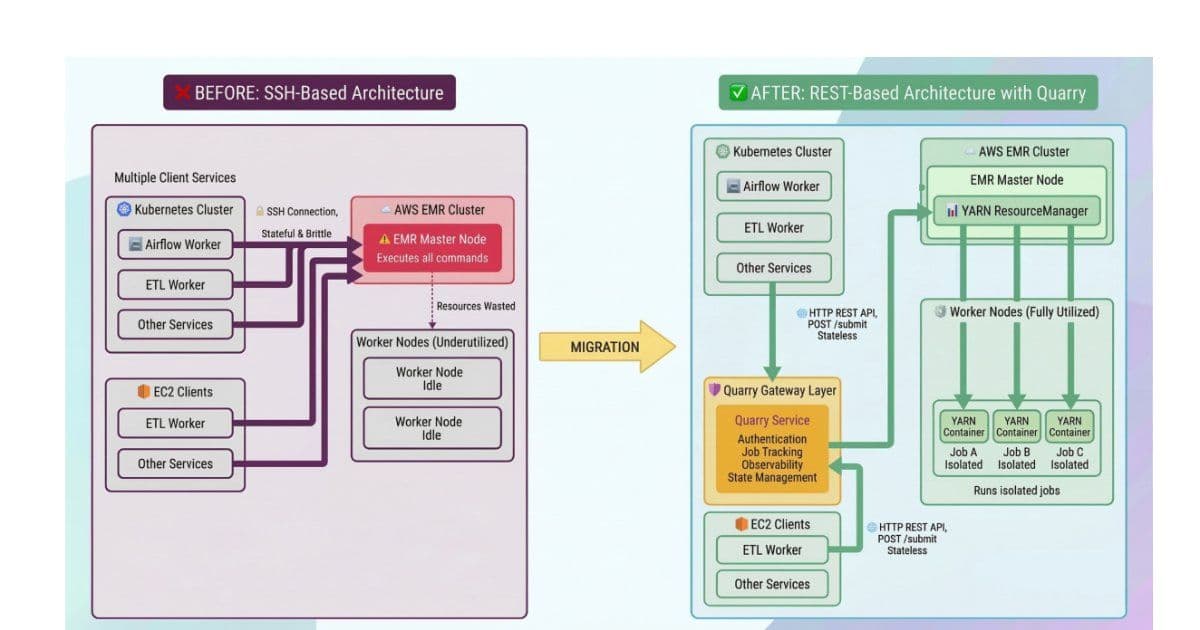
Slack spent three quarters replacing direct SSH access to its Amazon EMR clusters with a REST-based job submission system called Quarry, moving more than 700 Airflow operators across eight data regions. The change closed a real attack surface and fixed a class of silent job failures, but the migration surfaced hidden network and resource-limit dependencies that SSH had been quietly papering over.
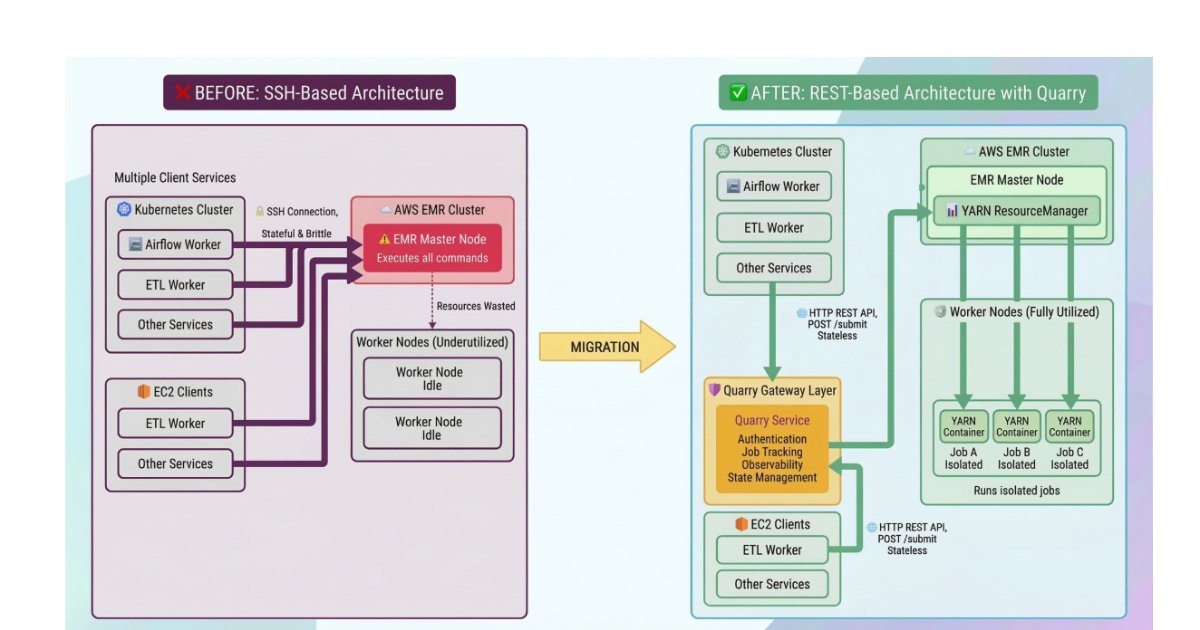
SSH is the path of least resistance when you need one machine to run a job on another. It is already installed, it authenticates, and it gives you a shell. That convenience is exactly why it tends to metastasize inside data platforms until someone realizes that hundreds of production workflows depend on opening interactive connections to cluster master nodes. Slack reached that point, and over roughly three quarters it migrated more than 700 Airflow operators off SSH-based execution and onto a REST-driven orchestration layer across its Amazon EMR pipelines, spanning eight data regions. The work removed direct SSH access to production clusters entirely.
The problem with shelling into production
Slack's data platform ran Airflow operators that executed jobs by opening SSH connections straight to EMR master nodes. For a handful of pipelines this is fine. By 2024 it was the default execution path for hundreds of production workflows, including search indexing and analytics jobs, and the costs of that default had compounded.
The security problem is the obvious one. Every workflow that can SSH into a production master node is a workflow that holds, distributes, and must rotate keys against live infrastructure. The attack surface is wide by construction, and auditing what actually ran meant stitching together logs from several systems after the fact, because the execution context lived inside an ephemeral shell session rather than in any durable record.
The reliability problem is subtler and, for anyone who has operated this kind of system, more familiar. SSH couples the lifecycle of a remote job to the lifecycle of a TCP connection. When the connection drops, you are left in an ambiguous state. The job may have kept running on the cluster with nobody watching it, or it may have died in a way the client never observed. Slack saw both: jobs that continued after a dropped connection and jobs that failed silently under infrastructure instability. Neither produces a clean signal that an orchestrator can act on, which means retries, alerting, and idempotency all become guesswork.
Quarry and the move to server-side lifecycles
The replacement is an internal orchestration layer Slack calls Quarry. Instead of holding a persistent SSH session open for the duration of a job, Airflow now submits work through HTTP APIs. Each job gets a server-side lifecycle: it is submitted, it is tracked by a job ID, and it can be cancelled through a controlled path rather than by killing a connection and hoping the process dies with it.
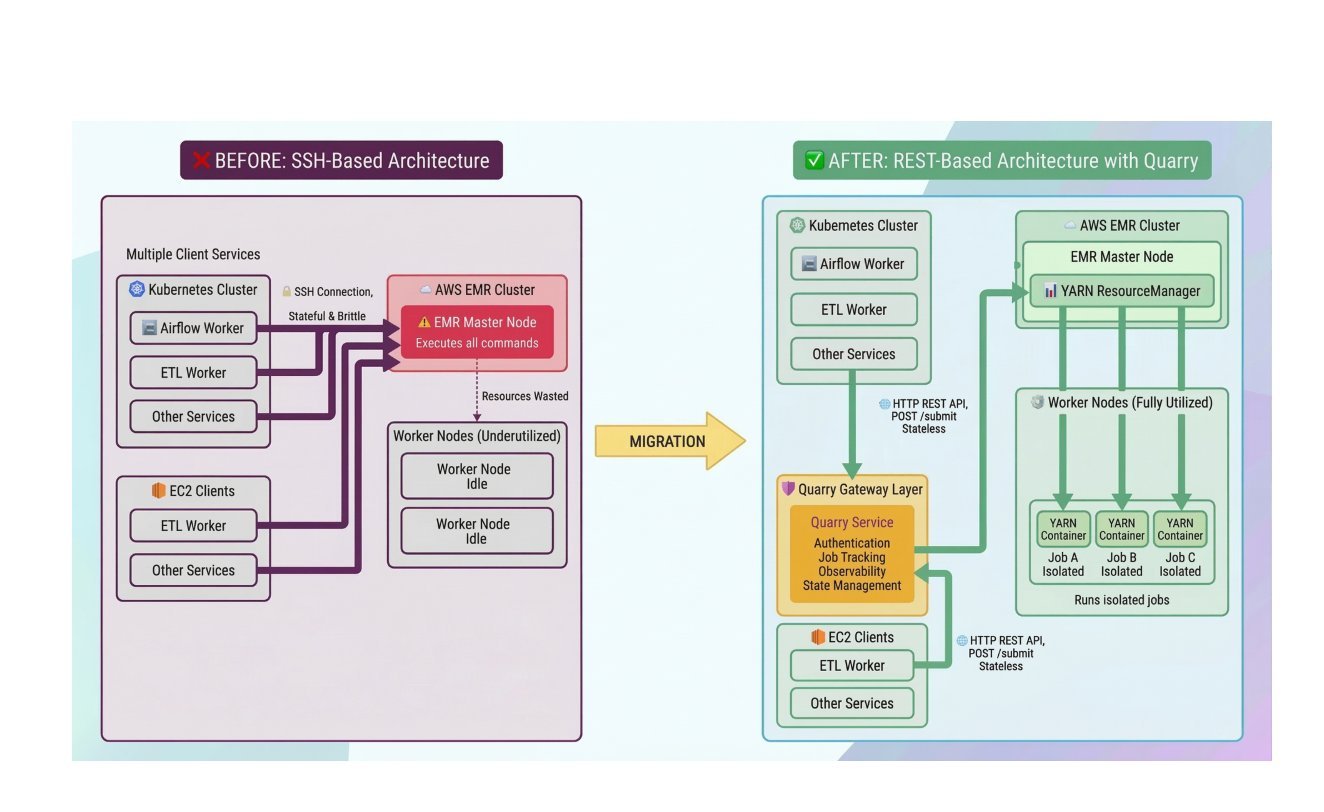
The important architectural shift here is decoupling execution from client connectivity. Once a job has a server-side identity and a server-side state machine, the orchestrator no longer needs to stay connected to know what is happening. It polls the job ID. If Airflow restarts, the job keeps running and its status is still queryable. If the network blips, nothing is orphaned, because the cluster owns the truth about the job rather than the client's socket. This is the same consistency argument that pushes people from fire-and-forget RPCs toward durable, addressable work items: you want a single authoritative record of state that survives the failure of any one participant.
That reframing is also what makes the system auditable. When submission goes through an API, the submission itself is an event you can log centrally, with structured metadata, rather than a shell invocation you have to reconstruct from scattered logs. Observability stops being forensic work and becomes a property of the design.
Not everything is a Spark job
The migration was not a uniform find-and-replace, because the workloads were not uniform. Spark and Hive jobs had a relatively clean path: they could move onto existing REST interfaces, Livy for Spark and HiveServer2 for Hive, both of which already model job submission as a server-side resource. The harder category was the large share of workloads that were just arbitrary shell commands. There is no tidy REST endpoint for "run this bash."
Slack handled those using Apache Hadoop YARN's Distributed Shell, which runs shell commands inside managed YARN containers with resource isolation and fault tolerance. This is a meaningful trade-off rather than a free win. Wrapping ad hoc commands in YARN containers buys you isolation and a managed lifecycle, but it also subjects those commands to YARN's resource accounting, and that is precisely where one of the more instructive failures showed up.
What SSH had been hiding
The most interesting part of this migration is not the destination but what became visible during the move. Running everything inside containers with enforced limits exposed YARN's virtual memory enforcement behavior, which SSH-based execution had quietly sidestepped. When a shell command runs in a raw SSH session on a master node, it inherits the node's loose resource posture. Move that same command into a YARN container with virtual memory checks, and behavior that was previously tolerated can get the container killed. The command did not change. The accounting around it did, and that surfaced an assumption nobody knew they were relying on.
The same theme recurred at the network layer. The cutover across eight regions, each with its own network segmentation and compliance constraints, revealed cross-account connectivity gaps and previously hidden dependencies between services. SSH connections had been traversing paths that the new submission model exercised differently, and some of those paths turned out not to be as available as everyone assumed. This is the recurring tax of removing a general-purpose escape hatch: the escape hatch was load-bearing in ways the documentation never recorded.
How they rolled it out
The rollout was incremental, moving through development, staging, and production, with phased operator deprecations and staged validation at each step. Slack used Airflow metadata dashboards to track which workflows still depended on SSH, which turns "are we done" from a guess into a query. Critical workloads saw no downtime across the full migration.
The stated lessons are unglamorous and correct. Discover your network topology early, because the migration will find the gaps whether you do or not. Validate resource limits across both execution models before you cut over, because the new model enforces things the old one ignored. And over-communicate when you start restricting operators, because the teams who own those 700 jobs need to know before their pipeline is the one that breaks.
Sudip Ghosh, Senior Software Engineer at Walmart, framed the result this way: "This isn't just a security win; it's a massive operational debt payoff. SSH is easy to start with, impossible to scale securely or audit consistently across a large organization."
Beyond the immediate gains in security, reliability, and observability, the REST model reduced the coupling between Airflow and EMR and standardized how teams submit jobs. That standardization is the real long-term payoff, because it gives Slack a stable submission interface to build on. The company points specifically to preparation for running Spark on Kubernetes, which is far more tractable when execution is already abstracted behind an API than when it is tangled up in SSH sessions to EMR master nodes. The full writeup is available on the Slack engineering blog.
Comments
Please log in or register to join the discussion