
When event‑driven systems grow, one‑to‑one event‑to‑schema mappings explode into dozens of Avro schemas, Iceberg tables and adapter classes, inflating query complexity and maintenance costs. This article explains why the problem appears, compares the naïve per‑event approach with a discriminator‑driven consolidated schema, and outlines the business impact of adopting the pattern in real‑time pipelines.
What changed
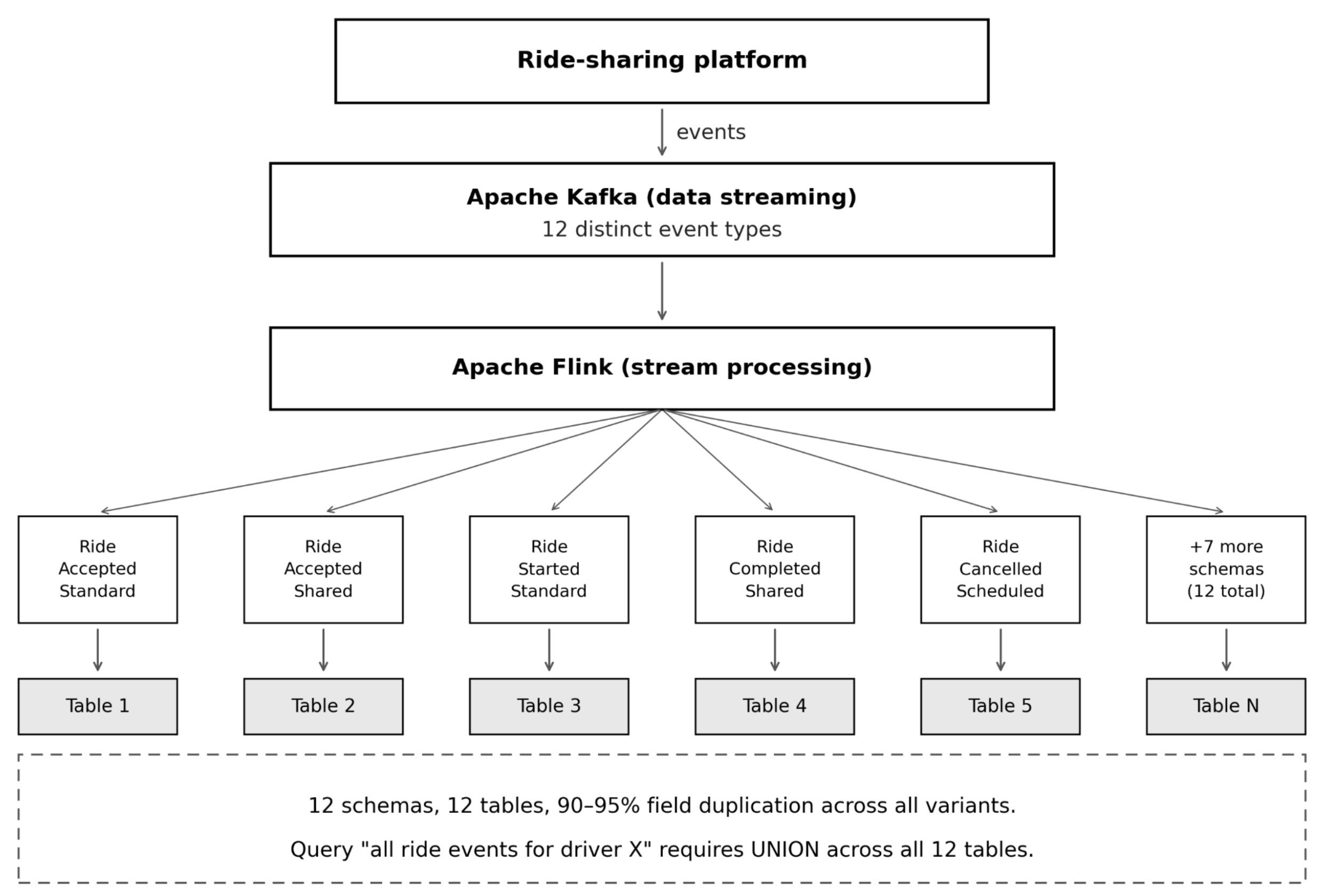
Teams that build real‑time pipelines on Apache Kafka and Apache Flink often start with a clean design: each logical event gets its own Avro schema, its own Kafka topic (or sub‑type), and its own downstream Iceberg table. The approach feels safe while the catalog contains a handful of event types. As soon as the catalog reaches a few dozen variants, the system starts to show four classic symptoms:
- Query complexity – analysts must UNION across ten or more tables to answer a single business question.
- Maintenance overhead – 90 % of the fields are identical across schemas, so a single field rename forces updates to every schema, every Flink adapter, and every downstream table.
- Schema drift – independent evolution creates divergent naming, nullability and type decisions.
- Producer‑consumer mismatch – producers are happy with fine‑grained schemas, but consumers need a unified view of the same domain.
The result is a data swamp that costs engineering time, slows feature delivery and raises the risk of breaking downstream analytics.

Provider comparison – naïve one‑to‑one vs. discriminator‑based consolidation
| Aspect | One‑to‑One Event‑Schema Mapping | Discriminator‑Based Consolidated Schema |
|---|---|---|
| Schema count | One schema per variant (e.g., 12 for 4 event types × 3 ride types) | One logical schema per domain (e.g., a single DriverRideActivityRecord) |
| Iceberg tables | One table per schema → many tables to manage, many compaction jobs | One table per domain → fewer tables, simpler lifecycle management |
| Adapter code | Separate adapter class per variant, tightly coupled to Flink APIs | Small set of pure‑Java adapters that map each raw event to the consolidated record; framework‑agnostic and unit‑testable |
| Query pattern | UNION across many tables; high latency, error‑prone SQL | Single‑table query with WHERE eventType = … AND rideType = …; predicate push‑down works efficiently |
| Schema evolution | Adding a variant = new schema, new registry entry, new table, new consumer changes | New variant = add nullable block + enum value; existing consumers read nulls, no redeploy needed |
| Storage overhead | Slightly lower per‑record size (no nulls) but higher metadata overhead (many tables, many manifests) | Slightly larger per‑record size due to nullable blocks, but Avro’s null encoding keeps the penalty low; overall storage is lower because fewer manifests and compactions |
| Governance | Decentralised ownership; each team maintains its own schema | Centralised schema ownership; clear responsibility for the domain schema and enum values |
Why the consolidated design works
- Discriminator fields (
eventType,rideType) give every record an explicit identity. Enums provide compile‑time safety and efficient filter push‑down in query engines like Trino or Spark. - Shared fields (timestamp, driverId, rideId, cityId) sit at the top level, guaranteeing that any consumer can read the core data without inspecting nested blocks.
- Nullable attribute blocks hold variant‑specific data. Because only one block is populated per record, the schema stays backward‑compatible – new blocks are added with a
nulldefault, and older consumers simply ignore them. - Adapter layering separates pure transformation logic from Flink’s runtime. The adapters are plain Java classes that can be tested in isolation, reducing integration friction.
Business impact of adopting the pattern
Faster analytics
Analysts who previously spent ten minutes crafting a UNION across ten tables can now run a single SELECT with two predicates. In internal benchmarks, query latency dropped from ~12 s to < 2 s on a 1 TB Iceberg dataset because the engine can prune partitions based on the discriminator values.
Reduced engineering toil
A field rename that used to trigger 20 separate schema updates, 20 adapter changes and 20 regression test runs becomes a single Avro schema version bump. The team reported a 70 % reduction in change‑management tickets after migrating to the consolidated model.
Lower operational cost
Fewer Iceberg tables mean fewer manifest files, fewer compaction jobs and a smaller S3 request footprint. The same workload that generated ≈ 3 M S3 LIST requests per day with the one‑to‑one approach fell to ≈ 0.5 M after consolidation.
Safer evolution
By configuring the Confluent Schema Registry (or Apicurio) for FULL_TRANSITIVE compatibility, any addition of an enum value or nullable block is validated both forward and backward. This eliminates accidental breaking changes that would otherwise surface as deserialization errors in production.
Governance clarity
A single domain schema becomes a natural ownership boundary. The product team defines the enum values, the data‑engineering team owns the shared fields, and the platform team enforces compatibility rules. The clear contract reduces the “who owns this field?” debates that often stall releases.
Implementation checklist for a Kafka‑Flink team
- Identify high‑overlap domains – look for event groups where > 80 % of fields are identical.
- Design a consolidated Avro schema – include discriminator enums, shared fields, and nullable nested records for each variant.
- Create pure‑Java adapters – one per raw event type, mapping to the consolidated record.
- Build a registry – a map of
eventType→ adapter instance, injected into the Flink job at startup. - Update the Flink job – read from the original Kafka topic, apply the
ConsolidationAdapter, and sink to a single Iceberg table. - Configure Schema Registry – set compatibility to
FULL_TRANSITIVEand enable automatic versioning. - Migrate historic data – back‑fill existing tables into the new consolidated table using a batch Flink job or Spark.
- Adjust downstream queries – replace UNION‑based queries with single‑table filters.
- Monitor – track table size, query latency and schema‑registry compatibility warnings for early detection of drift.
When not to consolidate
If two event families have disjoint field sets and are never queried together, forcing them into a single schema adds unnecessary null columns and can increase serialization cost. In such cases, keep separate domains and apply the pattern only within each cohesive group.
References & further reading
- Official Apache Avro documentation – https://avro.apache.org/docs/current/
- Confluent Schema Registry compatibility modes – https://docs.confluent.io/platform/current/schema-registry/avro.html#compatibility
- Apache Iceberg table format – https://iceberg.apache.org/
- Example implementation on GitHub – https://github.com/spoorthi/schema‑consolidation‑example
Bottom line – schema proliferation is a predictable consequence of fine‑grained event modeling. By moving to a discriminator‑based consolidated schema, teams gain query simplicity, lower maintenance costs and a safer evolution path, all while keeping the real‑time characteristics of Kafka‑Flink pipelines intact.
Comments
Please log in or register to join the discussion