As AI-generated content floods our digital landscape, researchers are uncovering a troubling paradox: the more we rely on AI for information, the harder it becomes to discern quality and accuracy. This emerging crisis threatens to undermine our collective ability to process complex ideas and verify critical information, potentially reshaping how we learn, create, and collaborate.
The AI-Induced Information Crisis: How Generative Models Are Eroding Our Ability to Process and Verify Content
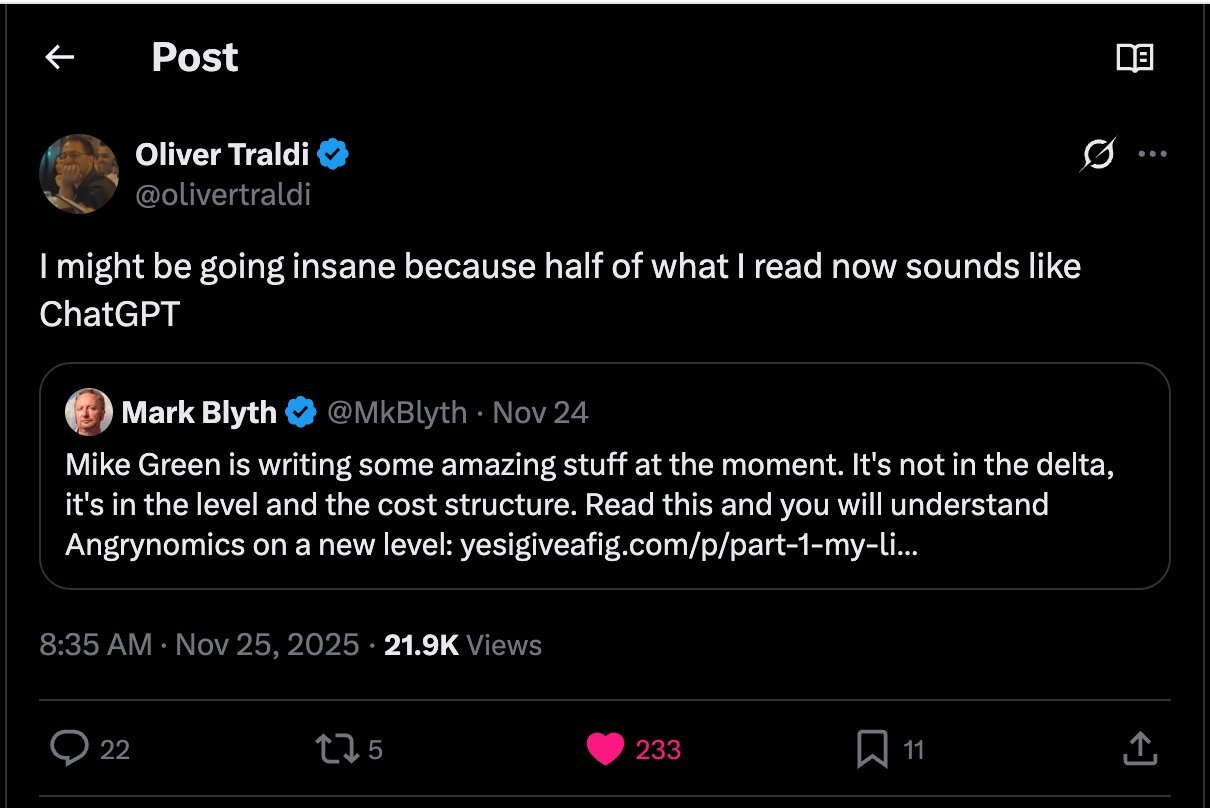
In the rapidly evolving landscape of artificial intelligence, a subtle yet profound transformation is occurring in how humans process information. A recent tweet captured this phenomenon perfectly: "I might be going insane because half of what I read now sounds like ChatGPT." This sentiment resonates deeply with many professionals who find themselves trapped in an information loop where everything seems homogenous, despite being technically correct.
This isn't merely a matter of stylistic preference. As researchers delve deeper into the implications of widespread AI content generation, they're identifying two distinct but related challenges: signal degradation and verification erosion. These issues threaten to undermine our collective ability to process complex ideas and verify critical information, potentially reshaping how we learn, create, and collaborate.
Signal Degradation: The AI That Cried Wolf
In complex domains, humans have developed sophisticated tools to aid comprehension. In writing, metaphors compress complex ideas into familiar territory—comparing a database index to a book's table of contents helps newcomers grasp the concept faster than technical definitions. In programming, exception handling serves not just to catch runtime errors but to communicate potential failure modes to human readers.
However, AI systems have overused these communication tools indiscriminately. When every paragraph contains a metaphor or every code block is wrapped in excessive exception handling, these devices lose their signal value. The result is a kind of rhetorical inflation where phrases like "delve" and "crucial" now pattern-match as AI-generated content, regardless of their origin.
"When every paragraph has a metaphor, you stop noticing metaphors. When every code block is wrapped in exception handling, none of them feel exceptional."
This overuse creates a paradox: the very tools designed to enhance comprehension become noise that we tune out. For technical professionals, this means losing valuable signals that once helped distinguish expert content from generic explanations.
Verification Erosion: Cheap to Generate, Expensive to Verify
The second challenge stems from a fundamental shift in the economics of content creation. In the pre-LLM era, generating output required significant effort, making verification comparatively manageable. Today, AI can produce plausible content in seconds, but verification still demands the same human effort as before.
This imbalance has created a dangerous pattern: when something seems off, the temptation is to regenerate rather than verify. This "slot machine" approach—pulling the lever again for a better result—substitutes for the slower, more meaningful work of understanding whether output is correct.
The problem is compounded by the unique failure modes of LLM-generated content. Unlike human-created content, which tends to follow recognizable patterns of expertise, AI content can contain subtle errors that escape traditional quality checks:
- Literature reviews that cite real researchers but invent paper titles
- Technical explanations that contain plausible-sounding but incorrect jargon
- Code that handles common cases but fails on edge cases a human would anticipate
"The failure modes are endless and subtle, and I don't have tools to catch them at scale."
This verification crisis isn't just an inconvenience; it represents a fundamental challenge to how we maintain quality in technical fields. When even experts struggle to distinguish between correct and plausible-but-wrong content, the entire knowledge ecosystem becomes vulnerable to degradation.
Why This Matters: Beyond Inconvenience
The implications of these challenges extend far beyond personal frustration. Two critical concerns emerge:
First, the erosion of comprehension and verification creates vulnerability to manipulation. This isn't just about dramatic misinformation scenarios but about subtle, systemic failures:
- Engineers shipping code that appears robust but contains hidden flaws
- Researchers building on work that doesn't actually exist
- Decision-makers acting on analyses that seem correct but contain subtle errors
Second, the degradation of taste and judgment threatens to diminish quality across domains. Taste in any field develops through a feedback loop: noticing what's good, what's bad, and refining one's understanding over time. When this loop breaks, quality becomes indistinguishable from quantity.
"The tools for communication and verification are how we build on each other's work. When they erode, we become a society that can't tell what's true, can't recognize quality, and can't coordinate on hard problems."
This represents a profound challenge to how knowledge progresses. If we can't distinguish between human insight and AI fluency, we risk losing the very mechanisms that have allowed fields to advance through careful critique and refinement.
Toward Solutions: Rethinking AI Assistance
Addressing these challenges requires rethinking how we design and deploy AI systems in knowledge work. Two promising directions are emerging:
Teaching Systems the "Why" Behind Techniques
Rather than programming AI with surface-level heuristics ("use bullet points for dense content"), we need systems that understand the underlying principles. For example:
- Bullet points work best for parallel, independent ideas, not when connective tissue is needed
- Metaphors should be used when concepts are genuinely difficult to explain directly
- Exception handling should reflect actual risk, not just programming best practices
"A system built around the why would need to assess whether there's actually a deeper framing to be made—not just pattern-match on what emphatic writing looks like."
This approach would move beyond current pattern-based systems to ones that reason about the appropriateness of communication techniques based on the content itself.
Grounding Confidence in Verified Human Experience
A fundamental challenge is how AI systems can make judgments about quality, taste, or accuracy without actually experiencing these qualities themselves. The current approach—training models to predict human preferences—has limitations.
An alternative approach involves "hypothetical grounding spaces": structured records of verified human experiences that models query rather than claim as their own. For example:
- A recipe bot might say "humans who skipped bacon in similar dishes reported it was still good" rather than "I know it tastes good"
- A writing assistant might reference "explanations like this one tended to lose readers" rather than claiming "I think this is confusing"
This approach maintains attribution to human experience while still leveraging AI's ability to process and retrieve information at scale.
The Path Forward
As AI-generated content becomes the majority of what we consume, preserving human feedback loops becomes increasingly important. This requires:
- Developing better tools for detecting and verifying AI-generated content
- Creating systems that enhance rather than replace human judgment
- Maintaining spaces where authentic human expertise can be recognized and valued
The challenges ahead are significant, but so are the stakes. If we can't address the twin crises of signal degradation and verification erosion, we risk undermining the very foundations of how knowledge progresses in technical fields.
In the meantime, researchers and practitioners must remain vigilant, cultivating their own judgment even as the information landscape becomes increasingly homogenized. The future of knowledge work may depend on our ability to distinguish between AI fluency and human insight.
Comments
Please log in or register to join the discussion