An exploration of how rqlite takes control of SQLite's WAL to enable efficient distributed consensus, transforming a simple storage engine into a sophisticated fault-tolerant database system.
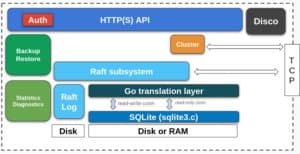
The relationship between rqlite and SQLite's Write-Ahead Log (WAL) represents a fascinating case study in how specialized systems can leverage existing technologies in novel ways. At its core, rqlite is a lightweight, open-source, fault-tolerant relational database built on SQLite and the Raft consensus algorithm. Version 10 of rqlite introduces refinements to its WAL management strategy that solve fundamental challenges in distributed database design.
The Fundamental Problem: SQLite's Autonomous WAL Management
SQLite, by default, manages its WAL according to its own schedule. It checkpoints when the WAL grows beyond certain thresholds, when the last connection closes, and autonomously decides when frames move from the WAL back into the main database file. This autonomous behavior creates a significant challenge for rqlite, where the WAL is not merely an implementation detail but a core component of the distributed system's architecture.
In a Raft-based system like rqlite, the WAL serves as the incremental state tracker needed for consistent replication across nodes. If SQLite checkpoints at inopportune moments, rqlite can no longer rely on the WAL as a reliable representation of unsnapshotted state. This tension between SQLite's autonomous WAL management and rqlite's distributed requirements represents the central problem that the rqlite team has spent years solving.
From Full Snapshots to WAL-Based Incremental Snapshots
Early versions of rqlite employed a straightforward snapshotting approach: when Raft requested a snapshot, rqlite provided a complete copy of the entire SQLite database. This approach was robust but suffered from severe inefficiencies as databases grew. Copying a multi-gigabyte database to capture just a few hundred rows of changes became impractical.
The solution emerged from leveraging SQLite's WAL mode, where all changes are written as frames in a separate file before being checkpointed back to the main database. rqlite developed a strategy where, during snapshotting, it copies the current WAL and hands that copy to Raft before checkpointing the WAL into the main database file. This approach transforms the WAL into an incremental state representation, capturing exactly the changes since the last accepted Raft snapshot.
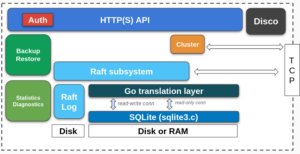
Figure: rqlite's system design showing how the WAL serves as the incremental state tracker
Taking Control: Configuring SQLite for Distributed Needs
rqlite's solution requires SQLite to behave in specific ways that differ from its default operation. Rather than modifying SQLite's source code, rqlite achieves control through careful configuration:
- Disabling all automatic checkpointing, ensuring SQLite doesn't move WAL frames without rqlite's knowledge
- Trapping user-issued PRAGMA commands that would checkpoint or change WAL mode
- Explicitly disabling checkpoint-on-close to enable fast restart times
From this point forward, rqlite drives checkpointing explicitly as part of the snapshotting process, always requesting a TRUNCATE checkpoint that resets the WAL file to zero bytes after a successful checkpoint. This level of control is essential for maintaining the integrity of the distributed state.
Navigating the Real World: Handling Checkpoint Failures
The ideal path of checkpointing works smoothly in theory, but the practical implementation must handle numerous edge cases. The most significant challenge occurs when readers block the checkpoint operation. In SQLite, a reader can prevent a WAL checkpoint from completing, which would leave rqlite in an inconsistent state.
rqlite addresses this by implementing a sophisticated timeout mechanism. It waits up to 250ms for blocking readers to complete their work. If readers haven't finished by then, SQLite returns an error, and rqlite must handle the failure. Two distinct failure scenarios can occur:
SQLite cannot reset the WAL: This happens when readers are accessing frames other than the last frame in the WAL. In this case, rqlite can signal back to Raft that the snapshot has failed and retry later.
SQLite checkpoints frames but cannot truncate the WAL: This occurs when all readers are accessing only the last frame. Here, rqlite employs a clever workaround: it records the WAL's salt values and length. On the next snapshot, it checks if the salt values have changed to determine if the WAL was reset.
Version 10 of rqlite significantly improves this behavior, abandoning the previous approach of waiting up to five minutes for readers to complete. Instead, it either completes snapshots quickly or aborts them to be retried shortly after, preventing excessive blocking of writes.
Optimizations Enabled by WAL Understanding
As the rqlite team developed deeper understanding of SQLite's internals, they discovered several optimizations that improve system performance:
WAL Compaction
During snapshotting, the WAL contains all modified database pages since the last snapshot. Analysis revealed that the same page numbers often appear multiple times in the WAL, with later checkpoint operations overwriting earlier ones. rqlite now implements WAL compaction, creating a copy that retains only the last version of any given page number. This optimization can reduce WAL size by up to 100x, dramatically decreasing the data transferred to Raft during snapshotting.
Fast Restarts
In Raft-based systems, the state machine (SQLite database in rqlite's case) can theoretically be rebuilt from scratch at any time using the last snapshot and subsequent log entries. However, this approach would be prohibitively slow for multi-gigabyte databases. rqlite implements a fast restart mechanism by calculating a checksum of the SQLite database file during snapshotting and storing it in a sidecar file. On restart, rqlite compares the checksum of the current SQLite file with the stored value. If they match, it skips the restoration process entirely, enabling restarts in seconds even for large datasets.
This approach also explains why checkpoint-on-close had to be disabled—if SQLite checkpointed the WAL when the last connection closed, the database file would be modified after the sidecar checksum was written, preventing the fast restart path from working.
Validation and Testing
Given that rqlite uses SQLite in ways the original designers may not have anticipated, extensive testing is crucial to ensure correctness. The rqlite team implements several validation strategies:
Integrity checking: During testing, rqlite continually executes full integrity checks on the consolidated database in the Snapshot Store. While disabled in production due to performance concerns, this testing would catch any issues in the WAL pipeline.
Behavior verification: For every behavior rqlite relies on in SQLite, specific tests exist to ensure that reliance is warranted. For example, tests verify that SQLite indeed does not checkpoint-on-close when configured appropriately.
Broader Implications
The rqlite approach demonstrates several important principles for building distributed systems on top of existing technologies:
Deep understanding enables innovation: By thoroughly understanding SQLite's WAL internals, the rqlite team could design a sophisticated distributed system without modifying the core database engine.
Control over autonomy: Sometimes the most effective way to build a specialized system is to carefully control the behavior of general-purpose components rather than modifying them directly.
Incremental snapshots are transformative: The ability to create incremental snapshots rather than full database copies enables practical scaling of distributed databases to much larger sizes.
Optimization through understanding: The WAL compaction optimization demonstrates how deep technical understanding can lead to orders-of-magnitude improvements in efficiency.
Conclusion
rqlite's evolution represents a sophisticated approach to building distributed systems. By taking control of SQLite's WAL rather than accepting its default behavior, the rqlite team has created a system that maintains the simplicity and reliability of SQLite while adding distributed fault tolerance. The WAL management strategy in version 10 demonstrates how careful design can solve fundamental challenges in distributed databases, enabling efficient operation even at scale.
For those interested in exploring rqlite further, the official documentation provides comprehensive guidance, and the GitHub repository offers access to the source code. The project's Slack channel provides a space for discussion and questions about the implementation details that make this sophisticated WAL management possible.
Comments
Please log in or register to join the discussion