
In an unprecedented experiment, 6 frontier AI models were tasked with building 52 different apps from identical prompts, with no editing allowed. The results reveal surprising strengths, weaknesses, and the evolving state of AI-generated code.
In the rapidly evolving landscape of artificial intelligence, a groundbreaking experiment has emerged, offering a raw, unfiltered glimpse into the capabilities of today's most advanced language models. Arena, a platform from Logic Inc., conducted a rigorous comparison where six frontier AI models—GPT-5, GPT-5.1, Opus 4.1, Opus 4.5, Sonnet 4.5, and Gemini 3—were each given the same 52 prompts to build complete applications. The twist? No human editing, no cherry-picking, just pure, automated output. The results are both illuminating and humbling for anyone invested in the future of software development.
The Experiment: A Controlled Test of AI Prowess
The setup was deceptively simple yet methodically rigorous. Each model received identical prompts spanning 52 diverse application types—from games like Asteroid Game and Tic Tac Toe to utility tools like CSV to Charts and Regex Lab, and even complex landing pages such as Customer Case Study and Online Academy. The goal was to eliminate variables and observe how different architectures handle identical creative and technical challenges. The sheer variety is staggering: 
"This isn't about polished demos; it's about seeing what these models can produce when pushed to the limit," notes the Arena team. "No safety nets, no human intervention. Just the model and the prompt."
The Players: Titans of the AI Frontier
The roster of models tested represents some of the most advanced systems in development: OpenAI's GPT-5 and GPT-5.1 (likely internal or pre-release versions), their Opus 4.1 and Opus 4.5 series, Sonnet 4.5, and Google's Gemini 3. While specific technical details remain proprietary, the experiment provides a rare apples-to-apples comparison of how these systems translate natural language into functional code.
A Tour of the AI-Generated Universe
The resulting apps form a fascinating catalog of AI capabilities. Consider Artisan CSA, a landing page for a community-supported agriculture service. 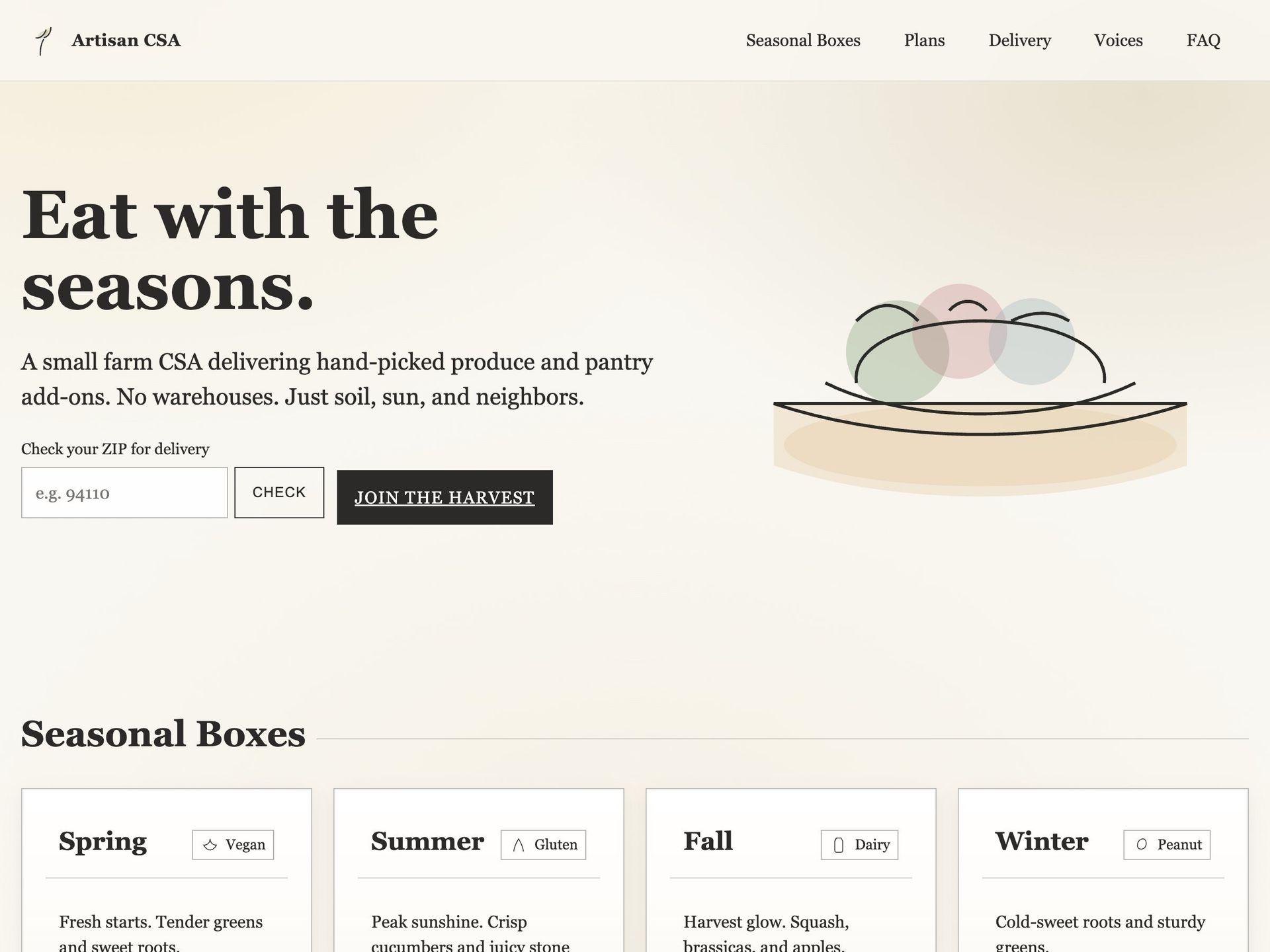 While functional, it lacks the nuanced branding a human designer might infuse. Contrast this with Bay Area Espresso Lab
While functional, it lacks the nuanced branding a human designer might infuse. Contrast this with Bay Area Espresso Lab 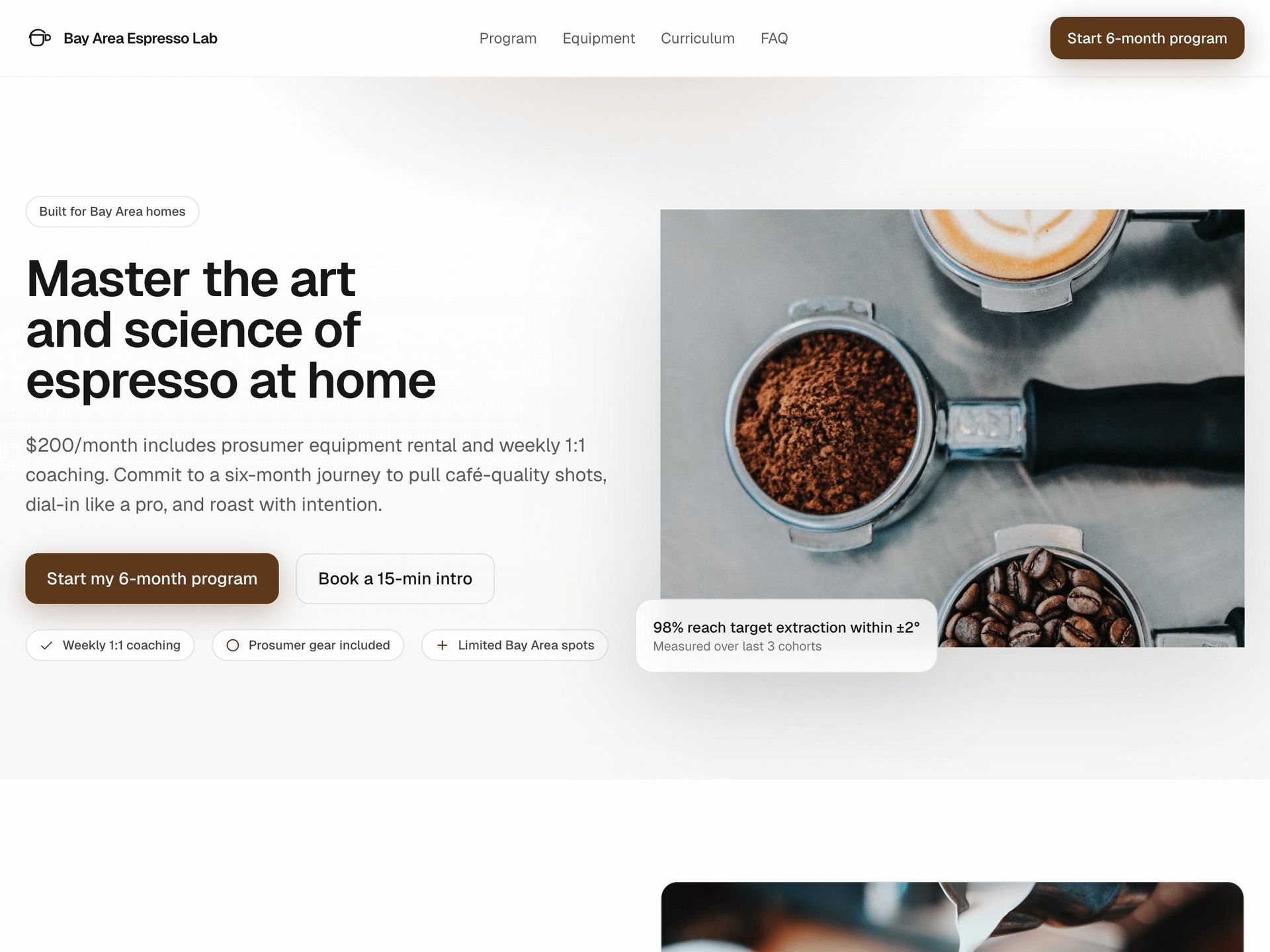 , a coffee shop landing page that demonstrates stronger visual cohesion. Games like Asteroid Game
, a coffee shop landing page that demonstrates stronger visual cohesion. Games like Asteroid Game 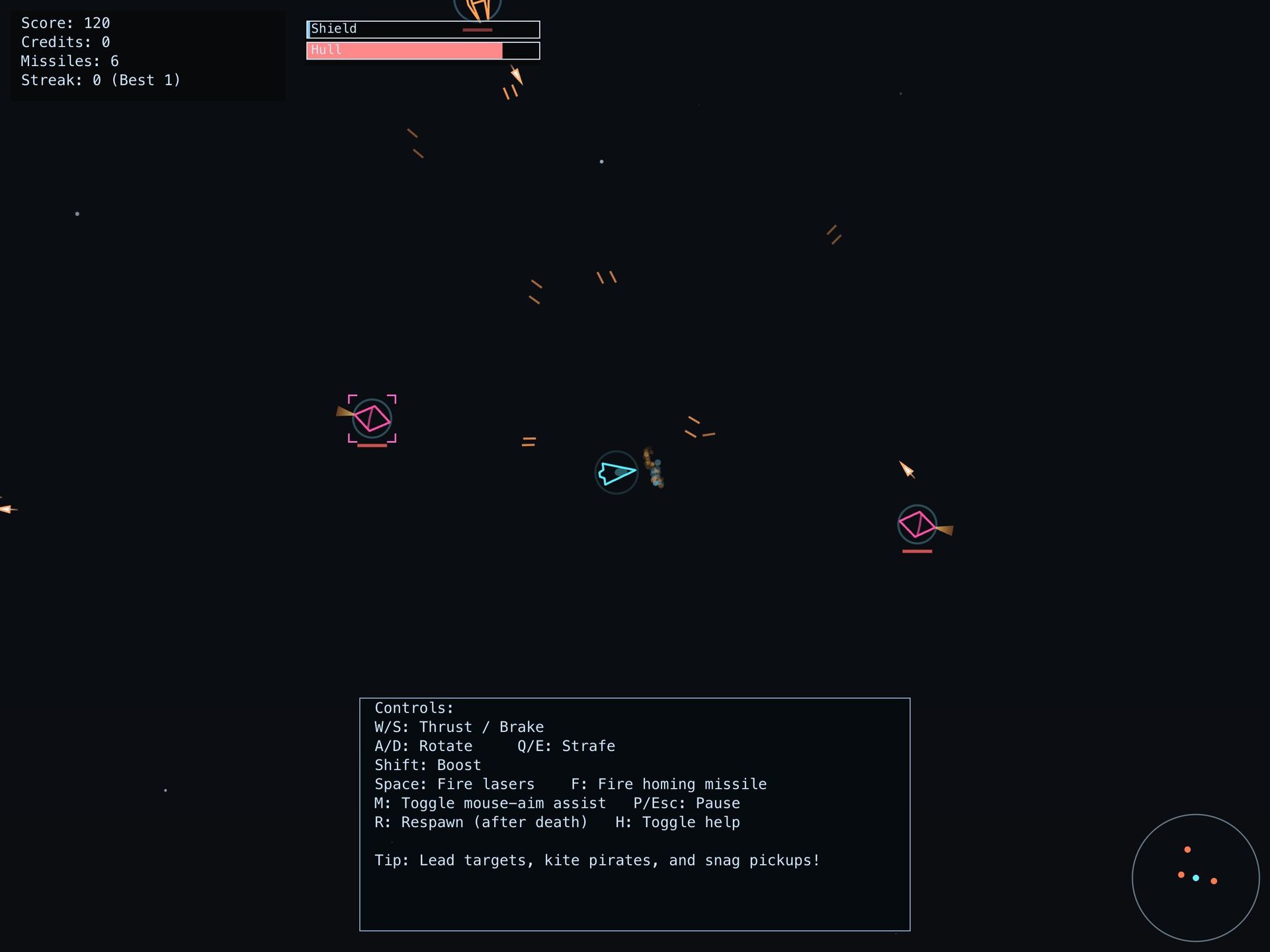 show basic mechanics but reveal gaps in advanced physics simulation, while Audio Step Sequencer
show basic mechanics but reveal gaps in advanced physics simulation, while Audio Step Sequencer 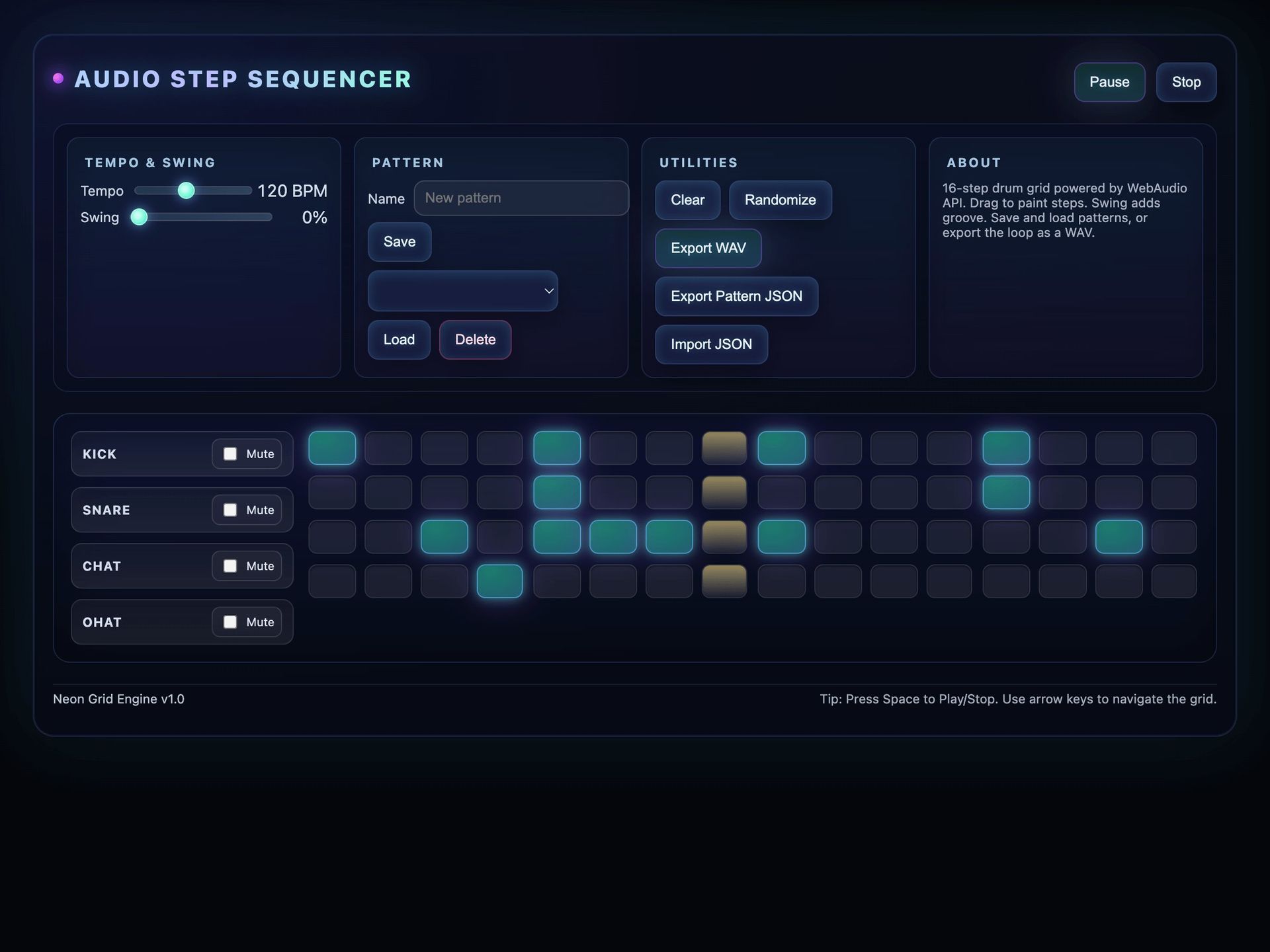 highlights how some models excel at audio processing workflows.
highlights how some models excel at audio processing workflows.
The diversity extends to interactive experiences. Ocean Wave Simulation and Festival Lights Show demonstrate impressive generative visuals, yet often lack the responsive polish of human-coded counterparts. Utility apps like Equation Solver Tool and QR Code Generator prove remarkably accurate in core functionality, though error handling remains a consistent weak point across all models.
Patterns in the Code: Strengths and Systemic Gaps
Three key patterns emerge from the data:
Consistency vs. Creativity: Models like Opus 4.5 and Sonnet 4.5 produced the most structurally consistent code, adhering closely to best practices. However, they occasionally sacrificed creative flair for reliability. Gemini 3, conversely, took more bold design risks but sometimes introduced bugs in complex interactions.
Domain Specialization: No model dominated all categories. Games saw the highest variance in quality, while data tools like CSV to Charts showed the most uniform competence. Landing pages were a mixed bag, with GPT-5.1 generating the most semantically rich HTML but weaker CSS styling.
The "Last Mile" Problem: Every model struggled with edge cases and user experience polish. Input validation, error states, and responsive design were frequently incomplete. As one developer observed, "They can build the engine, but they forget the cupholders."
Implications for the Development Ecosystem
This experiment serves as both a report card and a warning for the software industry. For developers, it validates AI as a powerful prototyping tool—especially for boilerplate code, MVPs, and repetitive tasks. The Micro Habit Tracker and Markdown → Slides tools, for instance, could be assembled in minutes by these models, freeing human engineers for higher-level architecture.
Yet the systemic gaps highlight critical limitations. AI-generated code often requires significant post-processing for production readiness. Security vulnerabilities, performance bottlenecks, and accessibility oversights were common across outputs. "This isn't about replacing developers," says Arena's lead researcher. "It's about augmenting them. The smart teams will use these tools to accelerate iteration, not to cut corners."
The Verdict: A Glimpse of the Collaborative Future
As the final app renders in the browser, the truth becomes clear: we're witnessing the birth of a new paradigm in software creation. These models aren't just code generators; they're collaborative partners that handle grunt work while humans focus on creativity and system design. The Employee Skills Matrix and Customer Journey Flow tools exemplify this potential—automating tedious data visualization so strategists can focus on insights.
The path forward isn't about choosing between human and machine, but about mastering the interplay. The developers who thrive will be those who can prompt effectively, audit AI output critically, and inject the human judgment these models still lack. In this great AI bake-off, the real winner isn't any single model—it's the dawn of a more efficient, imaginative, and collaborative development era.
Comments
Please log in or register to join the discussion