An analysis of how random UUIDs as primary keys significantly impact SQLite performance due to B-tree restructuring, with comparisons to alternative approaches.
The article presents a compelling case study on the often-overlooked performance implications of using UUIDs as primary keys in SQLite databases. Through careful benchmarking and profiling, the author demonstrates that seemingly innocuous design decisions can have profound effects on database performance, particularly in high-insertion scenarios.
The core issue stems from how SQLite handles clustered indexes. In standard tables, SQLite uses an implicit 64-bit integer primary key called rowid that determines the physical storage order of rows. This sequential nature allows for efficient inserts at the end of the B-tree structure. However, when random UUIDs are used as primary keys—especially in WITHOUT ROWID tables—the unordered nature of these identifiers forces SQLite to constantly rebalance its B-tree structure during inserts.
The benchmark results are striking: using UUID4 WITHOUT ROWID resulted in 14-16x slower performance compared to traditional integer primary keys. While inserting 10 million rows with integer keys took approximately 838 milliseconds, the same operation with UUID4 WITHOUT ROWID took 2,649 milliseconds. This performance gap widens as more rows are inserted, reaching 12,586 milliseconds for 100 million rows compared to 715 milliseconds for integer keys.
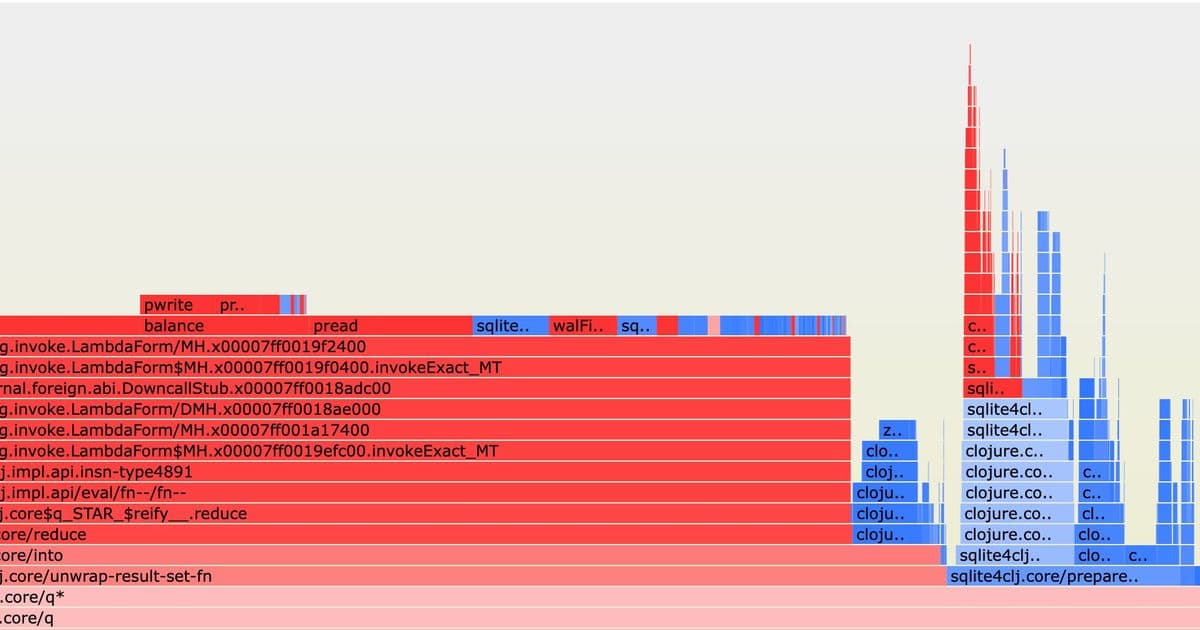
The profiling data visualized through the diffgraph reveals the root cause: extensive time spent on tree balancing, reading, and writing operations. Each random UUID insertion forces SQLite to find the appropriate position in the B-tree, potentially splitting pages and rebalancing the structure—operations that are far more expensive than appending to the end of a sequentially ordered structure.
The article then explores potential solutions. UUID7, which incorporates timestamps to ensure time-ordered values, performs significantly better than UUID4, achieving approximately 800,000 inserts per second compared to 80,000 for UUID4. However, this still falls short of the baseline integer performance of 1 million inserts per second. The author also tests UUID4 WITH ROWID, which maintains the hidden rowid as the clustered index while adding a secondary index for the UUID. This approach performs better than UUID4 WITHOUT ROWID but still lags behind UUID7 WITHOUT ROWID.
Several important implications emerge from this analysis:
Design Trade-offs: The choice of primary key is not merely an implementation detail but a fundamental design decision with significant performance implications. While UUIDs offer advantages in distributed systems (collision resistance, no central coordination), they come at a substantial performance cost in SQLite.
Storage Considerations: UUIDs require 16 bytes of storage compared to 8 bytes for integers, contributing to increased storage requirements and potentially affecting cache efficiency. This overhead compounds the performance issues caused by random insertion patterns.
Write Amplification: Using UUID4 WITH ROWID creates dual indexes, leading to write amplification as each insert requires updates to both the rowid index and the UUID index.
Alternative Approaches: The article suggests that time-ordered UUID7 offers a reasonable compromise, though it requires coordination to ensure proper time ordering in distributed systems. Other alternatives like Snowflake IDs or ULIDs might provide better performance while maintaining distributed generation capabilities.
From a broader perspective, this analysis highlights the importance of understanding database internals when making architectural decisions. The performance gap between sequential and random primary keys is not unique to SQLite—any database using clustered indexes (including PostgreSQL, SQL Server, and others) will face similar challenges. However, SQLite's B-tree implementation and lack of sophisticated caching mechanisms for random inserts make these issues particularly pronounced.
For developers working with SQLite, the article offers clear guidance: prefer integer primary keys for optimal performance, especially in write-heavy scenarios. If UUIDs are necessary for business requirements, consider UUID7 for better performance characteristics, and carefully evaluate whether the WITHOUT ROWID approach provides benefits that outweigh the performance costs.
The benchmark code provided in the article enables developers to reproduce these results in their own environments, allowing for informed decisions based on actual performance characteristics rather than theoretical assumptions. This empirical approach to database performance analysis is particularly valuable in an era where intuition often fails to predict the real-world behavior of complex systems.
For those interested in exploring further, the related articles on achieving 100,000 TPS with SQLite and the technical details of clustered indexes provide additional context for understanding these performance characteristics. The diffgraph visualization tool mentioned in the article offers a powerful way to analyze and understand the internal operations of database systems, helping developers make more informed design decisions.
Comments
Please log in or register to join the discussion