As replication failures and data scandals plague scientific publishing, researchers must sharpen their critical evaluation skills. This guide distills four warning signs of unreliable papers—fraudulent data, insufficient samples, analytical malpractice, and overreaching conclusions—into actionable checks for technical professionals navigating today's research landscape.
The Credibility Crisis: How to Spot Shaky Science Before It Derails Your Work
For developers building AI models, engineers designing experiments, or tech leaders investing in R&D, the stakes for evaluating research have never been higher. A startling 10,000+ papers were retracted in 2023 alone—a 20-fold increase since 2011—with fraud implicated in up to 94% of cases. Yet retracted papers continue to be cited for years, perpetuating flawed knowledge. This crisis demands sharper critical reading skills across technical fields.
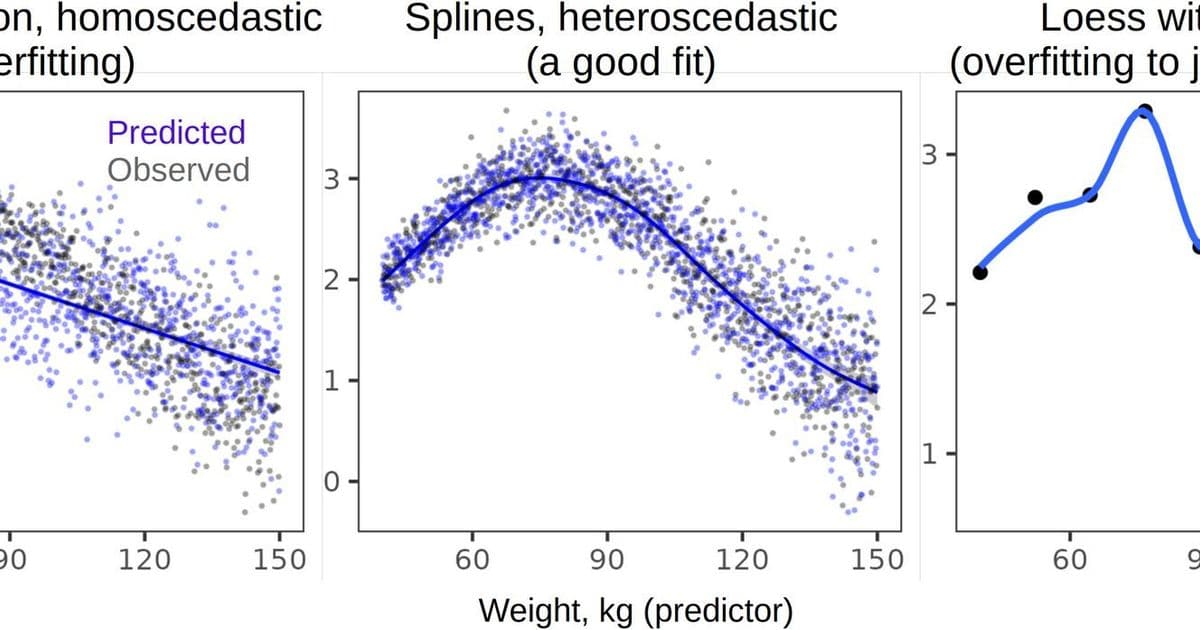
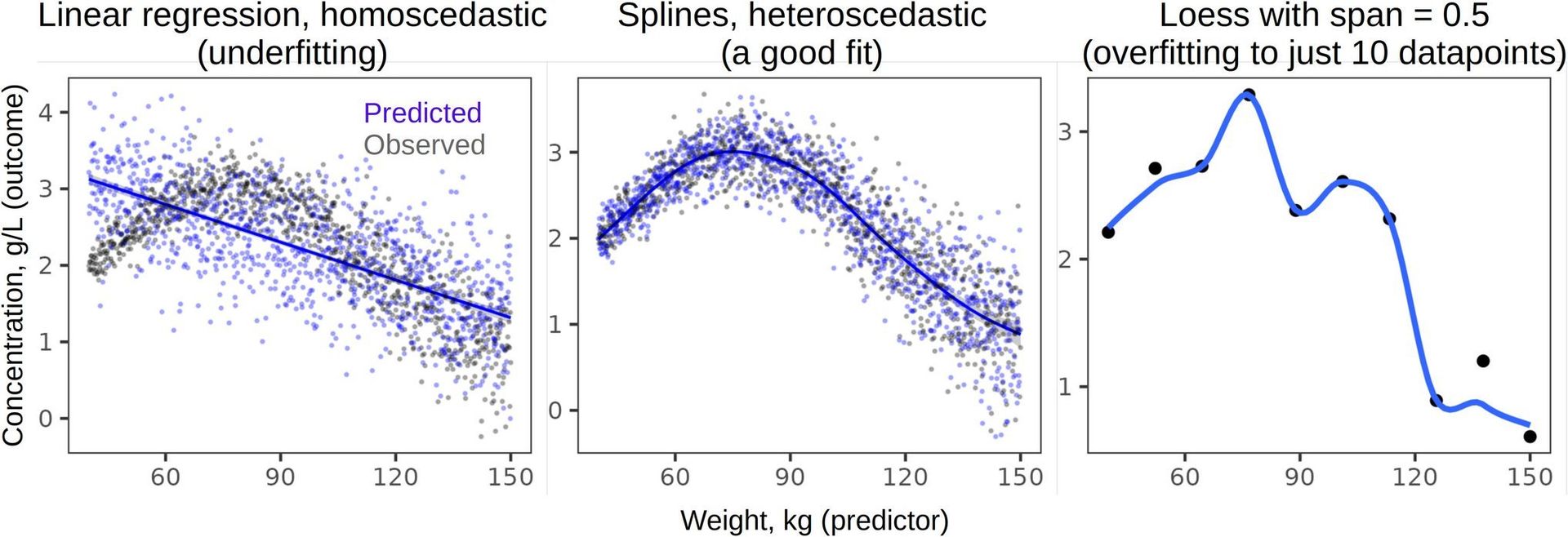 Figure 1: Telltale signs of poor model fit—like this linear regression failing to capture sinusoidal patterns—often reveal analytical malpractice. Always cross-check raw data plots against model claims. (Source: Anikin, 2025)
Figure 1: Telltale signs of poor model fit—like this linear regression failing to capture sinusoidal patterns—often reveal analytical malpractice. Always cross-check raw data plots against model claims. (Source: Anikin, 2025)
The Four Pillars of Trustworthiness
1. Authenticity Red Flags: Is This Data Real?
- Retraction Radar: Check Retraction Watch and journal notices. 21 papers were immediately withdrawn when editors requested raw data.
- Author Patterns: Repeat offenders exist—some researchers boast >100 retractions. Scrutinize authors with improbably high output.
- Journal Quality: Predatory journals and paper mills proliferate. Verify indexing and editorial boards.
- Data Inspection: Request datasets. Fabricated data often shows:
- Suspiciously low variance
- Impossibly matched groups
- Digit distribution anomalies (Benford's law)
2. The Power Problem: When Samples Lie
- Beyond N: Sample adequacy depends on design complexity. Multilevel models need sufficient units at each level (e.g., 40 participants × 40 items > 200 × 8).
- Uncertainty Speaks: Wide confidence intervals (e.g., Cohen's d = 0.8 ± 0.5) scream underpowered studies—even with "significant" p-values.
- Sensitivity Sniff Test: Do conclusions flip when adding/removing outliers? That's instability from insufficient data.
3. Analytical Integrity: From p-Hacking to HARKing
"Researcher degrees of freedom turn exploratory findings into false confirmations." — Gelman & Loken (2014)
- Flexibility Fiascos: Detect p-hacking via:
- Undisclosed multiple testing
- Stepwise model fishing
- Post-hoc theorizing (HARKing)
- Model Reality Check: Plot raw data against predictions (Fig 1). Violations of linearity, homoscedasticity, or independence invalidate many claims.
- Reproducibility Proof: Demand shared scripts/notebooks. One study found 30% irreproducibility even with datasets.
{{IMAGE:5}} Figure 2: Misinterpreting overlapping confidence intervals as "no effect" is dangerously common—especially in underpowered studies. (Source: Anikin, 2025)
4. Conclusion Caveats: When Findings Overreach
- Null Fallacy: p > .05 ≠ evidence of no effect. Use equivalence testing or Bayes factors instead.
- Meta-Analysis Myths: Publication bias distorts reviews. Suspicious when:
- Effects vanish after removing extreme studies
- Salami-sliced papers inflate evidence
- Generalization Traps: Ask: "Would these findings hold for different stimuli, cultures, or contexts?" Over 80% of psychology studies use WEIRD (Western, Educated, Industrialized, Rich, Democratic) subjects.
The Tech Takeaway: Verify, Then Trust
While institutional reforms slowly address systemic issues, individual practitioners can:
- Separate Evidence from Interpretation: Instead of "X causes Y," cite "[Study] reports X-Y correlation in [specific context]."
- Demand Transparency: Require datasets, scripts, and preregistration for critical research.
- Embrace Uncertainty: Prioritize effect sizes with tight confidence intervals over binary "significant/non-significant" claims.
As the paper concludes: "Critical evaluation of published evidence prevents pursuing unproductive avenues and ensures better trustworthiness of science as a whole." In an era where AI-generated papers and paper mills proliferate, these skills aren't just academic—they're essential armor for navigating the research landscape.
Source: Anikin, A. (2025). Can I trust this paper? Psychonomic Bulletin & Review. DOI: 10.3758/s13423-025-02740-3
Comments
Please log in or register to join the discussion