
Voyage AI has released voyage-multimodal-3.5, an embedding model that adds explicit video support to its multimodal retrieval capabilities, claiming significant accuracy gains over competitors while introducing flexible dimensionality through Matryoshka embeddings.
The multimodal retrieval space has a new contender, and this time it's targeting video. Voyage AI has released voyage-multimodal-3.5, an update to its flagship multimodal embedding model that introduces explicit support for video frames while improving upon its predecessor's performance across text, image, and document retrieval tasks.
The announcement marks a significant expansion from voyage-multimodal-3, which the company released over a year ago as the industry's first production-grade model capable of embedding interleaved texts and images. That earlier model enabled search pipelines over PDFs, figures, tables, and document screenshots. Now, with video support, Voyage AI is positioning itself to handle the growing demand for video content retrieval in enterprise applications.

Architecture: A Unified Transformer Approach
Voyage-multimodal-3.5 maintains the same architectural philosophy as its predecessor: both visual and text modalities pass through a single transformer encoder. This unified architecture preserves contextual relationships between visual and textual information, enabling effective vectorization of interleaved content.
This approach stands in contrast to CLIP-based models, which route images and text through separate, independent model towers. CLIP-like models generate embeddings with a well-documented problem known as the modality gap, where text queries often retrieve irrelevant text over highly relevant images simply because text vectors sit closer to other text vectors in the embedding space.
By processing all inputs through the same backbone, voyage-multimodal-3.5 embeds text, screenshots, PDFs, figures, and videos into a shared vector space where similarity reflects semantic meaning rather than modality.
Video Embedding: Technical Implementation
The model represents videos as ordered sequences of frames, with every 1120 pixels counting as one token. The maximum context length is 32,000 tokens, which imposes practical limits on video length and resolution.
Voyage AI provides specific recommendations for video embedding:
Scene segmentation: Videos exceeding 32k tokens should be split into segments containing related frames and corresponding transcript text. Each segment should capture a complete thought or topic.
Transcript alignment: When transcripts are available, align segment boundaries with natural breaks in the spoken content to maintain semantic coherence.
Resolution management: For semantically continuous scenes that still exceed token limits, reduce resolution or frames-per-second to stay within constraints.
The company provides a code snippet in their appendix demonstrating how to implement these strategies using the voyageai package, and offers a sample notebook for more sophisticated video embedding examples.
Matryoshka Embeddings and Quantization
One notable technical advancement is support for Matryoshka embeddings, which allow flexible dimensionality at 2048, 1024, 512, and 256 dimensions while minimizing quality loss. This enables developers to trade off embedding size against retrieval accuracy based on their specific constraints.
The model also supports multiple quantization options: 32-bit floating point, signed and unsigned 8-bit integer, and binary precision. This flexibility is particularly valuable for production deployments where memory and computational resources are constrained.
Evaluation: Claims Against Competitors
Voyage AI evaluated voyage-multimodal-3.5 across 18 multimodal datasets spanning two tasks: visual document retrieval and video retrieval. They also tested on 38 standard text retrieval datasets across law, finance, conversation, code, web, and tech domains.
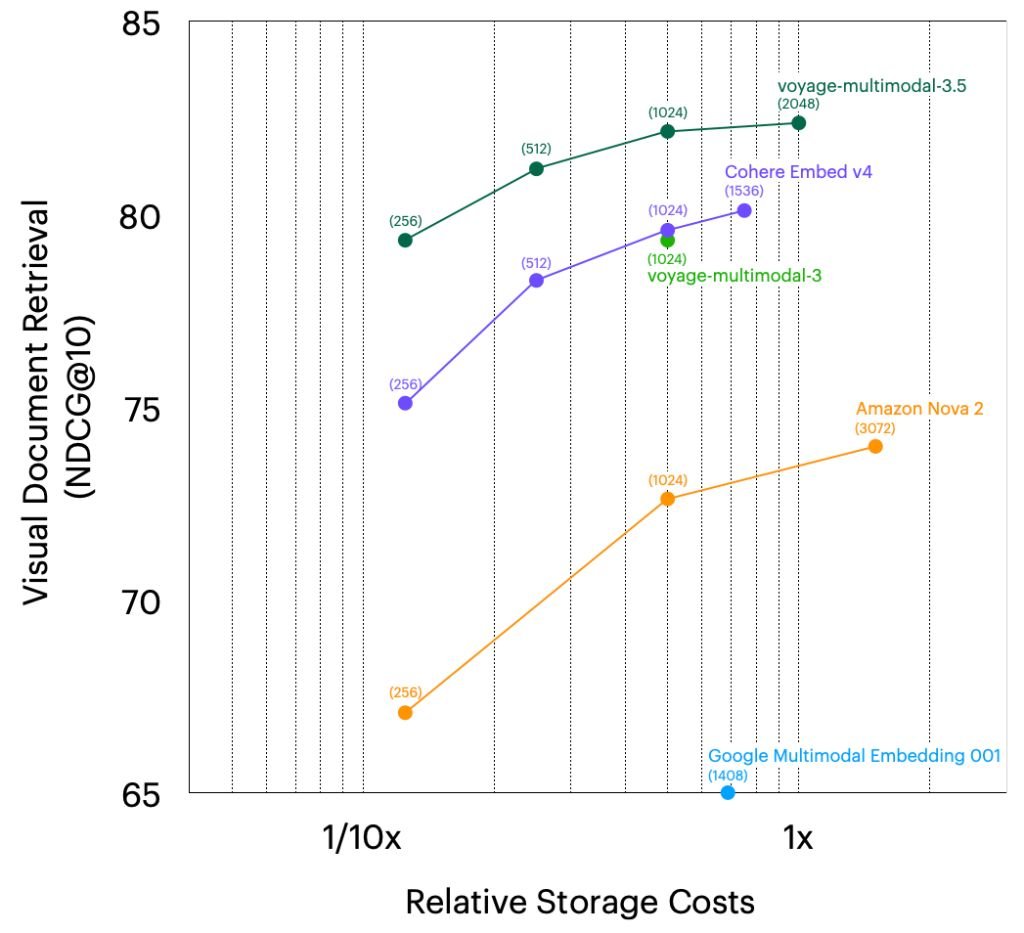
Visual document retrieval: The model reportedly outperforms Google Multimodal Embedding 001 by 30.57%, Cohere Embed v4 by 2.26%, Amazon Nova 2 Multimodal by 8.38%, and its predecessor voyage-multimodal-3 by 3.03%.
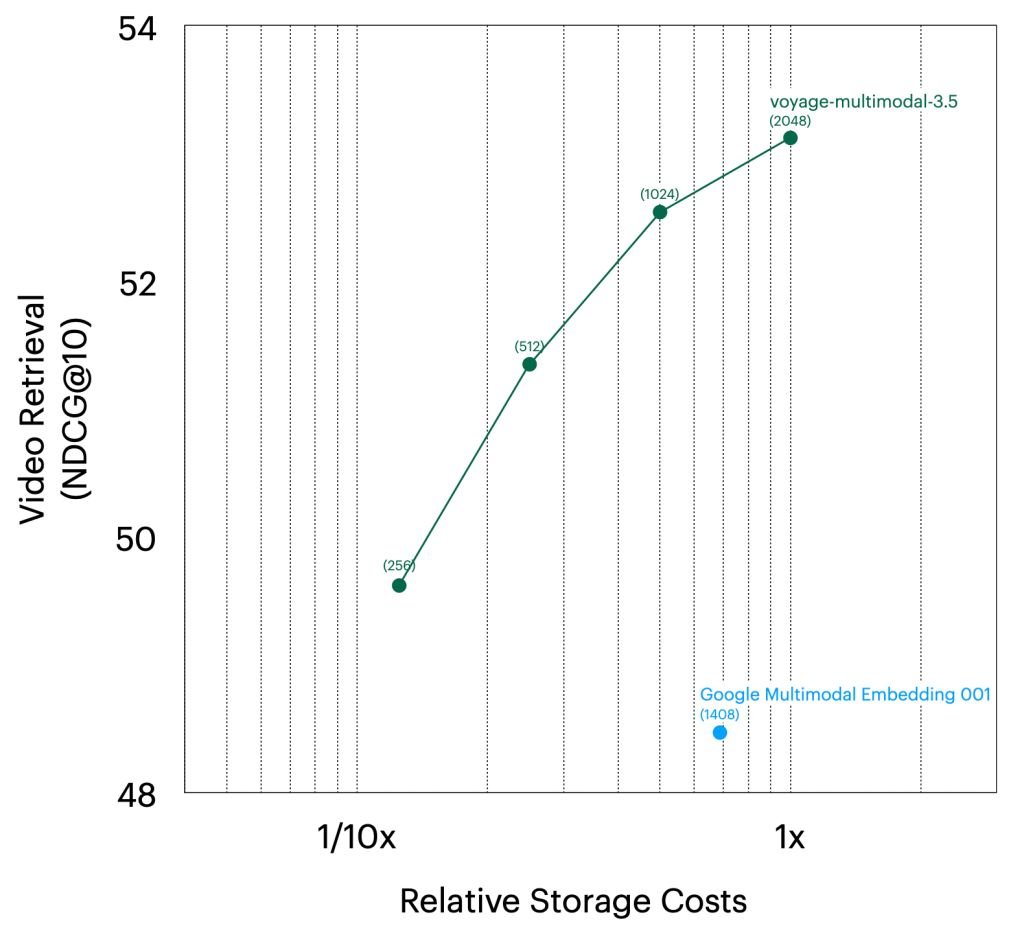
Video retrieval: Voyage-multimodal-3.5 claims a 4.65% improvement over Google Multimodal Embedding 001 on video retrieval datasets (MSR-VTT, YouCook2, and DiDeMo), while being approximately six times cheaper per video at 512×512 resolution.
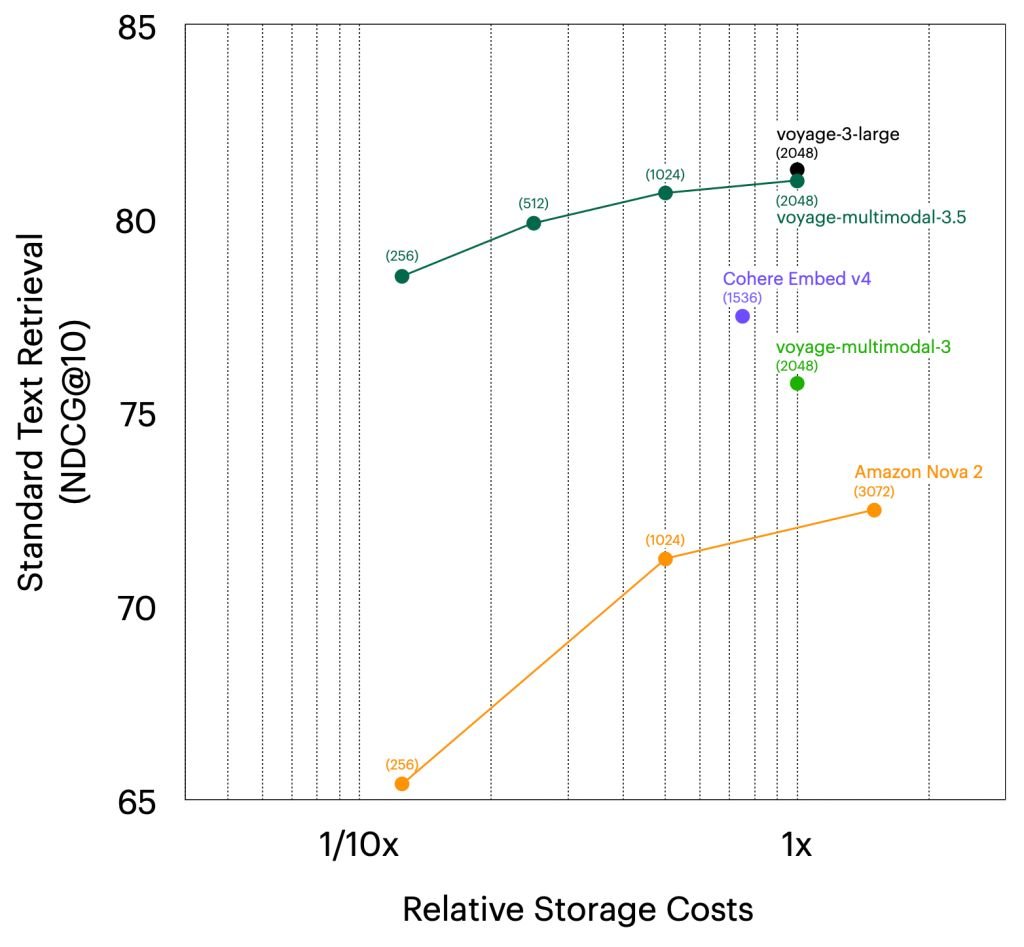
Standard text retrieval: The model outperforms Cohere v4 by 3.49%, Amazon Nova 2 Multimodal by 8.48%, and voyage-multimodal-3 by 5.22%. Its performance is within 0.29% of voyage-3-large, the company's current state-of-the-art text embedding model, while being $0.06 cheaper per million tokens.
Counter-Perspectives and Considerations
While the benchmarks look impressive, several factors warrant consideration. First, the evaluation relies on Voyage AI's own reporting across their specified datasets. Independent verification would strengthen these claims, particularly as the field of multimodal retrieval continues to evolve rapidly.
Second, the 32,000 token limit for video processing imposes practical constraints. For high-resolution or long-form video content, developers must implement segmentation strategies that could introduce edge cases where scene boundaries don't align perfectly with semantic breaks.
Third, the cost advantage of six times cheaper per video depends on specific resolution and processing parameters. The comparison to Google Multimodal Embedding 001 uses 512×512 resolution, but real-world applications might require higher resolutions for certain use cases.
Finally, the modality gap problem that Voyage AI highlights in CLIP-based models is real, but competing solutions from companies like Cohere and Google are also evolving. The 2.26% improvement over Cohere Embed v4, while statistically meaningful in benchmarks, might not translate to dramatic differences in all production scenarios.
Production Readiness and Pricing
Voyage-multimodal-3.5 is available immediately with token-based pricing. The first 200 million tokens and 150 billion pixels are free, providing a substantial trial period for development and testing.
The model's production-grade status is reinforced by its support for multiple embedding dimensions and quantization options, which are essential for real-world deployment where resource constraints matter.
The Broader Pattern
This release reflects a broader trend in the AI industry toward unified multimodal models that can handle multiple content types within a single architecture. As organizations accumulate increasingly diverse data—text documents, images, screenshots, and now videos—the ability to search across all these formats with a single query becomes more valuable.
Voyage AI's approach of avoiding the modality gap through a unified transformer architecture represents one technical path forward. Competing approaches, including separate but aligned models, also have their merits and trade-offs.
The addition of video support is particularly timely given the explosion of video content in enterprise settings, from training materials and product demos to recorded meetings and marketing content. The ability to perform semantic search across video libraries could unlock significant value for organizations with large video archives.
Getting Started
Developers interested in testing voyage-multimodal-3.5 can start with the company's documentation and sample notebook. The model is accessible through the voyageai Python package, with video embedding utilities included in the video_utils module.
The free tier provides ample room for experimentation, and the flexible pricing model allows scaling based on actual usage rather than fixed commitments.
As multimodal retrieval continues to mature, voyage-multimodal-3.5 represents a concrete step toward making video content as searchable as text and images. Whether it maintains its performance advantage as competitors respond will be the real test of its long-term impact on the developer and tech community.
Comments
Please log in or register to join the discussion