Most lead scoring systems are too permissive, rewarding basic field presence and applying light penalties to risk signals. This creates false positives and erodes sales trust. A stricter, deterministic approach that weighs bad signals more heavily than good ones produces clearer classifications and better decision support.
Most lead scoring systems are permissive by design. They reward basic field presence — email detected, phone detected, name detected — and apply relatively light penalties to risk signals. The result is predictable: too many leads end up classified as “high quality”. When everything looks good, nothing stands out. Sales teams stop trusting the score. “Medium” and “High” become cosmetic labels, and the scoring system turns into decoration instead of decision support.
There is another way to approach it.
Conservative by Design
A stricter scoring philosophy starts from a simple principle: Bad signals should weigh more than basic presence signals. Free email domains should reduce trust. Missing traffic source should matter. Identity mismatches should not be ignored. Suspicious patterns should meaningfully affect the result. At the same time, field presence alone should not inflate the score. Positive signals should be capped. Consistency bonuses should be conditional.
The goal is not to reject more leads. The goal is to protect sales time. It is better to review a borderline lead than to confidently prioritize the wrong one.
Beyond Simple Validation
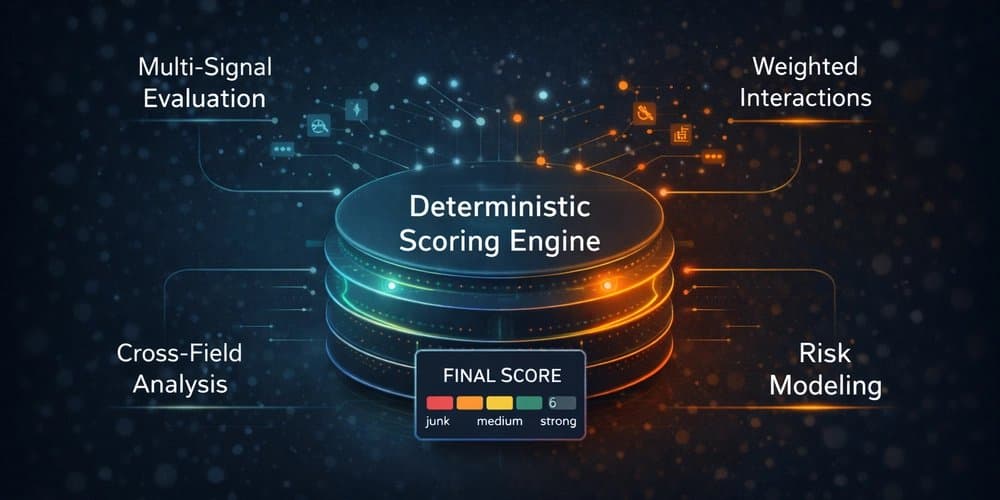
Strict scoring does not mean simple rule matching. A robust lead scoring engine evaluates multiple signal layers simultaneously:
- Identity coherence across fields
- Domain trust layers and structural validation
- Cross-field consistency checks
- Contextual risk weighting
- Behavioral and intent indicators
- Pattern analysis beyond basic regex validation
No single signal determines the outcome. The final score is the result of weighted interactions between signals, not isolated checks. That layered approach is what makes strict scoring reliable rather than arbitrary.
Clear Classification Levels
A strict model benefits from clear and meaningful classification buckets:
- Likely Junk
- Medium Risk
- High Quality
- Strong Lead
“Strong Lead” should be rare. It should require consistent identity, a business domain, no critical risk signals, and coherent structured data. If everything becomes “High”, the classification loses value. Scarcity creates meaning.
Structured Decision Signals
Another important aspect is how the scoring output is structured. Instead of mixing all signals into a single list, it is clearer to separate:
- Risk signals
- Positive signals
This makes it easier to build routing logic, trigger automation rules, prioritize leads inside a CRM, and filter data before enrichment. The scoring system becomes easier to reason about and easier to integrate.
Determinism Still Has Value
In an era of AI-driven black-box models, determinism is sometimes overlooked. A deterministic scoring engine guarantees:
- Same input. Same output.
- No randomness.
- No drift.
- No unexplained variation.
For operational workflows, that predictability matters. It allows teams to build logic and automation with confidence.
Why Strictness Improves Decision-Making
Strict lead scoring is not about being harsh. It is about clarity. If a lead is classified as High or Strong, it should truly deserve attention. If it is Medium, it should invite human judgment. If it is Junk, it should be obvious why.
Lead scoring should support prioritization, not blur it. The more meaningful the classification, the more useful the system becomes.
Lead scoring does not guarantee conversion. It reduces the cost of being wrong.
If you’re interested in exploring how a deterministic scoring engine can fit into your workflow, you can find more details at leadflags.com.
Comments
Please log in or register to join the discussion