Microsoft introduces a novel orchestration pattern that ensures critical workloads execute first on shared Spark pools without infrastructure changes.
The Shared Spark Conundrum
In cloud data platforms like Azure Synapse, organizations face a fundamental tension: While shared Spark pools optimize cost and resource utilization, they inherently create unpredictable execution patterns. When pipelines compete for resources simultaneously, continental drift occurs between business priorities and actual processing order. Critical dashboards stall while heavy backfills consume resources simply because they requested executors milliseconds earlier.
Priority as Execution Sequencing
The solution shifts focus from Spark tuning to orchestration intelligence. Instead of modifying Spark configurations or notebook logic, this approach controls when workloads enter the shared pool. Business-critical pipelines gain priority through sequential admission:
Classification first: Workloads are tagged by business impact:
- Light: SLA-sensitive dashboards (low data volume, high priority)
- Medium: Core reporting (moderate volume)
- Heavy: Backfills (high volume, best-effort)
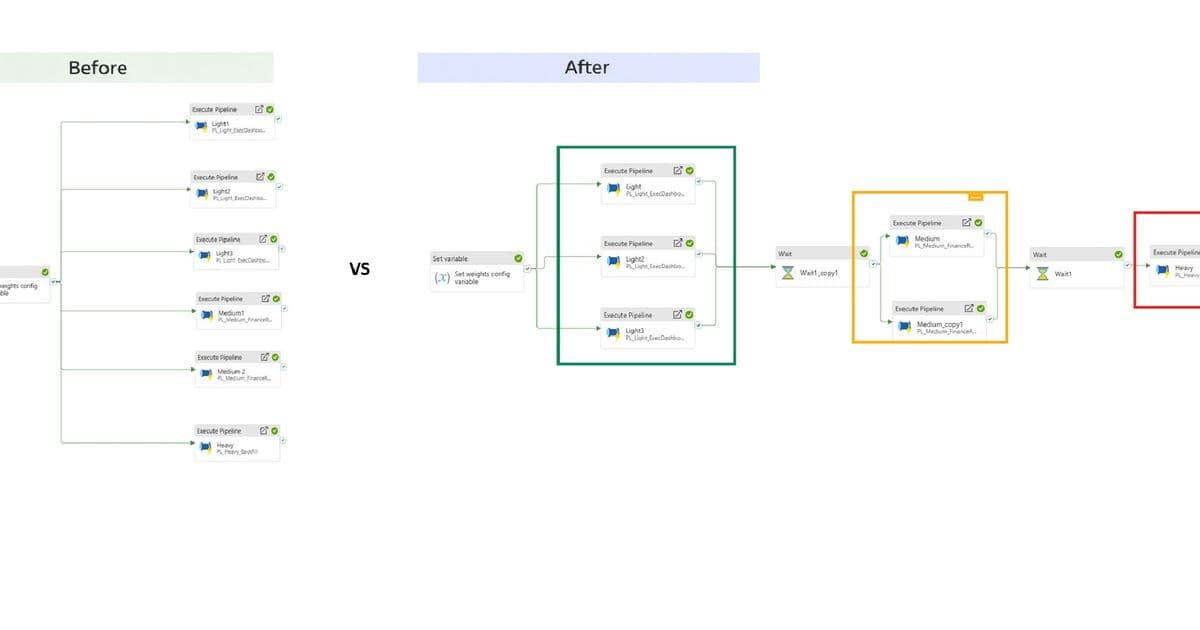
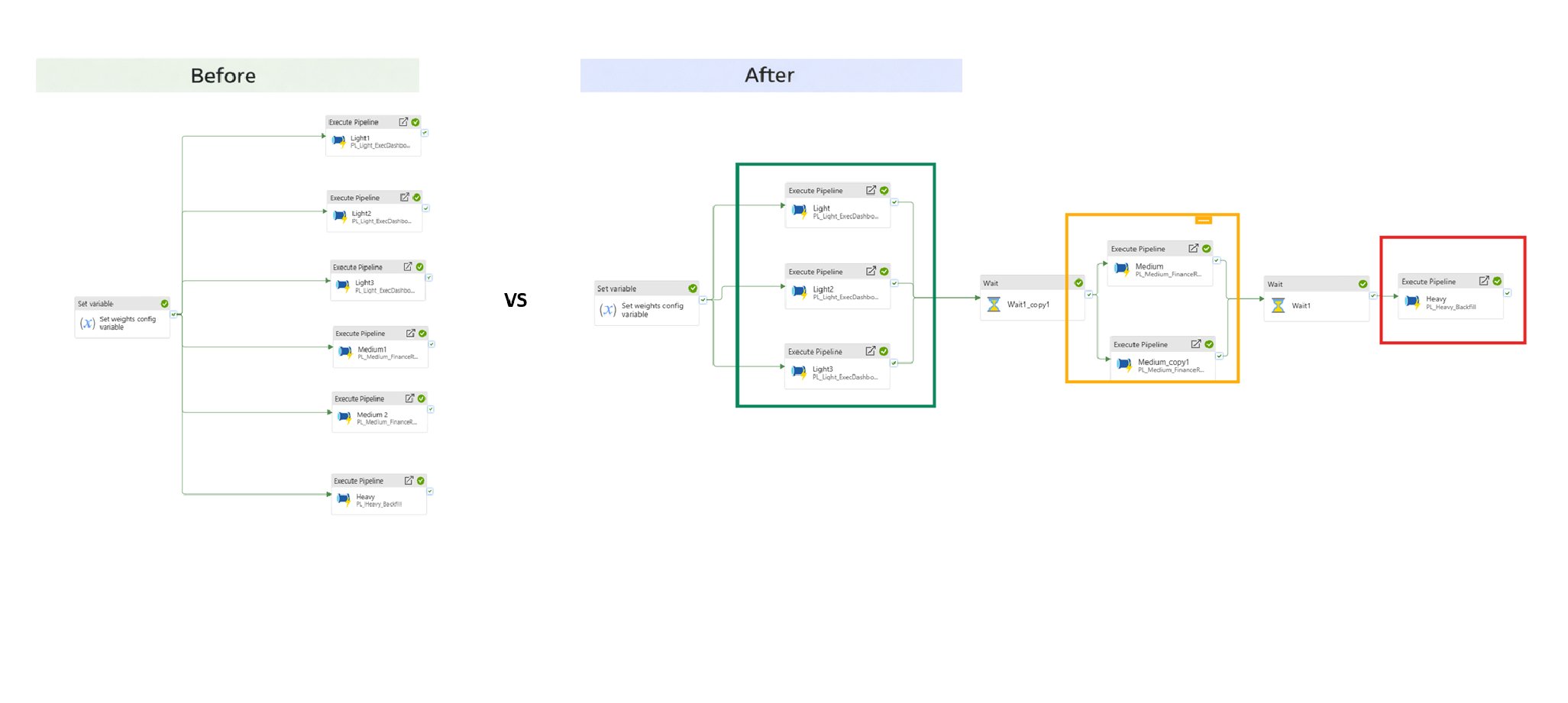
Sequential admission: Orchestration enforces strict ordering:
 Light → Medium → Heavy
Light → Medium → HeavyParallelism within tiers: Similar-priority pipelines run concurrently, preserving efficiency
Impact Analysis: Naïve vs Priority-Aware
| Metric | Naïve Orchestration | Priority-Aware |
|---|---|---|
| Light workload duration | 20-30 minutes | 2-3 minutes |
| Execution predictability | Random under load | Deterministic |
| Spark configuration changes | None | None |
| Cluster utilization | Unchanged | Unchanged |
As shown in pipeline run visualizations ( ), priority-aware orchestration eliminates queueing delays for critical workloads without altering Spark behavior. Light workloads complete faster because they avoid executor contention entirely.
), priority-aware orchestration eliminates queueing delays for critical workloads without altering Spark behavior. Light workloads complete faster because they avoid executor contention entirely.
Strategic Advantages
- Cost preservation: Maintains shared pool efficiency while adding business alignment
- Adaptive classification: Telemetry can dynamically reclassify unstable pipelines
- Multi-cloud applicability: Pattern transfers to AWS EMR or Databricks with minimal adjustments
- Failure isolation: Problematic workloads automatically downgraded to prevent cascading delays
Implementation Pathway
- Static classification: Start with manual tagging using metadata schemas
- Telemetry integration: Collect execution metrics via Azure Monitor
- Adaptive prioritization: Implement Copilot-style agents for classification recommendations
- Heavy workload optimization: Scale executor counts exclusively for non-critical jobs
Beyond Azure: Cross-Cloud Relevance
While demonstrated in Azure Synapse, this orchestration pattern applies to any shared Spark environment:
- AWS: Implement via Step Functions controlling EMR jobs
- GCP: Replicate with Cloud Composer managing Dataproc
- Databricks: Apply using Delta Live Tables orchestration
The core principle remains: Execution order determines effective priority in shared environments.
Future Evolution
The framework enables policy-driven enhancements:
- SLA-based admission: Automatically prioritize workloads nearing SLA breach
- Cost-awareness: Delay high-cost transformations during peak billing periods
- Resource borrowing: Allow lower tiers to use idle capacity from higher tiers
Conclusion
Shared Spark environments don't require resource silos to achieve predictability. By shifting priority enforcement to the orchestration layer, organizations maintain cost efficiency while ensuring business-critical pipelines execute first. This approach provides deterministic behavior without infrastructure changes, forming a foundation for intelligent, policy-driven data platforms.
Resources:
Comments
Please log in or register to join the discussion