
AWS gives S3 customers a new way to attach large, queryable metadata to objects without running a separate catalog service.

AWS announced Amazon S3 annotations Tuesday, giving customers a way to attach business context, AI output, compliance notes and technical metadata to objects in Amazon S3.
The feature raises S3 metadata from small headers and tags to named annotation payloads. Each object can hold up to 1,000 annotations, and each annotation can reach 1 MB. An object can carry up to 1 GB of annotation data in JSON, XML, YAML or plain text.
Teams can add, update or delete an annotation without rewriting the object. That matters for media libraries, research archives and regulated datasets where metadata changes after upload.
S3 already gives customers system metadata, user metadata and object tags. System metadata covers object facts such as size and storage class. User metadata supports small custom values at upload. Object tags support lifecycle rules, access control and cost allocation.
Annotations serve a different job. A media team can attach transcripts, subtitle data, content ratings and codec details to the same video object. A financial services team can attach investment summaries and sentiment analysis to research PDFs. A life sciences team can attach trial cohort details and approval records to archived data.
AWS also ties annotations to S3 Metadata tables. Customers who enable annotation tables can query annotation data through Amazon Athena and engines that support Apache Iceberg. S3 places annotation content into managed tables, with each annotation represented as a row.
That design changes the catalog trade-off. Many companies store S3 context in sidecar files, relational databases or search indexes. Those systems need sync jobs, permissions work and failure handling. S3 annotations reduce that burden by keeping context with the object through copy, replication and cross-Region transfers.
The strongest use case sits in AI data discovery. An agent needs context before it can choose the right file. File names and folder paths often fail that test. An annotation can hold a transcript, schema summary, patient cohort note or product classification that an agent can query before it retrieves the object.
AWS said customers can query annotations for objects in any storage class without restoring the object or paying retrieval charges. That gives S3 Glacier users a practical audit path: compliance staff can search archived context without pulling the underlying data back into active storage.
The provider comparison favors AWS for customers who already use S3 as their system of record. Object stores from Microsoft Azure and Google Cloud support metadata and labels, but AWS now offers a larger per-object context model tied to managed Iceberg tables. Customers with multi-cloud estates should compare query paths, metadata limits, IAM controls and table formats before they standardize on one provider’s object metadata model.
Cost also needs attention. AWS bills annotation storage at S3 Standard rates, even when the parent object uses S3 Glacier or another lower-cost storage class. A team that attaches large AI summaries to billions of objects can create a material storage line item. Platform teams should set annotation naming rules, size budgets and retention policies before they let enrichment jobs write at scale.
Developers can call PutObjectAnnotation, GetObjectAnnotation, ListObjectAnnotations and DeleteObjectAnnotation through the S3 API. Teams need IAM permissions such as s3:PutObjectAnnotation and s3:GetObjectAnnotation before applications can write or read annotation data.
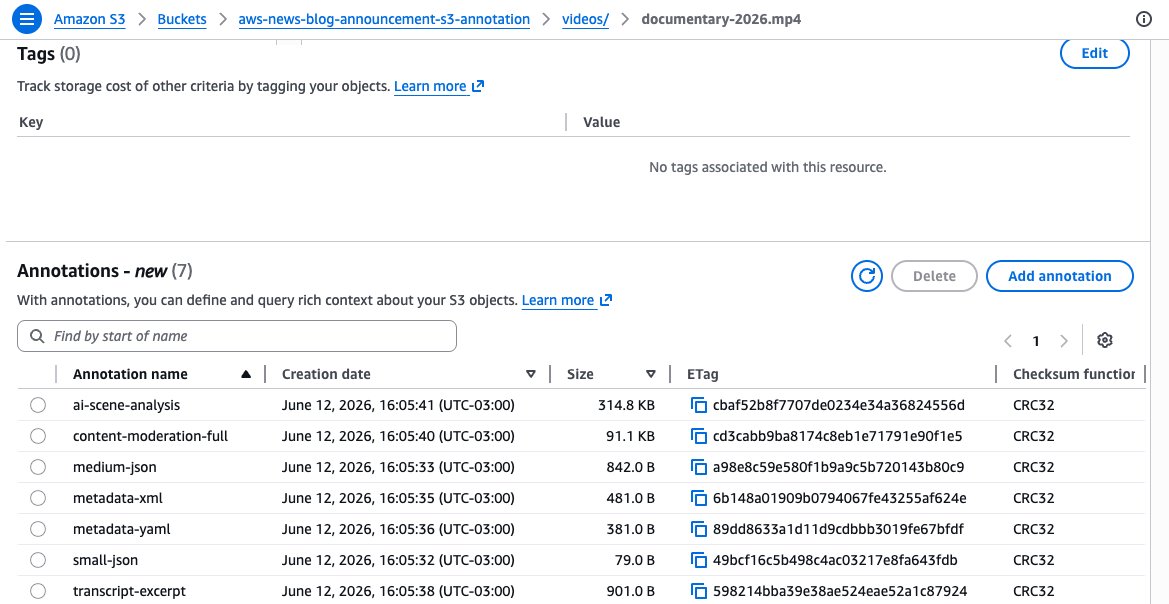
A media workflow shows the pattern. One process can attach a mediainfo annotation with codec, resolution, audio track count and frame rate. Another process can attach an ai_summary annotation with a text description. Each workflow owns its annotation name and can update its payload without touching the video.
Athena queries then become business queries. A media operations team can search for all 4K assets with more than eight audio tracks. A compliance team can find objects with missing approval records. A research team can filter documents by AI-generated topic summaries.
S3 annotation tables refresh within about one hour, while journal tables track annotation changes close to event time. That split gives teams two modes: broad analytical queries across the annotation table and workflow triggers from the journal table.
For migration planning, teams should start with metadata that already causes sync pain. Good candidates include transcripts, compliance status, data quality scores, media technical specs and AI-generated summaries. Poor candidates include values that drive lifecycle or access policies today, because object tags already fit that role.
The rollout also affects architecture reviews. Data teams can retire some custom metadata stores if S3 annotations cover their query and governance needs. Security teams still need to review IAM access, annotation content risks and cross-Region behavior. Finance teams need to model annotation storage growth before AI enrichment jobs run across old buckets.
AWS says S3 annotations are available in all AWS Regions, including AWS China Regions. Annotation tables are available in Regions that support S3 Metadata. Customers can review Amazon S3 pricing and the Amazon S3 user guide before production rollout.
Comments
Please log in or register to join the discussion