The recent 40 % drop in Nvidia H200 rental rates has sparked two very different forecasts for the next phase of AI development. One view sees a pull‑back in speculative token‑maxxing and a shift toward cost‑focused, narrow‑AI deployments. The other bets on a resurgence driven by new hardware efficiencies and emerging foundation‑model ecosystems. Both predictions have merit, but each also rests on assumptions that may not survive the coming year.
What’s being claimed
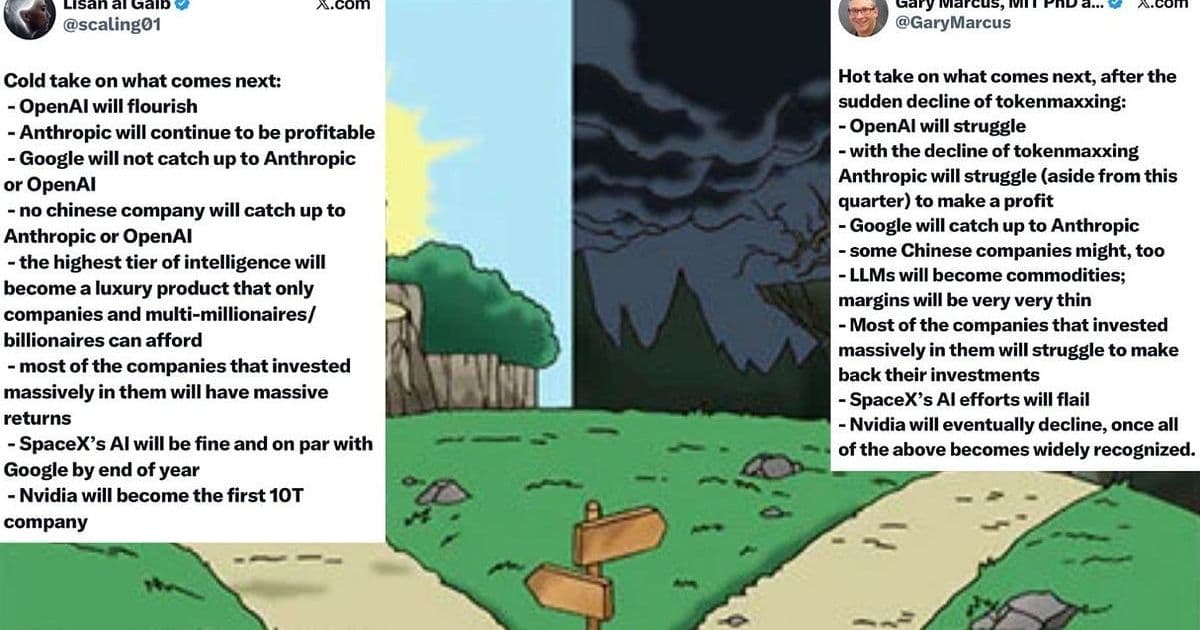
Claim 1 – Market correction: The price to rent an Nvidia H200 GPU fell from $7 / hr to $4 / hr in three weeks, a 40 % slide that, according to several analysts, signals the end of the token‑maxxing boom – the practice of feeding ever‑larger language models with massive token streams to chase marginal performance gains.
Claim 2 – Diminishing ROI: A Financial Times model of hyperscaler AI investment (2025‑2030) shows that, under “best‑case” assumptions (zero operating costs, revenue only versus capex), only one of the major cloud providers still expects a positive return on AI spend.
Claim 3 – Divergent forecasts: Gary Marcus (the author of the original essay) offers a cautious outlook: a retreat to smaller, task‑specific models and a focus on efficiency over raw scale. In contrast, Lisan al‑Gaib, a benchmark creator, predicts a rapid rebound driven by next‑gen hardware (e.g., Nvidia H100‑plus, custom ASICs) and a new wave of open‑source foundation models.
What’s actually new?
1. The hardware price shock is real, but context matters
The Nvidia H200 is a single instance of the latest Hopper‑based GPU, marketed for high‑throughput inference and training. Its rental price is a proxy for the broader compute market, yet it does not capture:
- Supply‑side dynamics: Nvidia’s recent production ramp‑up, combined with a slowdown in AI‑driven capital expenditures, has created a temporary oversupply.
- Alternative accelerators: Companies such as Graphcore, SambaNova, and AMD are releasing competing chips that may further depress prices.
- Geographic variance: The quoted rates are for US‑based cloud zones; European and Asian markets still show higher price points.
2. ROI calculations are highly sensitive to assumptions
The FT analysis assumes a linear revenue curve and ignores several cost components that can swing the outcome dramatically:
- Energy costs: Power consumption for large clusters can vary by 20‑30 % depending on regional electricity rates.
- Software licensing: Proprietary model‑serving stacks add hidden OPEX that the model treats as zero.
- Product‑market fit: Revenue from AI‑augmented SaaS products is not a given; many pilots still sit in beta.
A more nuanced model that incorporates these variables often yields a break‑even scenario rather than a clear loss.
3. The two forecasts differ in their baseline assumptions
| Aspect | Marcus’s “efficiency‑first” view | Lisan al‑Gaib’s “hardware‑driven resurgence” view |
|---|---|---|
| Core premise | Token‑maxxing is unsustainable; future growth will come from model compression, distillation, and domain‑specific fine‑tuning. | New hardware will restore the economics of scaling, and open‑source foundations will democratize access, reigniting the token‑maxxing cycle. |
| Key evidence | Recent price drops, slower capex, and a rise in edge‑AI deployments (e.g., TinyML, on‑device inference). | Roadmaps from Nvidia (H200‑plus), Intel (Gaudi 3), and emerging AI‑specific silicon from startups like Cerebras and Groq. |
| Risk factors | Over‑reliance on compression may limit breakthrough capabilities; regulatory scrutiny on data‑intensive training could tighten further. | Hardware supply chain bottlenecks, and the possibility that software ecosystems lag behind the silicon advances. |
Both positions acknowledge the same data points but extrapolate in opposite directions.
Limitations and what to watch in the next 12 months
- Short‑term price volatility – GPU rental rates can swing with quarterly inventory moves. A single three‑week snapshot does not guarantee a sustained trend.
- Capital‑intensive lag – Even if hardware becomes cheaper, the time to design, fabricate, and ship new chips is measured in years. The next generation of H200‑plus may not be widely available until late 2027.
- Software bottlenecks – Model scaling is not only a hardware problem. Frameworks (PyTorch, JAX) and compiler stacks (TVM, XLA) must evolve to exploit new architectures efficiently.
- Regulatory environment – Emerging EU AI Act provisions could impose additional compliance costs that offset hardware savings.
- Market signals – Watch for:
- Quarterly reports from AWS, Azure, and Google Cloud on AI‑specific instance utilization.
- Nvidia’s earnings call (typically in May) for guidance on H200 inventory and pricing strategy.
- Publication of new benchmark suites (e.g., MLPerf Training v4.0) that may shift focus from raw FLOPs to energy‑per‑token metrics.
Bottom line
The collapse of H200 rental prices is a clear indicator that the token‑maxxing era is under pressure, but it does not automatically herald a permanent retreat from large‑scale models. Two plausible paths lie ahead:
- Efficiency‑first trajectory: Companies double down on model compression, edge deployment, and domain‑specific fine‑tuning, leading to a more fragmented AI ecosystem with many specialized, lower‑cost models.
- Hardware‑driven resurgence: New accelerator generations and open‑source foundations restore the economics of scaling, potentially reviving token‑maxxing in a more sustainable form.
Which path dominates will depend on how quickly the hardware supply chain stabilizes, how effectively software stacks can harness new silicon, and whether regulatory pressures tilt the cost‑benefit balance toward smaller, more efficient models.
Stay tuned for a follow‑up in 12 months to see which prediction holds up.

Comments
Please log in or register to join the discussion