
Model Best's open-source BitCPM-CANN framework demonstrates practical 1.58-bit precision training on Chinese AI accelerators, potentially reducing memory requirements by up to six times amid rising HBM costs and export restrictions.
Model Best has open-sourced BitCPM-CANN, a complete training framework that enables 1.58-bit model training on domestic Chinese AI accelerators. This development comes at a critical time when HBM memory prices have surged over 165% year-over-year in 2026, making memory bandwidth one of the most expensive and constrained resources for AI training.
Technical Significance of 1.58-Bit Precision
1.58-bit precision represents an extreme quantization approach where model parameters are represented using just 1.58 bits per parameter. This contrasts with the standard 32-bit floating-point format used in most contemporary AI models, which would theoretically require over 20 times more memory for the same model size. The framework's claim of reducing inference memory requirements by up to six times compared to full-precision training suggests a sophisticated approach to quantization that goes beyond simple post-training quantization.

The technical achievement lies in enabling training at such low precision, not just inference. Training at 1.58 bits presents significant challenges:
- Gradient computation becomes extremely noisy
- Information loss during backpropagation
- Numerical stability issues
- Specialized optimization algorithms required
BitCPM-CANN appears to address these challenges through a combination of techniques likely including:
- Custom quantization-aware training algorithms
- Novel gradient approximation methods
- Hardware-specific optimizations for the target accelerators
- Possibly mixed-precision strategies that maintain higher precision for critical components
Context: China's AI Hardware Constraints
The timing of this release is particularly significant given the export controls that have restricted Chinese companies' access to high-end NVIDIA chips. This has pushed the Chinese AI industry toward homegrown alternatives like Huawei Ascend processors, which face their own memory bandwidth and compute constraints compared to state-of-the-art NVIDIA GPUs.
The "CANN" in BitCPM-CANN refers to the Compute Architecture for Neural Networks, indicating tight integration with specific domestic AI chip architectures. This integration is crucial for achieving practical performance, as extremely low-precision training requires careful coordination between software algorithms and hardware capabilities.
Practical Implications
For China's AI ecosystem, the practical implications are considerable. If 1.58-bit training can be validated at scale, it could substantially reduce the memory bottleneck that has constrained model development for companies without access to the latest high-bandwidth hardware. This would enable:
- Training larger models on existing hardware
- Reducing hardware costs for AI development
- Making advanced AI more accessible to organizations with limited budgets
- Potentially enabling edge deployment of large models
The open-source release includes full training code, pretrained checkpoints, and evaluation benchmarks, allowing other researchers and companies to replicate the results on their own hardware. This transparency is valuable for the research community to independently verify the claims and build upon the work.
Technical Challenges and Limitations
Despite the promising claims, several questions remain about the practical implementation:
Accuracy Trade-offs: While the framework claims significant memory reduction, the impact on model accuracy at such extreme quantization levels needs thorough evaluation across different model architectures and tasks.
Hardware Specificity: The tight integration with domestic accelerators may limit portability to other hardware platforms, potentially creating vendor lock-in.
Training Efficiency: The computational overhead of maintaining 1.58-bit precision during training may offset some memory benefits, especially if specialized hardware is required.
Scalability: Demonstrating 1.58-bit training on smaller models doesn't guarantee the same success with larger, more complex models that might be more sensitive to quantization artifacts.
Broader Industry Context
BitCPM-CANN advances the broader industry conversation around quantization-aware training and extremely low-precision inference as genuine alternatives to the conventional full-precision paradigm. It represents one approach to addressing the growing memory bottleneck in AI, alongside innovations like:
- Sparse model training
- Memory-efficient attention mechanisms
- Novel data types (like NVIDIA's BF16 or custom formats)
- Architectural innovations that reduce inherent memory requirements
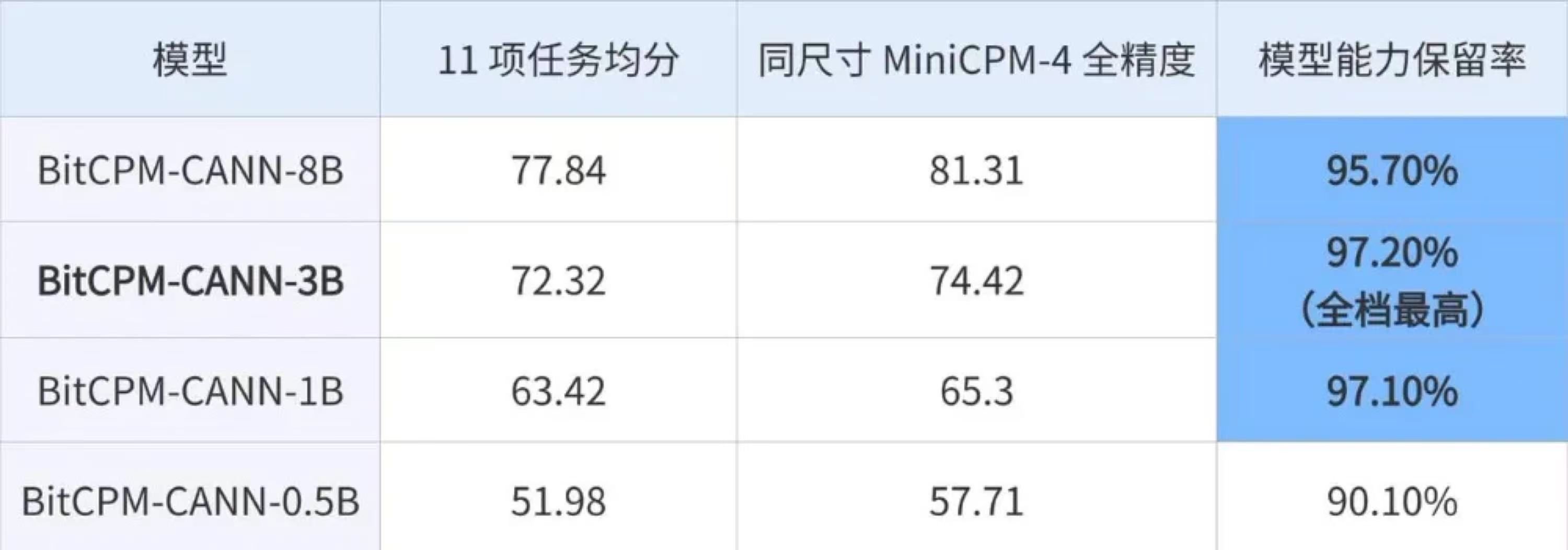
The framework also contributes to the growing body of research on efficient AI that prioritizes practical deployment considerations over raw performance metrics. As AI models continue to grow in size and complexity, techniques like those demonstrated in BitCPM-CANN will become increasingly important for making advanced AI accessible beyond well-resourced organizations.
For researchers and practitioners interested in exploring this approach, the open-source codebase provides an opportunity to examine the implementation details and potentially adapt the techniques to other hardware platforms or model architectures. The framework's success will ultimately depend on empirical validation across diverse workloads and its ability to maintain performance while delivering on the promised memory reductions.
Comments
Please log in or register to join the discussion