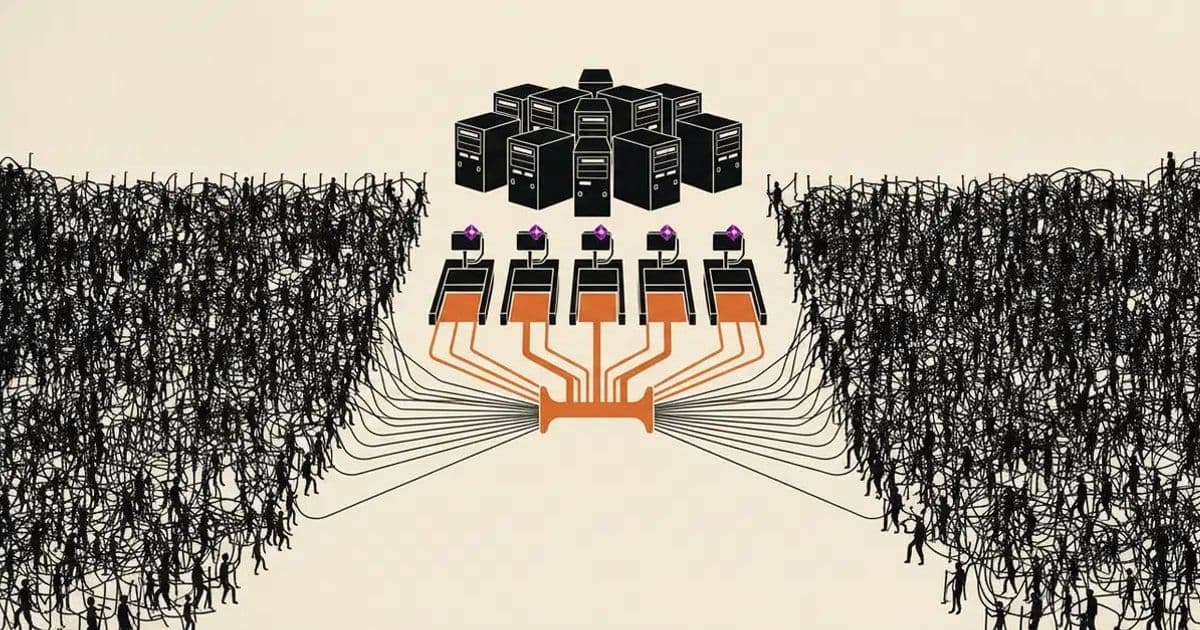
A common mistake is inflating database connection pools, which harms latency and throughput; the correct sizing uses a core‑based formula, headroom, and a pooler, with load testing to confirm.
Featured image: 
The database shows 30 percent CPU usage while the application experiences timeouts. A suggestion to increase the connection pool from fifty to two hundred makes latency worse, and throughput drops even though CPU stays at the same level. This pattern repeats across many production systems and represents the most common database‑tuning mistake. The HikariCP team documented the phenomenon years ago; the smaller pool was faster. An Oracle real‑world demo showed response time falling from roughly one hundred milliseconds to about two milliseconds when the connection count was reduced, and a PostgreSQL benchmark revealed that throughput flattens near fifty connections while additional connections provide no benefit. The cause is physical limitation, not configuration.
Why a larger pool slows the system
A PostgreSQL backend runs as a process that needs a CPU core while executing a query. The number of physical cores in the server is fixed. If eight cores are available and two hundred active connections attempt to run queries, the operating system time‑slices the work among them. Each query receives only a fraction of a core, then is paused while the scheduler runs another query. Frequent context switches increase overhead, cause cache line evictions, and raise disk and lock contention because many transactions remain open simultaneously. The hardware performs the same amount of work regardless of pool size; adding connections only creates queuing inside the database, which is invisible to the application and beyond direct control.
Think of a grocery store with eight checkout lanes and eight cashiers. Opening forty additional lanes does not help if the cashiers remain eight; you end up with forty half‑staffed lanes and confused customers. The optimal number of lanes matches the number of cashiers, with a small buffer for peak demand.
The cores‑based formula
The PostgreSQL community formula, cited by HikariCP, is:
connections = (core_count * 2) + effective_spindle_count
core_count represents physical cores, not hyperthreads. effective_spindle_count approximates the number of disks that can serve concurrent I/O. On SSD or cloud block storage treat this as a modest constant rather than a literal spindle count, because a query waiting on I/O frees its core for another query. The multiplier two reflects the fact that while some connections wait for disk, others can use the CPU.
Worked example
Consider a db.r6g.2xlarge instance with eight vCPUs and gp3 storage:
core_count = 8 (vCPUs; see note below) effective_spindle_count ≈ 4 (SSD allows I/O overlap)
connections = (8 * 2) + 4 = 20
Twenty connections, not two hundred, is the recommended starting point for most OLTP workloads. The instinct to set the pool in the hundreds is the bug.
Cloud caveat
A vCPU is typically a hyperthread, not a full physical core. Some managed instances expose half as many physical cores as vCPUs. For a conservative estimate use physical cores. The formula provides a starting point, not a final value; confirm it with a load test.
Per‑database ceiling, not per‑application ceiling
The formula sizes connections that actually reach PostgreSQL. If ten application instances each open a pool of twenty, the total backend demand becomes two hundred. This can exceed max_connections and cause errors such as FATAL: sorry, too many clients already. The real budget is:
total_backends = pool_size_per_instance * instance_count
Keep this total below max_connections, allowing headroom for migrations, administrative sessions, and replication.
Two ways to stay within limits
- Reduce the per‑instance pool so the product fits under max_connections.
- Place a pooler in front of the application so that the app’s pool count and PostgreSQL’s backend count are no longer identical.
The second option is the focus of the remainder of this article.
Serverless connection storm
In serverless environments such as AWS Lambda, Cloud Run, or Fly Machines, each concurrent request can spin up a fresh worker. Each worker typically requests a database connection, and there is no long‑lived process holding a tidy pool. A traffic spike to four thousand concurrent invocations may generate four thousand connection attempts hitting PostgreSQL at once. PostgreSQL struggles with this burst because each connection consumes memory and a backend process before any query runs. The handshake involving TCP, TLS, and SCRAM authentication is not free, and a sudden surge of handshakes creates a thundering herd. When max_connections is reached, requests begin to fail, the platform retries, and the retries amplify the storm.
A pooler resolves the issue by maintaining a small set of real backends and multiplexing many short‑lived clients across them. The serverless function connects to the pooler, which then talks to PostgreSQL with a stable, sized pool.
AWS positions RDS Proxy as a solution that manages connection bursts that would otherwise overwhelm the database’s connection limits. It pools and shares backends, so a spike in client connections does not translate into a spike of new PostgreSQL connections.
PgBouncer modes and their impact
PgBouncer is the widely used pooler, and its pool_mode determines how aggressively a backend is reused. The mode changes the sizing calculation.
Session mode
In session mode a client holds a backend for the entire session, so there is little multiplexing during the session. The effective backend count is close to the client count, and sizing resembles a direct connection.
Transaction mode
A backend is borrowed for a single transaction and returned on COMMIT or ROLLBACK. This mode enables high density: a pool of twenty backends can serve thousands of clients if their transactions are short. The catch is that any activity outside a transaction, such as server‑side prepared statements, LISTEN/NOTIFY, SET without SET LOCAL, or session advisory locks, breaks when the backend rotates. A transaction‑mode configuration that respects the formula might look like this:
[databases] orders = host=db.internal port=5432 dbname=orders
[pgbouncer] listen_port = 6432 auth_type = scram-sha-256 pool_mode = transaction default_pool_size = 20 reserve_pool_size = 5 reserve_pool_timeout = 3 max_client_conn = 5000
The trap is default_pool_size, which is per (database, user) pair, not a global cap. Four users on two databases with default_pool_size = 20 authorize 160 backend connections, not twenty. Multiply accordingly.
max_client_conn is the front door: it defines how many application or serverless clients PgBouncer accepts. It can be large (five thousand or more) because clients are lightweight on the PgBouncer side. default_pool_size is the back door to PostgreSQL, and that is the value the cores formula governs.
Key takeaway
In transaction mode set max_client_conn high and default_pool_size low. The pooler absorbs traffic spikes at the front and feeds PostgreSQL a small, formula‑sized stream at the back.
Sizing worksheet
Run the following steps to obtain a reliable pool size. The process takes about ten minutes and prevents costly guesses.
- Real cores – Look up the instance’s physical cores. If only vCPUs are listed, halve for a safe estimate. Record core_count.
- Baseline pool – connections = (core_count * 2) + 4. Record baseline.
- Fan‑out – Determine how many app instances or workers will connect. Record instance_count.
- Total backend demand – If no pooler is used: baseline * instance_count. This value must stay below max_connections minus headroom. If a pooler is in transaction mode: default_pool_size = baseline (per database/user pair) and total = baseline * (database_count * user_count). Record both totals.
- Headroom – Reserve roughly ten to fifteen connections for migrations, admin tasks, monitoring, and replication. Compute usable max_connections = max_connections – headroom.
- Check – Verify that total backend demand ≤ usable max_connections. If not, shrink the pool, add a pooler, or both.
- Load test – Execute pgbench or k6 at realistic concurrency. Observe p99 latency and throughput while gradually increasing the pool by five connections at a time. Stop when throughput no longer rises; this point is usually near the formula, not far above it. Skipping this step turns a guess into a number.
The formula gives a starting pool; the load test tells where the throughput curve flattens. When they differ, trust the measurement.
Collected footguns
- Sizing per application while ignoring fan‑out. A pool that works on one host can become lethal across many instances. Always multiply by the number of instances.
- No headroom. Setting the pool exactly to max_connections leaves no room for migrations or monitoring agents, which can cause connection failures. Leave a margin.
- Idle‑in‑transaction connections. A connection that stays in a transaction blocks VACUUM and other maintenance. Set idle_in_transaction_session_timeout on PostgreSQL to terminate such connections.
- Large pool with aggressive client‑side acquire timeout. Requests queue, time out, retry, and add load. A smaller pool with a patient queue often yields better results.
- Counting vCPUs as cores. Treating hyperthreads as full cores doubles the formula output on many instances. Size against physical cores when possible.
- Assuming the pooler is a process without limits. The pooler itself has its own configuration limits and failure modes. Monitor SHOW POOLS on PgBouncer and treat it as a finite resource.
One‑line version
Connections are not throughput. Once every core is busy, each extra connection adds queuing, context switches, and lock contention, reducing the amount of work the database can perform. Start with (cores * 2) + spindles, multiply by your fan‑out, keep the total under max_connections with headroom, and place a pooler in front as soon as you move to serverless. Then run a load test, because the formula is a starting line, not a finish line.
This article extracts the connection‑management chapter from the Database Playbook: Choosing the Right Store for Every System You Build. The book expands on pool sizing, replica strategies, partitioning versus sharding, and selecting the appropriate managed PostgreSQL provider. The chapter goes deeper into pooler modes, pinning, and the serverless connection storm than this post could cover.
If this was useful
The content draws from the connection‑management chapter of the Database Playbook. The book also covers when to add a read replica, when partitioning beats sharding, and which managed PostgreSQL provider fits which workload. The connection chapter provides more detail on pooler modes, pinning, and serverless storms than the article contained.
AWS PROMOTED
I have been fact‑checking my AI agent for months. The agent often recommends an AWS service with confidence, yet the service may not exist. The Agent Toolkit for AWS connects the agent to current AWS documentation and verified skills, so it checks before answering. You stop being the agent’s QA, and it stops guessing. Let’s go!
Database Playbook reference: 
Comments
Please log in or register to join the discussion