
Cursor's new dynamic context discovery shifts from static context inclusion to on-demand retrieval, reducing LLM token usage by 46.9% in tool-heavy workflows through five file-based optimization techniques.

Cursor has fundamentally rearchitected its LLM context handling with a new approach called dynamic context discovery, moving away from including large static context payloads in every request to AI models. This method strategically minimizes token consumption while maintaining contextual awareness by leveraging the file system as a dynamic retrieval layer.
The Static Context Problem
Traditional AI-assisted editors face token efficiency challenges when:
- Including entire command outputs
- Embedding full historical context
- Loading all available tool definitions
- Maintaining complete terminal session histories
This upfront inclusion wastes tokens (costing latency and compute resources) while potentially introducing irrelevant or conflicting information to the LLM's context window.
File System as Context Orchestrator
Cursor's solution establishes files as the fundamental interface for context management through five coordinated techniques:
Large Output Buffering Shell command outputs and tool results write directly to files instead of streaming to context. The agent uses
tailoperations to retrieve only relevant segments when needed.Full History Archiving Complete interaction history saves to disk, eliminating lossy summarization. Agents retrieve specific historical segments via semantic search when gaps are detected.
Capability Indexing Domain-specific tools serialize to files. Cursor's semantic search engine dynamically discovers relevant capabilities during task execution.
On-Demand MCP Tool Loading Instead of loading entire Model Context Protocol toolkits upfront, agents fetch:
- Tool metadata initially
- Full schemas only when invoked This reduced token consumption by 46.9% in tool-heavy workflows during internal benchmarks.
Terminal Session Syncing All CLI output syncs to files, enabling targeted
grepoperations instead of full log inclusion. Failed command diagnostics become significantly more efficient.
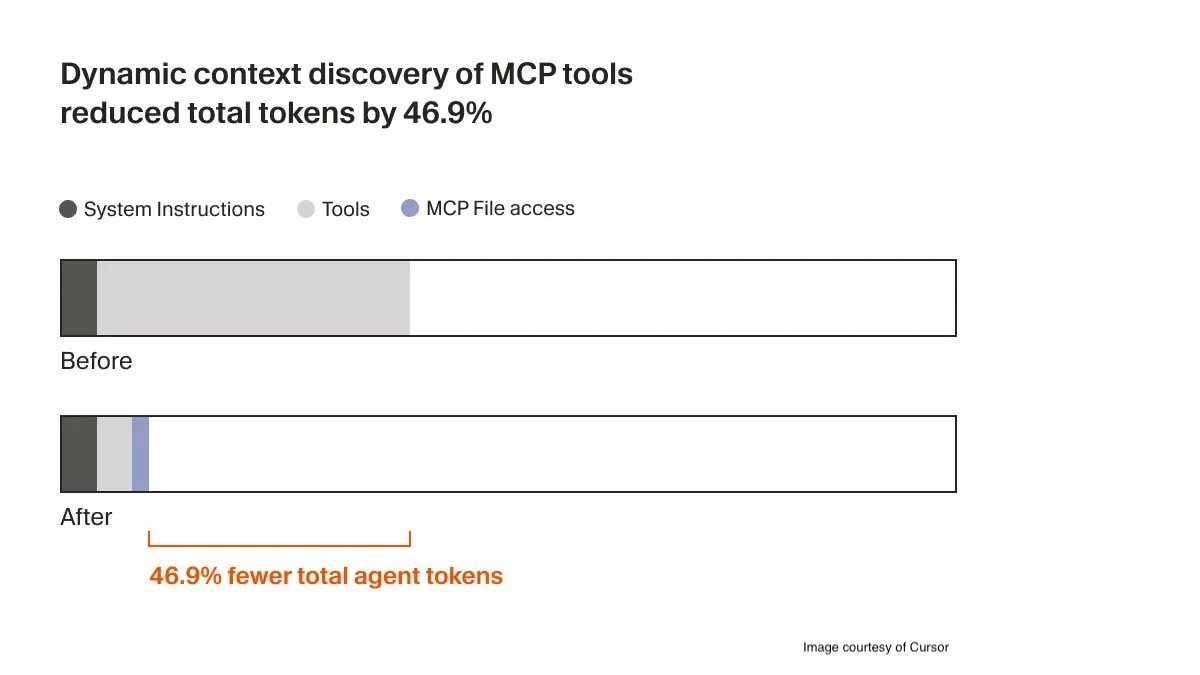 Illustration of Cursor's file-based context retrieval workflow
Illustration of Cursor's file-based context retrieval workflow
Performance Implications
Quantifiable benefits observed during A/B testing:
- Near 50% token reduction in MCP-enabled workflows
- Linear cost savings scaling with server count
- Adaptive authentication state tracking (tools notify when re-auth required)
- Precision debugging via targeted log queries
Community feedback highlights operational advantages:
"Reducing tokens by nearly half cuts costs and speeds up responses, especially across multiple servers" - @casinokrisa
Future development may include user-configurable context policies allowing per-repository tuning of retrieval aggressiveness, addressing requests like @anayatkhan09's suggestion for granular control.
Deployment Notes
- Rollout begins in Cursor v1.8.3+
- Automatic opt-in for existing MCP users
- File system requirements: 500MB+ free disk space recommended for active projects
- Compatible with all Cursor-supported LLMs (GPT-4, Claude 3, CodeLlama)
Cursor's architectural shift demonstrates how deliberate context orchestration can dramatically improve AI-assisted development efficiency. The dynamic context discovery documentation details implementation specifics for developers extending the platform.
Comments
Please log in or register to join the discussion