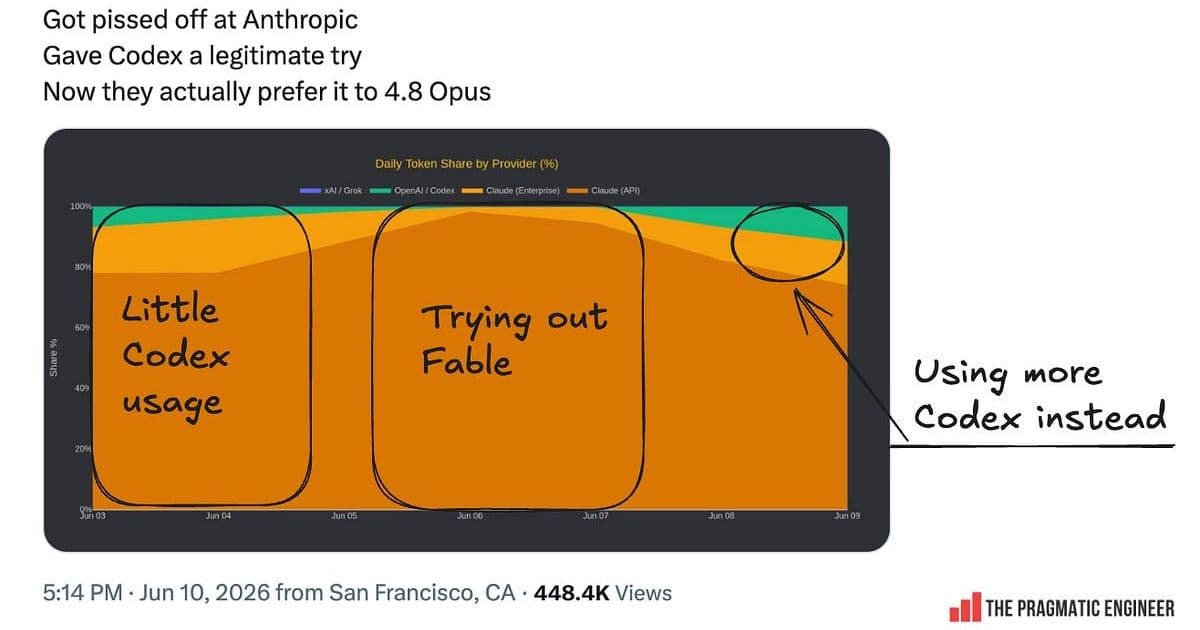
Anthropic's Fable model stores customer prompts for 30+ days and throttles performance when it detects commercial usage, pushing teams toward alternatives and highlighting the importance of multi-model strategies.

Anthropic's latest model release is causing more churn than adoption. Fable, the company's newest foundation model, ships with data retention policies and performance constraints that have developers actively shopping for alternatives. The backlash is loud enough that it's worth asking whether this self-inflicted wound is handing market share to competitors like Codex.
What happened with Fable
Fable launched with two policies that landed poorly with the development community:
30-day data retention: Customer prompts and outputs are stored for over 30 days. For teams building products that process sensitive data, proprietary code, or client information, this is a non-starter.
Usage-based performance throttling: If Anthropic determines a developer's usage pattern "could potentially pose a commercial threat," the model intentionally performs worse. The exact criteria for this determination remain opaque, but the message is clear: if your application competes with Anthropic's business interests, your experience degrades.
This isn't a bug or an edge case. It's a deliberate policy choice baked into the model's deployment configuration. For teams evaluating Claude for production workloads, these constraints change the calculus fundamentally.
Why it matters
The immediate impact is straightforward: teams that were on the fence about Claude now have concrete reasons to evaluate alternatives. But the broader implications run deeper.
Vendor lock-in risk just got real. If you've built your pipeline around Claude's API, you're now facing a migration cost if you want to leave. The 30-day retention window means your data is committed to Anthropic's infrastructure even if you switch providers tomorrow. This is exactly the kind of lock-in that makes platform dependency a genuine operational risk.
Performance unpredictability. The throttling policy introduces a new variable into your reliability planning. Your application's latency and quality can degrade based on Anthropic's internal risk assessment, not your usage patterns or resource consumption. That's a different category of operational risk than rate limiting or quota management.
Competitive positioning. Codex and other alternatives benefit from this misstep. When your competitor's trust problem becomes the selling point, you don't need to do much marketing.
The smart model routing trend
The Fable situation is accelerating an existing trend: intelligent model routing. Rather than committing to a single provider, teams are building systems that dynamically select models based on task type, cost, and reliability requirements.
This approach makes sense for several reasons:
- Risk distribution: No single provider can hold your entire pipeline hostage
- Cost optimization: Different models excel at different tasks; routing lets you pay for capability where it matters
- Resilience: Provider outages or policy changes don't cascade into complete failures
Several tools are emerging in this space. Martian offers model routing infrastructure. RouteLLM provides open-source routing capabilities. The pattern is showing up in custom implementations too, with teams building router layers that evaluate task complexity, required capability, and provider health before selecting a model.
The routing approach does add complexity. You need to maintain compatibility across providers, handle API differences, and build monitoring that covers multiple backends. But the trade-off is increasingly worth it as provider policies become more restrictive.
Coinbase's 10-hour outage: a reliability case study
Anthropic's policy changes aren't the only reliability story this week. Coinbase suffered a 10-hour outage on its global trading platform, and the root cause is a head-scratcher for anyone who's worked in distributed systems.
Coinbase's core trading service lacks automated cross-zone failover. In 2026. For a financial platform processing billions in daily volume.
The comparison to Uber in 2016 is instructive. A decade ago, Uber had already implemented cross-region failover for its core business operations. Coinbase, a company whose business depends entirely on system availability, hadn't reached that baseline.
The outage exposed several architectural gaps:
- No automated failover: When the primary zone degraded, operators had to manually intervene
- Insufficient redundancy: The system couldn't route traffic to healthy infrastructure
- Inadequate testing: Either failover procedures weren't tested, or the tests weren't realistic
For teams building trading systems, payment processing, or any availability-critical service, the Coinbase outage is a reminder that redundancy isn't optional. The cost of implementing proper failover is always less than the cost of an extended outage on a revenue-generating platform.
Industry moves
Anthropic and OpenAI IPO filings. Both companies have filed for public offerings. The timing is notable given Anthropic's current trust issues with developers. Going public will require more transparency around policies like data retention and usage monitoring, which could force changes to Fable's current configuration.
GitHub maintainer ban triggers open source migration. An open source project pulled its code from GitHub after a maintainer was banned without appeal. The incident highlights the risks of centralized code hosting and is driving renewed interest in self-hosted Git solutions and federated platforms.
Opendoor reshores with AI-native engineers. Opendoor is bringing engineering roles back from India to the US, specifically hiring engineers who can work effectively with AI coding tools. The strategy signals a shift in how companies think about engineering productivity: fewer, more capable engineers with strong tool proficiency may outperform larger teams without AI integration.
The LLM skills question
A viral article this week features a software engineer admitting they feel increasingly useless due to LLM capabilities. The piece resonated widely, touching on a real anxiety in the industry.
The reaction is understandable but misses some nuance. LLMs are effective at generating code for well-defined problems with clear patterns. They struggle with ambiguous requirements, system design decisions that require business context, debugging novel failures, and navigating organizational constraints.
The engineers who are thriving right now are the ones who've figured out how to use LLMs as acceleration tools while maintaining their judgment about what to build and why. The skill isn't disappearing; it's shifting from syntax recall to systems thinking and problem decomposition.
What to do about it
If you're running Claude in production:
- Audit your data flow: Understand what prompts and outputs are being retained and for how long
- Build an exit plan: Document the integration points and have a tested migration path to an alternative provider
- Implement routing: Even a simple router that can fall back to a different provider protects you from policy changes
- Monitor for throttling: If your application's performance degrades unexpectedly, rule out usage-based restrictions before investigating other causes
The Anthropic situation is a concrete example of why single-provider dependency is a strategic risk, not just a technical convenience. Fable's policies are making that case more persuasively than any architecture diagram could.
Comments
Please log in or register to join the discussion