
Google's experimental DiffusionGemma generates text the way image models paint pictures, and its biggest selling point may not be raw speed. By running well on a single consumer machine, it nudges AI inference away from corporate datacenters and back toward devices users actually control, which carries direct consequences for who sees your prompts.
Google's DeepMind team this week released DiffusionGemma, an experimental open-weights model that borrows tricks from AI image generators to speed up text output by as much as 4x on consumer hardware. The technical story is interesting on its own. The more consequential story, for anyone who cares about where their data goes, is that this model is built to run on your machine rather than someone else's.

What happened
DiffusionGemma is a 26 billion-parameter mixture of experts model, and despite the Gemma branding it does not work like a conventional large language model. Standard LLMs are autoregressive: they predict one token, then the next, then the next, streaming the model's active parameters out of memory for every single token. That makes memory bandwidth the choke point, and it is why running a capable model locally usually means buying an expensive graphics card and watching it crawl.
DiffusionGemma instead works the way Stable Diffusion or Flux turns visual static into an image. It lays down a canvas of random tokens and refines them through a series of denoising steps until coherent text emerges, generating whole paragraphs in parallel rather than word by word. The practical effect is that the workload shifts from memory-bandwidth bound to compute bound, which suits the spare horsepower sitting idle in high-end consumer GPUs. Google says you can run it with 18 GB of DRAM or VRAM.
The model is available now on Hugging Face under a permissive Apache 2.0 license, with support already merged into vLLM, MLX, and HF Transformers, and Llama.cpp support on the way.
The performance claims, with the asterisks
Google is positioning the speed gains as the headline, and the numbers deserve a careful read rather than a press-release reading. The company's own chart puts DiffusionGemma at roughly a 2.25x speedup over the 12B parameter LLM with speculative decode enabled, and close to 4x against Gemma 4 26B-A4B on a single Nvidia H100.
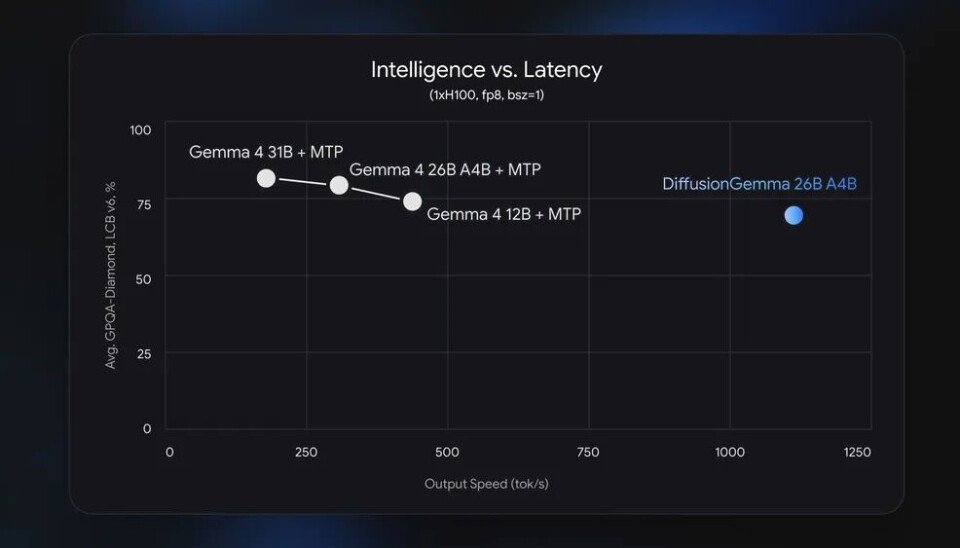
The quality side is less flattering. On the GPQA-Diamond benchmark, the 26 billion-parameter DiffusionGemma lands just behind Gemma 4 12B, meaning a much larger model trails a smaller conventional one on reasoning. Diffusion language models have a track record here. Earlier efforts like DREAM and Mercury 2 also showed real speedups while underperforming traditional LLMs of comparable size. DiffusionGemma fits that pattern. Speed, not accuracy, is the trade.
Why the privacy angle matters more than the speed
Here is where a digital rights reader should pay attention. When you use a cloud AI assistant, your prompts travel to a provider's datacenter, get processed there, and pass through that company's logging, retention, and access policies. Every question you type, including the medical worries, legal questions, financial details, and half-formed personal thoughts people increasingly hand to chatbots, becomes data sitting on infrastructure you do not control.
Local inference changes that equation. A model that runs entirely on your laptop processes your prompts without sending them anywhere. There is no transmission to intercept, no server-side log to subpoena, no retention policy to read and distrust, and no training pipeline that might quietly absorb your input. Under frameworks like the GDPR, data that never leaves the user's device sidesteps most of the cross-border transfer and processing-agreement headaches that cloud AI creates for European businesses. Under the CCPA, there is simply less personal information being collected, shared, or sold because there is no collection happening in the first place.
That is the genuine significance of Google making this thing small enough to run on a notebook. The barrier to keeping AI on-device has been performance, and diffusion techniques chip away at it.
Read Google's motives clearly
None of this means Google has discovered a sudden devotion to user privacy. The company is candid that local inference helps it cut the cloud costs of serving AI features, and it has been moving in this direction for a while. Back in May, Google quietly began shipping a small LLM inside the Chrome browser. Pushing computation onto users' hardware saves the provider money on datacenter capacity and electricity, and it conveniently shifts the resource burden to the customer.
The privacy benefit is real, but it is a side effect of a cost decision, not the goal. For users and for compliance officers, that distinction matters. On-device processing protects data because of how the technology works, not because of a promise that could change with the next product update or terms-of-service revision. Architecture is a stronger guarantee than a privacy policy, and DiffusionGemma's value to a rights-conscious reader is precisely that it makes the privacy-preserving option fast enough to actually use.
What changes
For individual users, the immediate change is optionality. As capable models become genuinely usable on consumer hardware, choosing a private, offline assistant stops being a hobbyist's compromise and starts being a practical alternative. For companies subject to data protection law, locally deployed models offer a path to AI features that keeps regulated personal data inside the organization's own boundary, reducing the surface area for breaches and the paperwork of vendor data-processing agreements.
The caveat is the quality gap. DiffusionGemma trades accuracy for speed and privacy, so it is not a drop-in replacement for the strongest cloud models on hard reasoning tasks. But the direction of travel is what counts. Every improvement that makes on-device inference faster weakens the assumption that using AI means handing your data to a third party. For a movement that has spent years arguing that privacy and capability are not opposites, that is worth watching closely.
Comments
Please log in or register to join the discussion