A small chess puzzle becomes a useful test of how language models can pair fluent code generation with older, stricter forms of symbolic reasoning.
Thesis
John D. Cook's experiment with solving a Martin Gardner chess puzzle using Claude and Prolog is more than a charming demonstration of AI-assisted programming. It shows a deeper pattern in contemporary computing: large language models are increasingly useful when paired with formal systems that can check, constrain, and execute the ideas they propose. Claude supplies fluency, translation, and syntactic patience. Prolog supplies a world where rules have consequences.
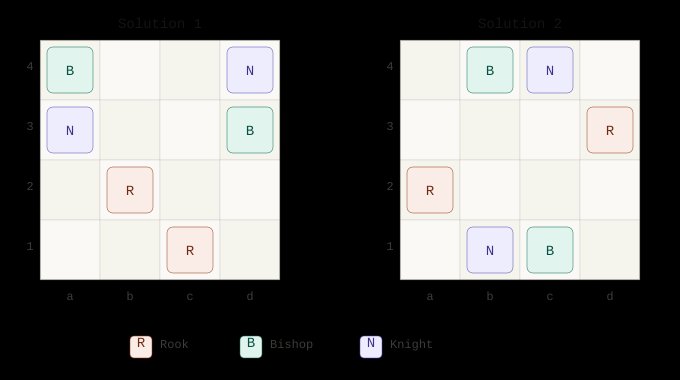
The puzzle itself is compact: place two rooks, two bishops, and two knights on a 4 by 4 chessboard so that no piece attacks any other. There are twelve raw solutions if rotations and reflections are counted separately, and two essential solutions once the board's D4 symmetries are factored out. That small search space matters because it is large enough to require care, but small enough that the result can be understood by a human reader.
Key Arguments
The first argument is that Prolog remains unusually well matched to problems whose natural form is logical constraint. In a mainstream imperative language, the programmer often has to decide how to represent the board, how to enumerate placements, how to prevent duplicates, and how to test attacks. In SWI-Prolog, many of those concerns become declarative statements: a square is a row and column in a finite set, two rooks attack if they share a row or column, two bishops attack if their row and column distances match, and two knights attack if their coordinate differences form the familiar L shape.
That is the enduring appeal of Prolog. The program does not merely simulate reasoning about the chessboard. It states the relations that define the problem, then asks the runtime to search the consequences of those relations. The generated program uses predicates such as rook_attacks, bishop_attacks, knight_attacks, and all_pairs_safe, which map almost directly onto the verbal statement of the puzzle. This is not just a matter of elegance. It reduces the distance between the mathematical object and the executable artifact.
The second argument is that an LLM changes the cost profile of older languages. Prolog has always had strengths, but it has also had friction: unfamiliar syntax, recursion-heavy idioms, backtracking semantics, negation as failure, and a style of thinking that feels alien to many programmers trained on Python, JavaScript, or C-like languages. When Claude writes the initial version, that friction becomes less decisive. The human can focus on the shape of the logic and the validity of the result, while the model handles much of the syntactic ceremony.
This does not make syntax irrelevant, but it changes where the programmer's attention goes. In Cook's example, the crucial questions are not whether the semicolons and predicate forms are familiar. They are whether the attack relations are correct, whether identical pieces are canonicalized so that swapping two rooks does not create a false new solution, whether all six squares are distinct, and whether the symmetry reduction really captures the eight transformations of a square. These are semantic questions, and they are exactly where human review should remain concentrated.
The third argument is that the most interesting part of the program is not the search itself, but the treatment of equivalence. A naive program can enumerate placements. A more thoughtful program distinguishes raw solutions from solutions that are essentially the same under rotation and reflection. The code does this by applying the D4 transformations of the square: identity, rotations by 90, 180, and 270 degrees, horizontal and vertical flips, and reflections across the two diagonals.
That symmetry step is philosophically important. Computing often begins by finding answers, but maturity arrives when we decide which answers are meaningfully distinct. The program's canonical_placement predicate transforms each solution through all board symmetries, sorts the forms, and selects a representative. This is a small version of a large theme in mathematics and computer science: classification is not only about generating objects, but about identifying when different presentations describe the same object.
The fourth argument is that this pairing of LLM and Prolog gives the user a useful division of labor. Claude can produce a candidate program quickly. SWI-Prolog can run that program deterministically. The output can then be checked against the known count: twelve raw solutions and two unique solutions up to symmetry. The model proposes, the logic engine disposes, and the human interprets.
That pattern is healthier than treating an LLM as an oracle. The generated answer is not accepted because it sounds confident. It is accepted because it becomes executable, inspectable, and testable. The command swipl -g "run, halt" chess_placement.pl turns prose into a concrete computation. The output then creates an audit trail: total raw solutions, unique solutions under symmetry, and a printed board for each canonical case.
Implications
The broader implication is that AI-assisted programming may revive interest in languages and tools that were previously considered too specialized for ordinary use. Prolog is not new. Its origins are bound to an older dream of programming as formal reasoning, a dream that did not conquer everyday software development but never stopped being powerful in domains such as constraint solving, symbolic AI, theorem proving, and rule-based systems.
LLMs make that history newly practical. A programmer does not need to become a Prolog stylist before using it for a narrow problem. They can describe the target behavior, ask the model for an implementation, then evaluate the generated code with the discipline appropriate to the domain. In this sense, models such as Claude are not replacing formal systems. They are making it easier to approach them.
The same pattern applies beyond chess. A scheduling problem can be expressed in a constraint solver. A type-level invariant can be encoded in a proof assistant. A parsing ambiguity can be resolved with a grammar. A security policy can be represented as logic rather than scattered conditionals. The lesson is not that every problem should be written in Prolog. The lesson is that language models become more reliable when their outputs are routed into systems that have clear semantics and can reject contradictions.
There is also a pedagogical implication. A puzzle like this teaches more than syntax. It teaches the difference between enumeration and classification, between object identity and equivalence classes, between local pairwise constraints and global validity. The chessboard becomes a small laboratory for computational thought. A reader sees how a verbal puzzle becomes predicates, how predicates become a search, how search results become symmetry classes, and how the final printed boards connect back to the original intuition.
That makes the example valuable for teaching AI-assisted coding itself. The right question is not simply, "Can Claude solve it?" The better question is, "What scaffolding lets us trust the result?" In this case, the scaffolding consists of a precise problem statement, an executable formal language, a known expected count, and output that a human can inspect. This is the kind of workflow that turns generated code from a plausible artifact into a checked artifact.
Counter-Perspectives
There are limits. The fact that Claude produced a working Prolog program for a small chess puzzle does not imply that LLM-generated logic programs are generally correct. A larger constraint problem could contain hidden edge cases, performance traps, or subtly wrong equivalence reductions. Logic programming makes some mistakes easier to see, but it does not eliminate mistakes.
There is also a danger that the fluency of generated code can conceal misunderstanding. A Prolog program may look mathematically neat while encoding a flawed predicate. For example, if a bishop attack rule forgot to exclude the same square, or if the canonicalization sorted terms in a way that accidentally erased type distinctions, the output might still appear orderly. Formal tools help, but only when the formalization itself is right.
Another counter-perspective is that this could have been solved easily in Python, brute force, or even by hand. That is true, but it misses the point. The interest of the example is not raw efficiency. It is the fit between a relational problem and a relational language, and the way an LLM reduces the adoption cost of that fit. A Python implementation would likely be more familiar to many readers. The Prolog version is more revealing because it exposes the logical skeleton of the puzzle.
Finally, the example should temper both pessimism and enthusiasm about AI coding. Claude is not doing magic here. It is translating a structured problem into a structured program, then relying on an existing interpreter to perform the search. Yet that translation is still useful. Much of programming consists of choosing a representation, encoding rules without dropping a condition, and arranging the computation so that the machine can check the space of possibilities.
The deeper lesson is that AI systems become more valuable when they are not asked to replace older forms of rigor, but to cooperate with them. Prolog represents one lineage of symbolic AI, one that insists that relations and constraints matter. Claude represents a newer lineage, one built on language, pattern, and probabilistic generation. The chess puzzle works because these two forms of intelligence meet at the right boundary: one writes, the other verifies by execution, and the human remains responsible for meaning.
Comments
Please log in or register to join the discussion