GCC 17 gains FMV support for Intel's next-gen ISA extensions, enabling runtime optimization for Nova Lake and Diamond Rapids processors launching next year.
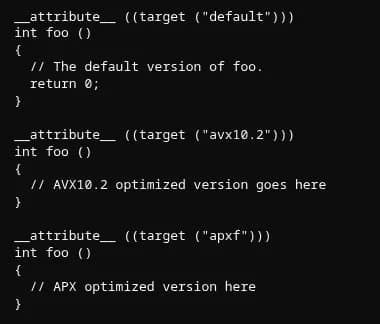
Intel's upcoming Nova Lake and Diamond Rapids processors just received a significant software enabling milestone. GCC 17 has merged function multi-versioning (FMV) support for Advanced Performance Extensions (APX) and Advanced Vector Extensions 10.2 (AVX10.2), allowing developers to write optimized code paths that automatically select the best implementation at runtime based on detected CPU capabilities.
Understanding Function Multi-Versioning
FMV is a compiler-driven optimization technique that generates multiple versions of the same function, each targeting different instruction set architecture (ISA) features. When the program executes, runtime detection identifies the CPU's capabilities and selects the most optimized version available. This approach eliminates the need for separate binaries or manual dispatch logic, a pattern that has proven valuable for incremental ISA adoption across heterogeneous x86 deployments.
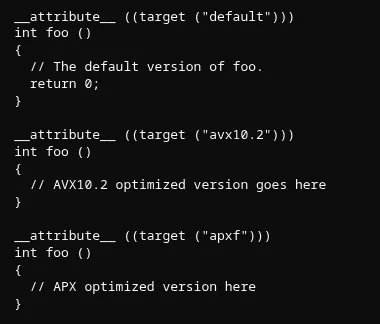
GCC's existing FMV infrastructure already supports established features like AVX-512, SSE4, and AVX2. The newly merged work extends this framework to accommodate Intel's next-generation extensions, adding four new attribute targets: avx10.2, apxf, arch=diamondrapids, and arch=novalake. Developers can target either extension individually or target the processor families as complete ISA packages.
APX and AVX10.2 Technical Context
APX represents Intel's expansion of the general-purpose register file, doubling the architectural register count from 16 to 32 general-purpose registers. This extension also introduces new condition codes, conditional moves, and enhanced branch prediction hints. The register pressure reduction alone should deliver measurable performance gains for register-heavy workloads, particularly in compiler-generated code and JIT environments where register allocation decisions are constrained.
AVX10.2 builds on the AVX10 convergence initiative that Intel established to unify AVX-512 support across processor families. Previous AVX-512 implementations varied significantly between cores, with some supporting 512-bit operations and others limited to 256-bit or 128-bit execution units despite sharing the ISA designation. AVX10.2 establishes a cleaner baseline with consistent vector width support and new data type conversions, making it more practical for developers to adopt without extensive runtime feature probing.
The combination of APX and AVX10.2 in a single processor generation creates a substantial ISA expansion. Diamond Rapids, Intel's next server-focused Xeon architecture, and Nova Lake, the corresponding client desktop and mobile platform, will both feature these extensions. This simultaneous introduction across client and server segments is notable because it simplifies compiler targeting decisions and reduces fragmentation in the software ecosystem.
Compiler Enablement Implications
The timing of this FMV merge in GCC 17, targeting a stable release in early 2027, aligns with the expected production timeline for Nova Lake and Diamond Rapids silicon. Compiler support needs to mature before silicon availability to ensure that optimized software is ready when systems ship. This lead time is critical for ISV adoption and for Linux distributions planning their toolchain versions for release cycles coinciding with new hardware launches.
GCC's FMV implementation for these new extensions relies on runtime CPUID detection. At program startup or on first function call, the runtime queries the processor and selects the appropriate version. The overhead for this detection is minimal, typically measured in nanoseconds per dispatched function, making it suitable for hot paths where the performance differential between code paths justifies the dispatch cost.
For developers, the practical impact is straightforward. A single compilation unit can now contain hand-optimized assembly routines using APX's new registers and AVX10.2's vector instructions, alongside generic fallback implementations. The compiler handles the dispatch logic, and the appropriate version executes transparently. This model has worked well for AVX-512 adoption, where FMV allowed performance-critical libraries like glibc, libm, and various math libraries to provide optimized implementations without breaking compatibility on older hardware.
Supply Chain and Market Positioning
Intel's strategy of introducing APX and AVX10.2 across both client and server lines simultaneously reflects a broader shift in how ISA extensions are marketed. Previous generations created differentiation through selective feature availability, but the current approach emphasizes ecosystem simplification. Developers write once for the new ISA features, and both consumer and enterprise deployments benefit from the same optimized binaries.
This has implications for software supply chains. Linux distributions, cloud providers, and embedded system vendors can plan migration paths with greater confidence, knowing that compiler support will be mature before silicon arrives. The GCC 17 timeline provides approximately 12-18 months of toolchain maturity before production hardware volumes scale, which is consistent with historical enablement cycles for major ISA transitions.
The FMV attribute targets arch=diamondrapids and arch=novalake also suggest Intel is establishing clearer processor-family-level targeting. Rather than requiring developers to specify individual features, they can target the complete ISA package of a processor generation. This simplification reduces configuration complexity for build systems and package maintainers who need to optimize for specific deployment targets.
For the semiconductor industry more broadly, thisFMV support represents the continued maturation of hardware-software co-design practices. ISA extensions that arrive without compiler support create adoption friction, and the early merge of FMV support demonstrates coordination between Intel's silicon teams and the open-source compiler community. The result is a more predictable enablement timeline that benefits both hardware vendors and software developers planning their product cycles around next-generation processor capabilities.
Comments
Please log in or register to join the discussion