
A three-year GPU lifespan claim has shaped AI bubble arguments, but public cloud behavior and supercomputer failure studies point to longer service lives.

AI skeptics have started using a narrow hardware claim to make a broad economic argument: inference GPUs burn out after about three years under heavy load, so current AI products need constant hardware replacement.
That claim matters for developers because inference cost sets the floor for many AI products. If A100, H100, or B300 fleets fail fast, hosted coding tools, search agents, copilots, and model APIs face a harsher cost curve. If those chips keep serving inference for six years or more, AI companies can cut prices, sweat older hardware, and reserve new accelerators for training or premium workloads.
The claim
The three-year ceiling rests on thin sourcing. The chain runs through a tweet that cited an unnamed GenAI principal architect at Google, via a screenshot that appears to come from an expert network interview. Tegus, the expert network named in the surrounding discussion, pays specialists for technical calls, which can reward confidence as much as measured fleet data.
That does not make the source useless. It does make the quote a weak base for claims about global AI infrastructure. A principal architect may know cluster behavior from direct work, but a casual estimate differs from a fleet retirement study.

Developers should separate three questions. First, how long can a GPU function under load? Second, how long can an operator profit from that GPU? Third, how long will hyperscalers choose to keep older chips in premium capacity? Those answers can differ by years.
The hardware record
Public examples cut against a hard three-year limit. Nvidia sold the A100 from 2020 to 2024, and cloud providers still rent A100 capacity for AI work through services such as Amazon EC2 P4 instances. Developers keep using those chips because many inference jobs care about memory, availability, and price more than peak training throughput.
Google has also pushed its Tensor Processing Unit program across many generations while keeping older accelerator capacity useful inside its own infrastructure. TPUs differ from Nvidia GPUs, but they face the same data center stresses: heat, power cycling, interconnect load, and high utilization.
Supercomputers give us a cleaner long-run example. Oak Ridge ran Summit with 27,648 Nvidia V100 GPUs from 2018 until its 2024 retirement. Oak Ridge also ran Titan from 2012 to 2019 with 18,688 Nvidia K20X GPUs.
Researchers studied Titan failures in a 2023 paper on GPU failure data. They found location mattered because hotter cage positions failed more. The cooler positions showed survival rates above 95% at three years. Several positions still cleared 90% at six years.
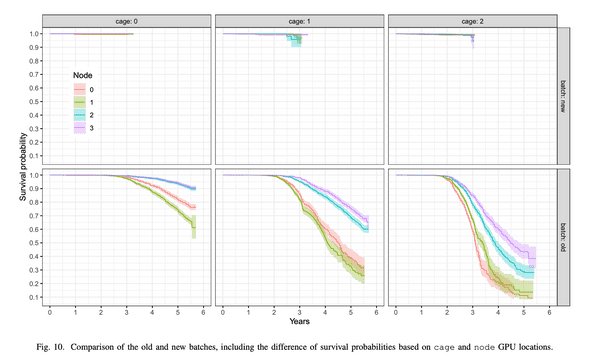
AI data centers run different workloads than Titan ran, and newer chips draw more power. Operators also pack racks denser than many older high-performance computing centers did. Those differences raise fair questions, but they do not turn one anonymous quote into a hardware law.
Economic life
A chip can work and still lose its best job. An A100 may serve inference after a B100 offers better performance per watt. A cloud provider with tight power capacity may move scarce electricity to newer hardware because new chips earn more per megawatt.
That is an economic replacement cycle. It does not mean the older fleet becomes scrap. Cost-sensitive customers, batch inference jobs, open-source model hosts, and internal tools can keep using older accelerators at lower prices.
This distinction changes the bubble argument. If an AI provider needs new GPUs to grow, capital access matters. If the provider can keep older chips serving inference, a funding slowdown hurts expansion before it kills existing service capacity.
Data center costs also extend beyond GPUs. Operators spend on land, power equipment, cooling, networking, storage, and racks. A failed accelerator does not force a company to rebuild the site. It forces repair, replacement, or redeployment inside an existing plant.
Developer response
Developers on forums such as Hacker News tend to care less about accounting schedules and more about rental prices. They see A100s, V100s, and consumer ex-mining GPUs continue to run useful workloads years after launch. That lived experience makes the three-year ceiling feel too neat.
The better developer takeaway: model cost projections need separate lines for physical failure, chip obsolescence, power limits, and capital cost. A single lifespan number hides too much.
For product teams, the practical question is workload fit. Training frontier models pushes operators toward the newest chips. Serving smaller models, embeddings, batch jobs, and latency-tolerant agents can make older accelerators attractive for years.
AI infrastructure may still face overbuild risk, debt risk, and demand risk. GPU lifespan looks like a weaker pillar in that argument. The public evidence points toward longer service lives than the three-year claim suggests, with economics deciding replacement before hardware failure does.
Comments
Please log in or register to join the discussion