Ertu ports a 100,000-cube C stress test to Clojure and cuts the CPU pass from 2.6 ms to 0.86 ms with Java's Vector API.
{{IMAGE:1}}
Ertu took a C stress test built around 100,000 moving cubes, ported it to Clojure, and pushed the hot loop close to C speed with help from Claude Code and Java's Vector API.
The test asks the CPU to rebuild each cube's 4x4 transform matrix on each frame. That means about 900,000 sine evaluations and about 6 MB of matrix data before the GPU draws 3.6 million triangles. Ertu framed the test as half CPU work and half GPU work, which makes it a useful benchmark for language overhead in a graphics loop.
C set the target. Clang at -O2 took the transform loop and emitted NEON SIMD instructions on Apple Silicon. Ertu measured the C version at 0.70 ms for 100,000 matrices on one thread. His best scalar Clojure version, with primitive arrays, type hints, and unchecked math, took 2.6 ms.
That gap came from vectorization. Clang's optimizer turned the C loop into SIMD code. HotSpot did not do that for the Clojure loop. Ertu then used Project Panama's Vector API, which lets Java code express SIMD operations through a regular API that Clojure can call.
The first Vector API attempt missed the target by a wide margin. Ertu measured 7.7 ms, slower than the scalar Clojure loop. The JIT logs showed vector intrinsics, but the program still paid for object allocation.
The cause sat in one Clojure var. Ertu had stored the vector species, the descriptor that tells the API the vector width, in a var. HotSpot could not fold that lookup into a compile-time constant, so the Vector API used slow fallback paths and created temporary vector objects.
Ertu fixed the kernel by referencing FloatVector/SPECIES_128 at each call site, writing helper math as macros, and moving from JDK 21 to JDK 25. The JDK change mattered because JDK 25 generated better NEON code for the shuffle operations that transpose matrices in registers.
After those changes, the SIMD Clojure pass fell to about 1 ms. Fused multiply-add instructions brought it to 0.86 ms, compared with C's 0.70 ms. In the full app, both versions averaged about 370 FPS on an M3 MacBook because the GPU became the limit.
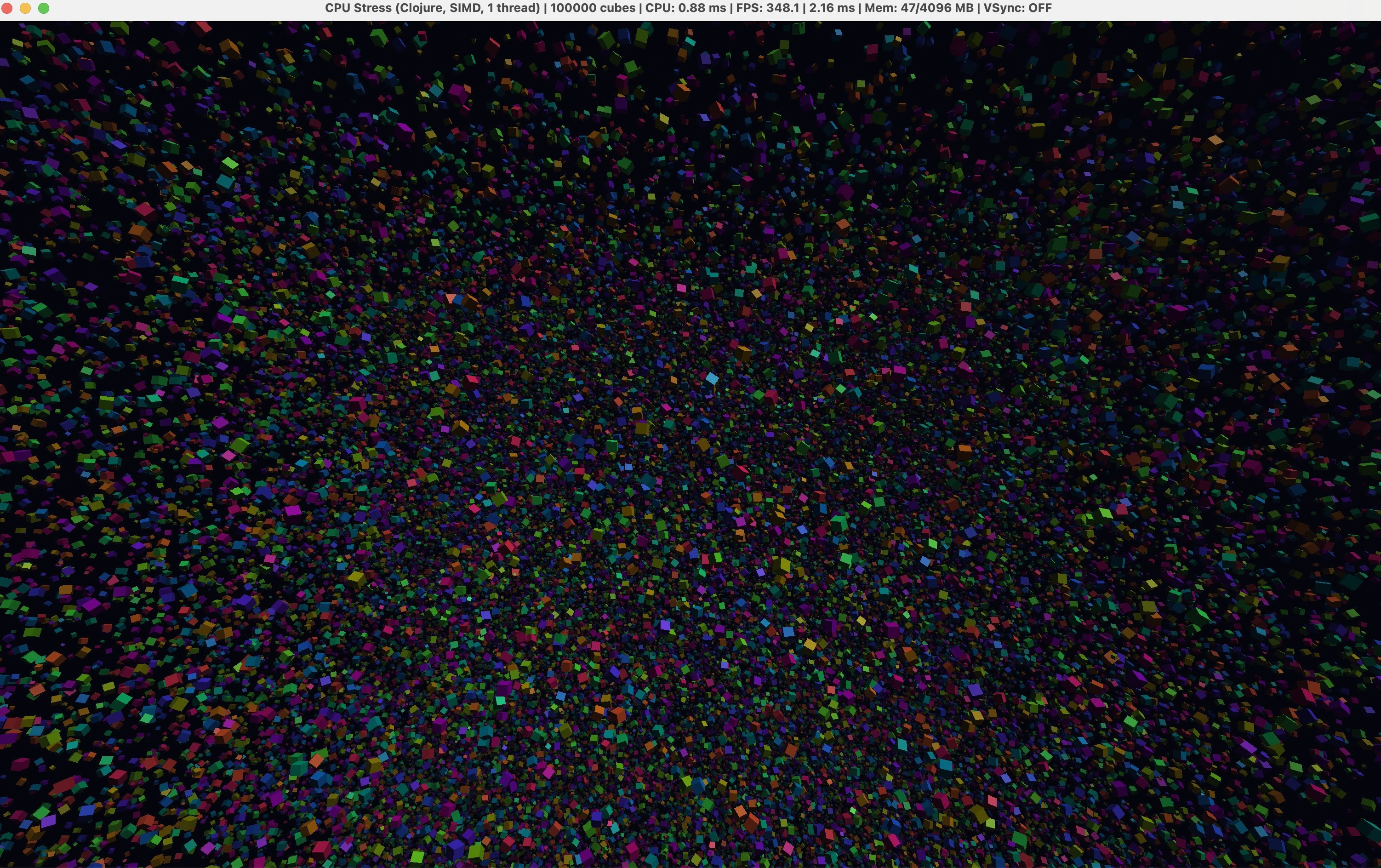
The memory result matters as much as the timing. Ertu kept the final kernel on plain float arrays and SIMD registers, then wrote into one preallocated float array for OpenGL. The heap stayed around 134 MB. The broken Vector API version created about 7.5 GB per second of temporary vector objects.
Clojure users should read this as a boundary case, not a general style guide. Ertu's optimized loop uses mutable arrays, macros, and hand-shaped SIMD code. Most Clojure programs should keep that kind of code in small areas. The rest of the app can stay idiomatic.
The larger result belongs to the JVM engineers. Project Panama gives Java, and therefore Clojure, a way to reach explicit SIMD without JNI. A decade ago, Ertu likely would have written this transform kernel in C and called it from the JVM. In this test, he kept the code in Clojure and came within about 23% of clang's auto-vectorized C output.
Comments
Please log in or register to join the discussion