Microsoft's GenRec Direct Learning (DirL) reimagines recommender systems by treating ranking as a native sequence modeling problem, using token-native generative models instead of traditional feature-heavy pipelines.
Microsoft researchers have introduced GenRec Direct Learning (DirL), a novel approach that fundamentally reimagines how recommender systems operate by treating ranking as a native sequence modeling problem rather than a feature engineering exercise.
The Problem with Traditional Ranking Pipelines
Modern recommender systems have evolved into complex, layered architectures where signals are split across dense and sparse branches, merged late in the stack, and processed through extensive feature engineering pipelines. This traditional approach, while effective, introduces several critical challenges:
Growing pipeline surface area - Each new signal expands the surrounding ecosystem with feature definitions, joins, normalization logic, validation, and parity checks. Over time, this ballooning surface area slows iteration, raises operational overhead, and increases the risk of subtle production inconsistencies.
Semantics diluted by flattening - Generative models naturally capture rich structure including token-level interactions, compositional meaning, and contextual dependencies. However, when these representations are flattened into sparse or dense feature vectors, much of that structure is lost—undermining the very semantics that make generative representations powerful.
Sequence modeling treated as an add-on - While traditional rankers can ingest history features, modeling long behavioral sequences and fine-grained temporal interactions typically requires extensive manual feature engineering. As a result, sequence modeling is often bolted on rather than treated as a first-class concern.
The Direct Learning Approach
DirL's core shift is simple but fundamental: instead of the conventional pipeline of generative model → embeddings → downstream ranker, it adopts an end-to-end formulation where tokenized sequence → generative sequential model → ranking score(s).
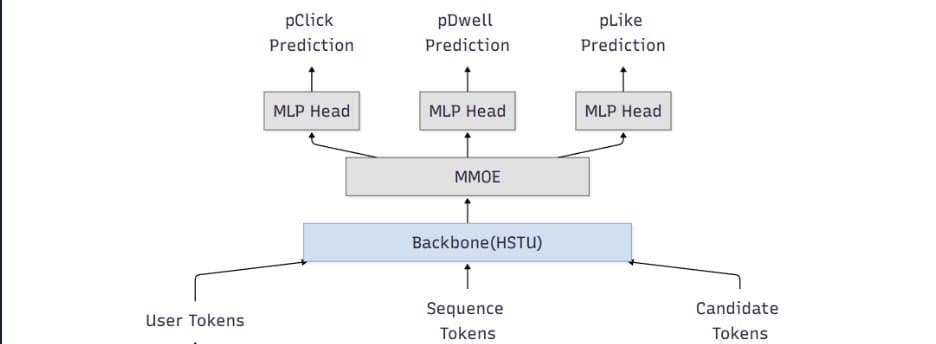
In this architecture, user context, long-term behavioral history, and candidate item information are all represented within a single, unified token sequence. Ranking is then performed directly by a generative, token-native sequential model.
Unified Tokenization
All inputs in DirL are converted into a shared token embedding space, allowing heterogeneous signals to be modeled within a single sequential backbone. Each input sequence consists of three token types:
- User/context tokens - Encode user or request-level information such as age, cohort attributes, request context, temporal signals, and user-level statistics like historical CTR
- History tokens - Represent prior user interactions over time, including engaged document IDs, semantic or embedding IDs, and topic-like attributes. Each interaction is mapped to a token, preserving temporal order
- Candidate tokens - Each candidate item is represented as a token constructed from document features and user-item interaction features, concatenated and projected into a fixed-dimensional vector via an MLP
The model backbone consumes a sequence of the form: [1 user/context token] + [N history tokens] + [1 candidate token]
Long-Sequence Modeling Backbone
To handle long input sequences, DirL adopts a sequential backbone designed to scale beyond naïve full attention. The current setup uses stacked HSTU layers with multi-head attention and dropout for regularization. The hidden state of the candidate token from the final HSTU layer is fed into an MMoE module for scoring.
Multi-Task Prediction Head
Ranking typically optimizes multiple objectives (e.g., engagement-related proxies). DirL employs a multi-gate mixture-of-experts (MMoE) layer to support multi-task prediction while sharing representation learning. The MMoE layer consists of N shared experts and one task-specific expert per task.
Early Results and Challenges
Early experiments show promising results: token-native setups improve both in-house evaluation metrics and online engagement (time spent per UU), suggesting that modeling long behavior sequences in a unified token space is directionally beneficial.
However, the same design choices that improve expressiveness also raise practical hurdles:
- Training velocity slows down - Long-sequence modeling and larger components can turn iteration cycles from hours into days, making ablations expensive
- Serving and training costs increase - Large sparse embedding tables plus deep sequence stacks can dominate memory and compute
- Capacity constraints limit rollout speed - Hardware availability and cost ceilings become gating factors for expanding traffic and experimentation
The main challenge isn't whether DirL can learn the right dependencies—it's whether it can be made cheap and fast enough to be a production workhorse.
Path to Production Viability
Current work focuses on understanding how to keep the semantic benefits of token-native modeling while exploring options to reduce overall cost:
- Embedding tables consolidate and prune - Oversized sparse tables rely more on shared token representations where possible
- Right-size the sequence model - Reduce backbone depth where marginal gains flatten, evaluate minimal effective token sets, explore sequence length vs. performance curves
- Inference and systems optimization - Dynamic batching tuned for token-native inference, kernel fusion and graph optimizations, quantization strategies that preserve ranking model behavior
Why This Direction Matters
DirL explores a broader shift in recommender systems—from feature-heavy pipelines with shallow rankers toward foundation-style sequential models that learn directly from user trajectories. If token-native ranking can be made efficient, it unlocks several advantages:
- Simpler modeling interfaces - Fewer feature-plumbing layers
- Stronger semantic utilization - Reducing information loss from aggressive flattening
- More natural path to long-term behavior and intent modeling
Implementation at Microsoft
The work was developed and validated within Microsoft's internal machine learning and experimentation ecosystem. Training data came from seven days of MSN production logs and user behavior labels, encompassing thousands of features. Model training used a PyTorch-based deep learning framework on Azure Machine Learning with a single A100 GPU.
For online serving, the trained model was deployed on DLIS, Microsoft's internal inference platform. Evaluation was conducted through controlled online experiments on the Azure Exp platform.
Call to Action
Practitioners and researchers working on large-scale recommender systems are encouraged to experiment with token-native ranking architectures alongside traditional feature-heavy pipelines, compare trade-offs in modeling power and system efficiency, and share insights on when direct sequence learning provides practical advantages in production environments.
The research team acknowledges contributions from colleagues including Gaoyuan Jiang, Lightning Huang, Jianfei Wang, Gong Cheng, Peiyuan Xu, Chunhui Han, and Peng Hu.
This work represents a significant step toward more intelligent, efficient recommender systems that can better understand and respond to user behavior patterns while reducing the complexity and maintenance burden of traditional feature engineering approaches.
Comments
Please log in or register to join the discussion