
Google has released Gemma 4, a family of open-weight models with native video, image, and audio processing capabilities, distributed under an Apache 2.0 license that enables unrestricted commercial use and modification.
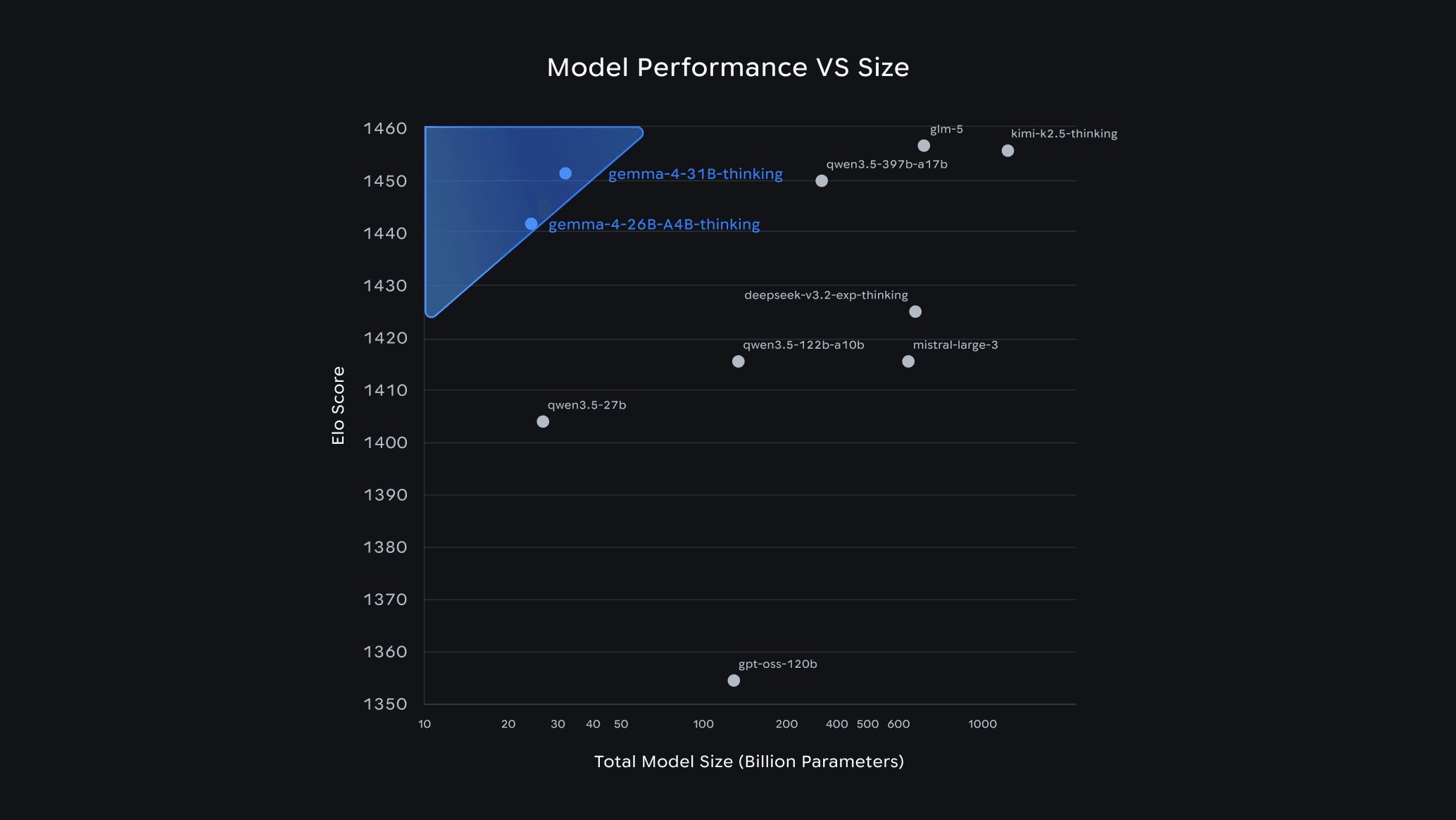
Google has recently released Gemma 4, a family of open-weight models spanning effective 2B and 4B edge variants, a 26B Mixture-of-Experts model, and a 31B dense model, all distributed under an Apache 2.0 license. The release introduces native video and image processing across the lineup, audio input on the smaller models, context windows up to 256K tokens, and benchmark results that place the 31B dense variant in a bracket typically occupied by models three to five times its size.
The agent-oriented framing is reflected in concrete capabilities. Google reports that the 31B variant scores 84.3% on GPQA Diamond and 80.0% on LiveCodeBench v6. The GPQA Diamond result nearly doubles the 42.4% achieved by the prior Gemma 3 IT 27B, reflecting substantial gains in science reasoning and code generation. For tool use, the models add native support for function-calling, structured JSON output, and native system instructions, a combination intended to let developers build autonomous agents that interact with external tools and APIs and execute multi-step workflows reliably.
Architecturally, the lineup spans both dense and sparse designs. The 26B MoE model activates only 3.8 billion parameters during inference to deliver fast tokens-per-second, while the 31B dense variant targets workloads where consistent per-token cost matters more than peak parameter count. The edge models, sized for mobile and IoT devices where memory and power budgets are tight, offer a 128K context window; the larger models extend to 256K tokens, large enough to ingest sizable code repositories or long-form documents in a single prompt.
All four variants natively process video and images at variable resolutions, and the E2B and E4B edge models add native audio input for speech recognition and understanding, and the family is trained on more than 140 languages. On benchmarks, Google reports that the 31B dense model achieved an estimated LLMArena score (text only) of 1452, reaching a performance bracket usually reserved for significantly larger models with triple to quintuple the parameter count.
Source: Google blog
Reactions in the open-model community have focused less on raw scores and more on usability and new licensing. Sam Witteveen applauded the Apache 2.0 license. This is an actual real Apache 2 license, which means for the first time, you can take Google's best open model, modify it, fine tune it, deploy it commercially, do whatever you want with it. No strings attached
Nathan Lambert argues that Gemma 4's value lies in its frictionless integration, noting: Gemma 4's success is going to be entirely determined by ease of use, to a point where a 5-10% swing on benchmarks wouldn't matter at all. It's strong enough, small enough, with the right license, and from the U.S., so many companies are going to slot it in.
Day-zero distribution is notably broad: weights are available on Hugging Face, Kaggle, with reference paths through vLLM, llama.cpp, Ollama, MLX, LM Studio, Unsloth, SGLang, and NVIDIA NIM, plus an NVFP4 quantized 31B checkpoint using NVIDIA Model Optimizer. Kaggle is running Gemma 4 Good Challenge, inviting developers to build products that create meaningful positive change using the new models.

The Apache 2.0 license represents a significant shift in Google's approach to open models. Previous Gemma releases came with usage restrictions that limited commercial deployment and derivative works. By removing these constraints, Google positions Gemma 4 as a truly open alternative to proprietary models while maintaining the quality and performance expected from a major tech company.
For enterprise developers, this licensing change removes a major barrier to adoption. Companies can now fine-tune Gemma 4 on proprietary data, integrate it into commercial products, and deploy it on their own infrastructure without worrying about compliance issues or usage caps. The combination of strong performance, multimodal capabilities, and permissive licensing makes Gemma 4 particularly attractive for applications requiring on-device inference or custom model adaptation.
The multimodal capabilities deserve special attention. Native video and image processing across all variants means developers can build applications that understand visual content without requiring separate vision models or complex orchestration. The edge models' audio input support extends this to speech recognition and audio understanding, creating a unified model family capable of handling text, images, video, and audio through a single interface.
Context window sizes represent another practical advantage. The 256K token capacity on larger models enables processing of entire codebases, lengthy documents, or extended conversations without the need for complex context management or summarization strategies. This is particularly valuable for code analysis, document processing, and applications requiring long-term memory of previous interactions.
The architectural choices reflect different deployment scenarios. The 26B MoE model offers a compelling balance for cloud deployments, activating only 3.8B parameters while delivering performance competitive with much larger dense models. This efficiency translates to lower inference costs and faster response times. The 31B dense model, while larger, provides consistent performance characteristics that may be preferable for certain workloads where predictability matters more than peak efficiency.
Edge variants target the growing market for on-device AI. With 2B and 4B effective parameters, these models can run on smartphones, IoT devices, and embedded systems while still offering multimodal understanding and substantial context windows. The 128K context window on edge models is particularly impressive for their size class, enabling sophisticated on-device applications without cloud connectivity.
Benchmark results suggest Gemma 4 competes effectively with much larger models. The 31B dense variant's estimated LLMArena score of 1452 places it in territory typically occupied by models with 90B-150B parameters. This efficiency gain has significant implications for deployment costs and environmental impact, as smaller models require less computational resources for both training and inference.
The GPQA Diamond score of 84.3% demonstrates strong scientific reasoning capabilities, nearly doubling the previous generation's performance. This improvement suggests Google has made significant advances in the model's ability to handle complex reasoning tasks, which is crucial for applications in research, education, and technical domains.
LiveCodeBench v6 performance at 80.0% indicates robust code generation and understanding capabilities. Combined with the tool use features like function calling and structured JSON output, Gemma 4 appears well-suited for building autonomous coding agents and development tools that can interact with APIs and development environments.
Distribution strategy appears comprehensive, with support for major inference frameworks and optimization tools. The availability of quantized versions through NVIDIA Model Optimizer addresses the need for efficient deployment on GPU infrastructure. Support for frameworks like vLLM, llama.cpp, and Ollama ensures compatibility with existing deployment pipelines and toolsets.
The Kaggle challenge represents an interesting approach to community engagement. By inviting developers to build products that create positive change, Google not only promotes Gemma 4 but also encourages exploration of its capabilities in real-world applications. This strategy could accelerate adoption and surface novel use cases that Google's internal teams might not have considered.
For the broader AI ecosystem, Gemma 4's release under Apache 2.0 could influence how other companies approach open model licensing. The combination of strong performance, comprehensive capabilities, and truly open licensing creates pressure for competitors to offer similar terms if they want to remain competitive in the open model space.
Development teams considering Gemma 4 should evaluate their specific needs against the model family's characteristics. The edge variants offer compelling options for on-device applications requiring multimodal understanding, while the larger models provide the capacity for complex reasoning and long-context processing. The Apache 2.0 license removes licensing concerns, but teams should still consider factors like inference costs, deployment infrastructure, and integration complexity.
Integration patterns will likely evolve as developers explore Gemma 4's capabilities. The native tool use features suggest a natural fit for agent architectures where the model needs to interact with external systems. The multimodal processing capabilities could enable unified applications that handle text, images, video, and audio through a single model interface, simplifying architecture compared to systems that orchestrate multiple specialized models.
Performance characteristics will vary significantly based on deployment configuration. The 26B MoE model's efficiency advantages make it attractive for cost-sensitive cloud deployments, while the 31B dense model's consistent performance may be preferable for applications requiring predictable latency. Edge variants will have different performance profiles depending on the target hardware, with quantization and optimization playing crucial roles in achieving acceptable inference speeds.
Looking forward, Gemma 4's release under Apache 2.0 could accelerate the development of a more vibrant open model ecosystem. By removing licensing barriers while maintaining high performance standards, Google enables broader experimentation and commercial adoption. This could lead to faster innovation cycles as developers build on Gemma 4's foundation without worrying about usage restrictions.
The focus on agentic capabilities aligns with broader industry trends toward autonomous systems. As models become more capable of tool use and multi-step reasoning, the distinction between traditional applications and AI agents may blur. Gemma 4's architecture and features position it well for this evolution, with native support for the patterns required by autonomous systems.
For organizations evaluating AI models for production use, Gemma 4 presents a compelling option. The combination of strong performance, multimodal capabilities, permissive licensing, and broad framework support addresses many common concerns about model adoption. The real test will be how easily developers can integrate these capabilities into their applications and whether the performance advantages translate to tangible business value.

Comments
Please log in or register to join the discussion