Union-Find is the textbook answer for grouping duplicate records, and it works beautifully right up until your data has noise and your graph has billions of edges. Rohit Muthyala, a Principal Software Engineer at ZoomInfo, walks through why the algorithm's greatest strength becomes its fatal flaw at scale, and what weighted graph clustering offers instead.
Entity resolution is the unglamorous problem sitting underneath nearly every data platform that matters. You have millions of records about companies, people, or products, scattered across feeds that never agreed on a spelling, an address format, or a phone number. Some of those records describe the same real-world thing. Your job is to figure out which ones, and to do it across petabytes without melting your cluster.
The standard first instinct is Union-Find. It is elegant, it is fast, and it is taught in every data structures course as the canonical way to track connected components. It is also, at web scale with noisy data, a quiet disaster. Understanding exactly why is a useful lesson in the gap between algorithmic elegance and production reality.
What Union-Find actually does
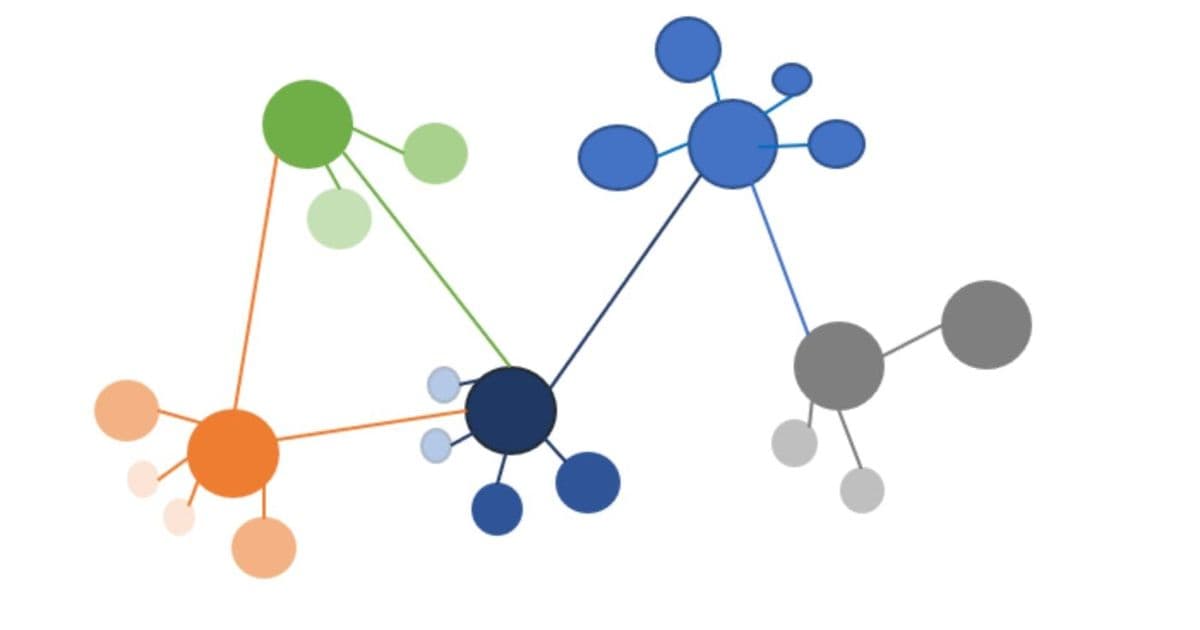
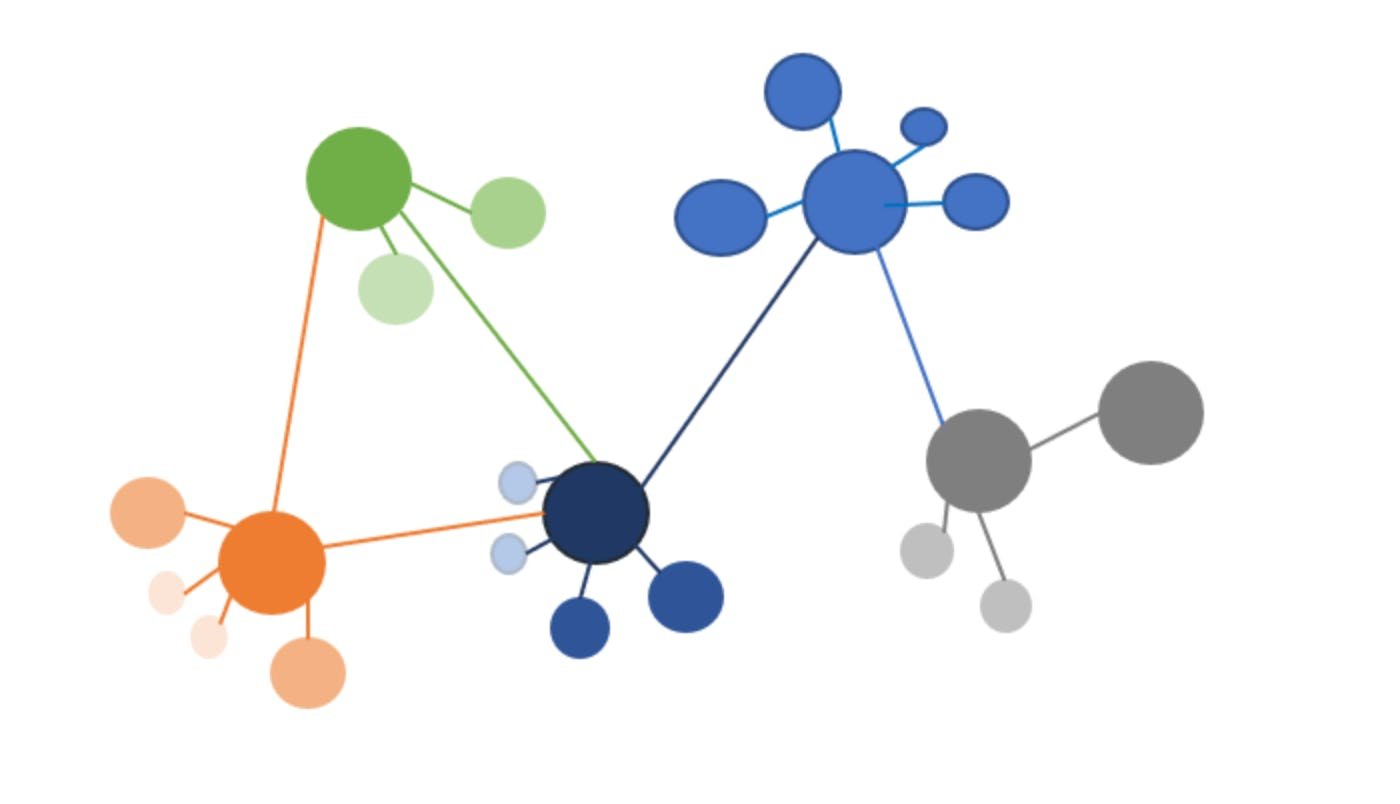
Union-Find, also called Disjoint Set Union, answers one question extremely well: given a pile of pairwise relationships, which items end up in the same group? You feed it edges. Record A matches record B. Record B matches record C. It maintains a forest of trees where every element points toward a representative root, and with path compression and union by rank, the amortized cost per operation is nearly constant. The classic analysis gives you the inverse Ackermann function, which for any input you will ever see is effectively a small constant.
For entity resolution, the pipeline looks deceptively clean. A matching model compares record pairs and emits a verdict: these two are the same entity. You take every positive verdict as an edge, throw it all into Union-Find, and read off the connected components. Each component is a resolved entity. Done in one pass.
That is the version that works in a demo on ten thousand rows. The trouble starts when the inputs stop being clean.
The transitivity trap
Union-Find has no concept of doubt. An edge is an edge. If A connects to B and B connects to C, then A, B, and C are the same entity, full stop. The algorithm enforces transitivity unconditionally, and it cannot be talked out of it.
Real matching models do not produce certainty. They produce scores. The match between A and B might carry 0.97 confidence. The match between B and C might be a shaky 0.55, the kind of pair that shares a generic company name and a city but little else. On their own, neither edge is a problem. Chained together through Union-Find, that weak B-to-C link silently merges A into C even though nothing ever suggested A and C are related.
Now scale that up. In a graph with billions of edges, weak links are not rare events. They are everywhere. Each one is a potential bridge between two otherwise unrelated clusters, and Union-Find will happily walk across every bridge it is handed. The failure mode is not subtle. You get giant connected components, sometimes millions of records collapsed into a single supposed entity, because a chain of individually plausible matches stitched together a continent of records that have nothing to do with each other.
Practitioners have a name for this. They call it the monster cluster, or the blob. Once it forms, it poisons everything downstream. A single resolved entity now claims to be a thousand different companies, and no amount of cleanup short of recomputation will untangle it.
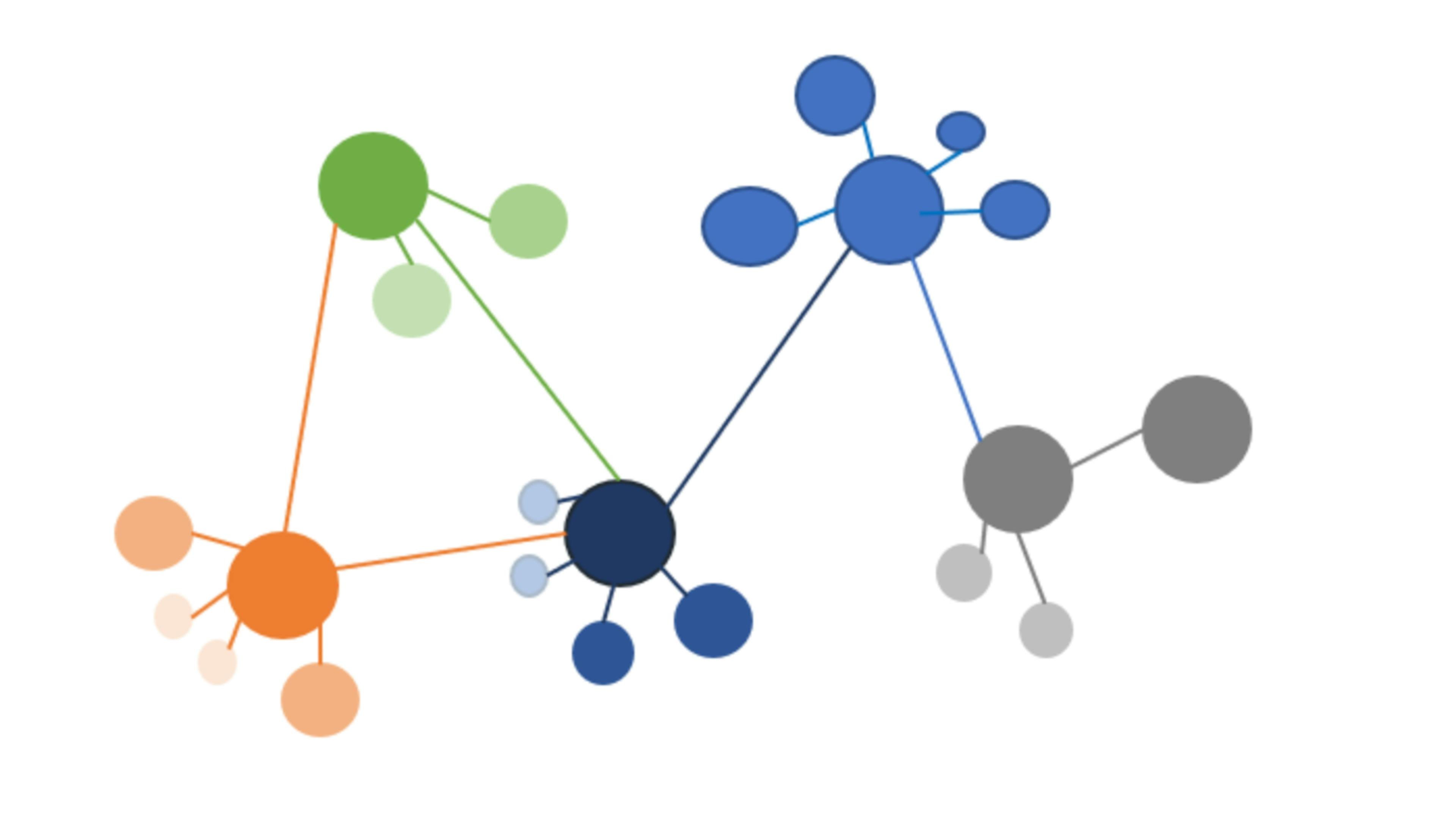
Why noise makes it worse, not better
The intuition that more data should improve resolution is reasonable and, with Union-Find, exactly backwards. Adding records adds candidate edges. Adding candidate edges adds opportunities for weak bridges. The probability that some chain of marginal matches connects two large clusters grows as the graph densifies, so the blob problem gets worse precisely as your dataset gets more valuable.
There is also a structural reason the algorithm cannot defend itself. Union-Find discards information the moment it ingests it. The score on each edge, the only signal that could distinguish a strong link from a weak one, is thrown away before the union happens. By the time you discover a monster cluster, the algorithm has no memory of which edges were load-bearing and which were flimsy. You cannot ask it to reconsider, because it kept nothing to reconsider with.
Weighted graph clustering as the alternative
The fix is to stop treating resolution as a connectivity problem and start treating it as a clustering problem. Keep the edge weights. Let the matching model's confidence flow all the way through to the grouping step, and use an algorithm that can decide a cluster is internally too weak to hold together.
This is the domain of weighted graph clustering. Instead of asking whether two records are reachable through any path, you ask whether a proposed group is densely and strongly connected relative to its links to the outside. A cluster held together by one thin thread should be cut. A cluster where most members strongly agree with most other members should survive. Correlation clustering formalizes exactly this trade-off, optimizing for agreement within clusters against disagreement across them, and it tolerates the contradictory evidence that noisy data inevitably produces.
The operational difference is that these methods can refuse to merge. When a weak edge tries to bridge two strong clusters, a weighted algorithm weighs that single thin connection against the dense internal structure on either side and declines. The bridge is cut, the two real entities stay separate, and the blob never forms. You trade the constant-time elegance of Union-Find for a more expensive computation, but you get correctness on inputs where Union-Find produces confident nonsense.
The engineering cost is real
None of this is free, and the honest framing matters more than the pitch. Weighted clustering is harder to parallelize than Union-Find, which distributes almost trivially. Many of the better formulations are NP-hard, so production systems lean on approximations, local optimization, and iterative refinement rather than exact solutions. On a platform like Apache Spark, getting connected-component-style work to run efficiently across a cluster already takes care, and weighted variants add another layer of partitioning and communication overhead.
The practical pattern that tends to win is a hybrid. Use cheap, high-precision blocking and a Union-Find-style pass to carve the universe into manageable candidate groups, then apply weighted clustering inside each group where the expensive computation is bounded and the blob risk is contained. You get the throughput of the simple algorithm for the easy ninety percent and the discernment of the expensive one where it actually pays off.
The broader lesson generalizes past entity resolution. Union-Find fails here not because it is a bad algorithm but because it answers a different question than the one the data is asking. Connectivity assumes every edge is true. Real-world matching produces edges that are merely probable, and probability does not chain cleanly. Any system that funnels uncertain pairwise judgments into an algorithm that demands certainty will manufacture the same kind of monster, whether the entities are companies, identities, or anything else worth resolving. The discipline is matching the algorithm to the actual shape of the evidence, and at web scale that evidence is always noisier than the textbook assumed.
Comments
Please log in or register to join the discussion