A new class of command‑line utilities is helping developers match local large language models to their hardware. By combining real‑world benchmarks, quant‑aware VRAM estimates, and automated model fetching, projects such as whichllm aim to replace size‑only heuristics. The article examines the signal these tools provide, the community response, and the criticisms around benchmark opacity and ecosystem fragmentation.
Hardware‑Aware LLM Pickers: Why Tools Like whichllm Are Gaining Traction
Local inference of large language models (LLMs) has moved from a hobbyist curiosity to a production‑level requirement. As GPUs like the RTX 4090 or Apple M3 Max become affordable, developers are eager to run models offline for privacy, latency, or cost reasons. The hard part is not buying a card—it’s deciding which model actually fits and performs best on the specific hardware you have.
The observation: a shift from "fit‑by‑size" to "fit‑by‑performance"
Historically, the community relied on simple size checks: "If it fits in 24 GB VRAM, you’re good." That approach ignores two critical dimensions:
- Quantization impact – A 27 B model quantized to Q5_K_M can run faster and use less memory than a 32 B model at Q4_K_M.
- Real‑world benchmark quality – Newer generations often outperform older, larger models even when the raw parameter count suggests otherwise.
The GitHub project whichllm embodies this shift. A single command (whichllm --gpu "RTX 4090") scans HuggingFace, estimates VRAM consumption (weights + KV cache + activation + overhead), pulls live benchmark data from sources like LiveBench and the Open LLM Leaderboard, and returns a ranked list. The top entry for an RTX 4090 is currently Qwen/Qwen3.6‑27B (Q5_K_M, ~27 tokens / s, score 92.8), even though a 32 B variant would also fit.
Evidence supporting the approach
- Live benchmark integration – whichllm merges multiple evaluation tracks (Chatbot Arena ELO, Aider coding tests, multimodal vision scores) and applies confidence weighting. This reduces reliance on a single, possibly noisy metric.
- Recency awareness – Stale leaderboard entries are demoted, preventing a 2022‑era model from outranking a 2024 release solely on raw score.
- Evidence grading – Direct benchmark results are weighted highest; self‑reported scores are heavily discounted. The system even rejects forks that inherit scores from a much larger base model, limiting score inflation.
- Quant‑aware VRAM modeling – The tool accounts for per‑quant byte size, GQA KV cache, and a fixed overhead (~500 MB). This yields more accurate fit predictions than a naïve parameter‑count check.
- One‑command workflow – Beyond ranking, whichllm can instantly spin up a chat (
whichllm run) or emit ready‑to‑paste Python snippets for llama‑cpp, AWQ, or GPTQ backends. This reduces friction for developers who would otherwise stitch together multiple scripts.
Counter‑perspectives and concerns
While the community has largely welcomed hardware‑aware pickers, several criticisms have emerged:
- Benchmark opacity – The ranking algorithm relies on a proprietary weighting scheme. Users who cannot audit the exact contribution of each source may distrust the final score, especially when a lower‑parameter model is recommended over a larger, well‑known baseline.
- Fragmentation risk – Projects like whichllm, Ollama’s model selector, and various Python notebooks each implement their own heuristics. This could split community effort and make it harder to converge on a single, trusted reference.
- Dependency on HuggingFace API – Rate limits and occasional metadata inconsistencies can cause stale or missing entries, forcing the tool to fall back on cached data that may be out‑of‑date.
- Speed estimation simplifications – Token‑per‑second predictions are derived from theoretical memory bandwidth and quant efficiency. Real‑world performance can vary dramatically with driver versions, system load, or mixed‑precision settings, leading to over‑optimistic expectations.
- Security and licensing – Auto‑downloading models without explicit user review may pull in licenses or content that conflict with corporate policies. Some enterprises prefer a curated model registry rather than an open‑source fetch‑on‑demand approach.
The broader pattern: evidence‑driven tooling for LLM ops
whichllm is part of a growing ecosystem of evidence‑driven ops utilities:
- Ollama now ships with a model‑selection command that queries its own curated index.
- LM‑Studio includes a UI that shows VRAM estimates and benchmark scores side‑by‑side.
- AutoGPT‑Quant adds automatic quantization selection based on target hardware.
All share a common goal: reduce the manual guesswork that used to dominate local inference setups. By exposing a JSON API (whichllm --json | jq …), these tools also enable pipeline automation—CI jobs can verify that a given hardware profile will meet a latency SLA before committing to a model version.
Looking ahead: what needs to improve?
- Transparent scoring dashboards – An open‑source web UI that visualizes each factor (benchmark source, confidence, quant penalty) would make the ranking process auditable.
- Standardized benchmark metadata – A community‑maintained schema for reporting evaluation results could reduce the need for heavy discounting of self‑reported scores.
- Cross‑tool compatibility layers – A shared JSON schema for model capability descriptors would let whichllm, Ollama, and LM‑Studio exchange rankings without re‑parsing each other's output.
- Enterprise‑grade safety nets – Optional whitelists for approved model licenses and provenance checks could address corporate security concerns.
Bottom line
Tools like whichllm illustrate a maturing approach to local LLM deployment: move beyond raw parameter counts, incorporate live benchmark evidence, and automate the entire fetch‑run cycle. The community response has been largely positive, as evidenced by the project's star growth and active issue discussions. However, the utility’s impact will hinge on greater transparency, standardization, and integration with broader LLM‑ops workflows.
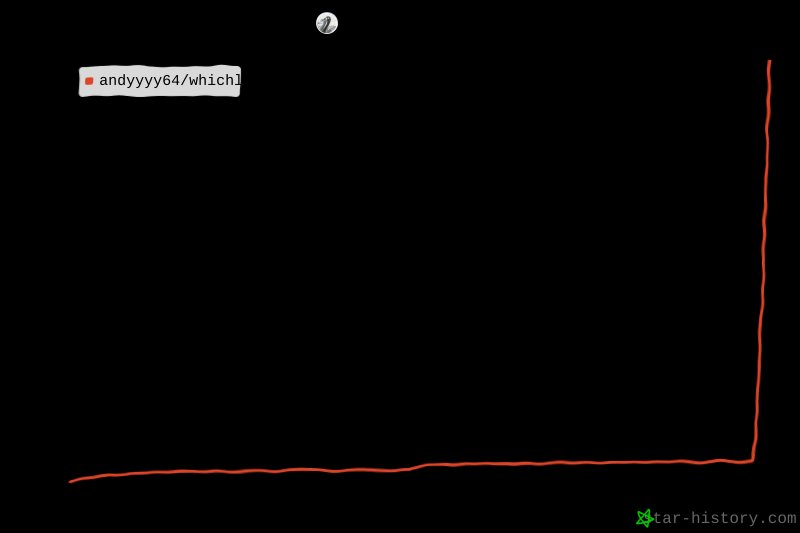
If you run whichllm on your rig, consider starring the repo and sharing the selected model in the Issues section. Community data helps keep the rankings accurate and the tool useful for everyone.
Comments
Please log in or register to join the discussion