Traffic spikes do not create weak architecture, they reveal it. The systems that survive are usually the ones that already separated request handling, background work, caching, and database pressure before the spike arrived.
Problem
Traffic spikes are a reliability test disguised as a growth problem. A sudden 3x or 10x increase in requests can come from a product launch, a social post, a partner integration, a retry storm, a bot wave, or a downstream system recovering all at once. The cause matters, but the failure mode is usually familiar: application instances saturate, queues grow without bounds, database connections run out, latency climbs, retries multiply the load, and eventually the system starts failing in places that were never meant to be user-visible.
Most production outages during load surges are not caused by one bad line of code. They happen because the architecture assumes normal traffic. Normal traffic is a comfortable liar. It hides local state, inefficient queries, synchronous side effects, weak backpressure, and brittle deployment assumptions. The system looks fine until the request rate changes faster than humans can respond.
On AWS, the useful pattern is not simply “add more servers.” Compute is often the easiest part to scale. The harder question is where the pressure goes after the compute tier expands. If every new instance opens more database connections, repeats the same cache misses, performs the same synchronous work, and retries failed dependencies without coordination, horizontal scaling can make the outage arrive faster.
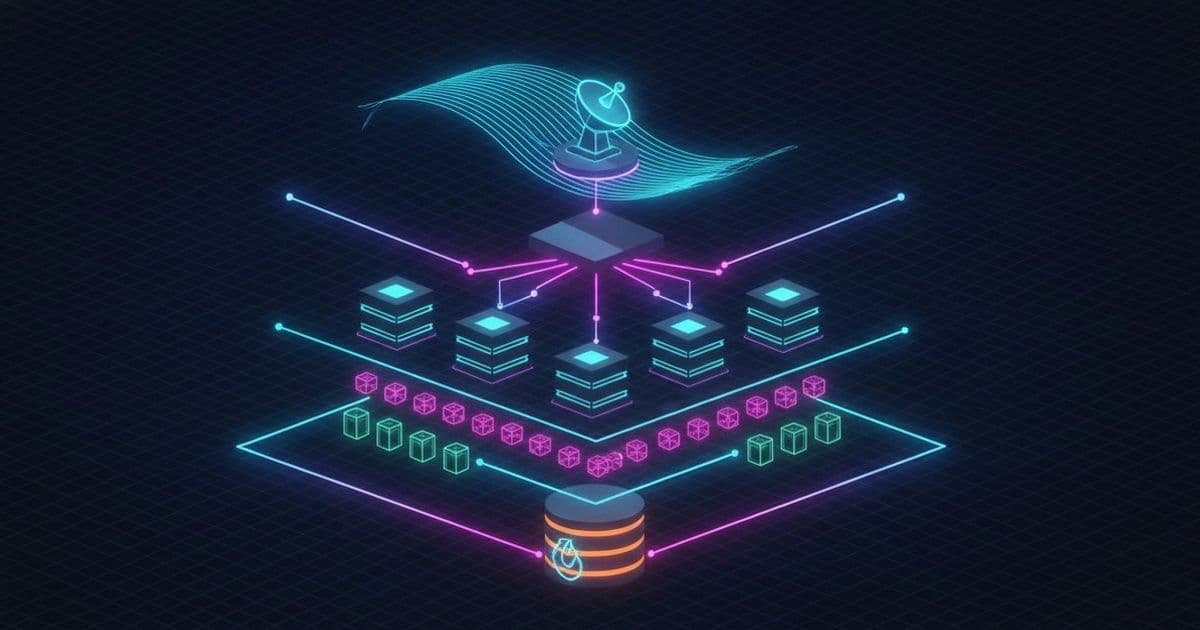
A production-ready AWS design treats sudden traffic as a distribution problem. The system needs layers that absorb, shed, delay, cache, and route load before the database or a critical dependency becomes the only thing left standing.
Useful reference points include the AWS Well-Architected Framework, Elastic Load Balancing, Amazon EC2 Auto Scaling, Amazon SQS, Amazon CloudFront, Amazon ElastiCache, and Amazon RDS read replicas.
Solution Approach
1. Make the Application Layer Stateless
Stateless services are the foundation for predictable horizontal scaling. Any healthy instance should be able to serve any request. If user sessions, uploaded files, temporary workflow state, or request coordination live on a single instance, scaling becomes fragile. The load balancer can send a user to an instance that does not have their session. A replacement instance can come up empty. A deployment can destroy state that the application quietly depended on.
A practical stateless design moves session data into a shared store such as Redis through Amazon ElastiCache for Redis, moves files into Amazon S3, and treats each application instance as disposable. Local disk can still be used for temporary scratch space, but correctness should not depend on it.
This changes the scaling problem. Instead of asking whether a specific server can keep up, the system asks whether the fleet can keep up. That is the right question for AWS because instance count, container count, and task count can be adjusted automatically when the application does not carry hidden local state.
2. Put Load Balancing in Front of the Fleet
An Application Load Balancer gives the system a stable entry point and spreads requests across healthy targets. It also provides health checks, routing rules, TLS termination, and integration with Auto Scaling groups, ECS services, and EKS ingress patterns.
The load balancer is not magic capacity. It is a traffic director. Its job is to avoid concentrating traffic on one instance while others are idle. During scale-out, it also gives new instances a controlled way to enter service after they pass health checks.
The key operational detail is health check quality. A shallow health check that returns 200 while the process is half-broken can keep sending traffic to a bad instance. A health check that depends on every downstream system can remove the entire fleet during a dependency incident. Good health checks distinguish “this process can accept traffic” from “every dependency is perfect.”
3. Use Auto Scaling, but Do Not Treat It as Instant Capacity
Auto Scaling helps absorb sustained traffic increases by adding compute when metrics cross thresholds. Common scaling signals include CPU utilization, request count per target, memory pressure, queue depth, and custom application metrics published through Amazon CloudWatch.
For request-serving services, request count per target is often more meaningful than CPU alone. A service can be overloaded because it is waiting on database connections, remote APIs, or locks while CPU appears moderate. Latency and saturation metrics usually tell a better story than average CPU.
Auto Scaling has delay. Instances need time to launch, containers need time to pull images, applications need time to warm caches and connection pools, and load balancers need time to mark targets healthy. For predictable events, scheduled scaling is often better than waiting for alarms. For unpredictable events, keep a reasonable minimum capacity and avoid running production at the edge of saturation during normal traffic.
4. Move Heavy Work Out of the Request Path
The fastest request is the one that does not do unnecessary work synchronously. During traffic spikes, every synchronous side effect competes with user-facing latency. Email sending, report generation, image processing, workflow fanout, analytics writes, and third-party notifications should usually go through a queue.
A common AWS pattern is: API receives request, validates it, writes the durable state change, publishes a message to Amazon SQS, then returns. Workers, Lambda functions, ECS tasks, or Kubernetes jobs process the queued work in the background.
Queues change the failure model. Instead of forcing the user request to wait for every downstream action, the system accepts work quickly and processes it at a controlled rate. Queue depth becomes a pressure gauge. If depth rises during a spike but drains afterward, the system is bending rather than breaking.
The hard part is idempotency. Queues typically provide at-least-once delivery. A worker may receive the same message more than once, especially after timeouts or partial failures. Handlers need idempotency keys, deduplication records, conditional writes, or natural uniqueness constraints. Without that, async processing trades latency failures for duplicate side effects.
5. Cache at the Right Layers
Caching reduces repeated work, but it must be placed where it matches the data’s consistency needs. Amazon CloudFront is effective for static assets and cacheable HTTP responses. API Gateway caching can help for specific API responses. ElastiCache is useful for application-level data that is expensive to compute or repeatedly read.
Good cache candidates include static files, product catalogs, public configuration, feature metadata, precomputed summaries, and read-heavy responses where bounded staleness is acceptable. Poor candidates include data that must reflect every write immediately, unless the system has a clear invalidation strategy.
The consistency model needs to be explicit. A cache introduces the possibility that a reader sees old data. That may be fine for a feed count, recommendation list, or public article page. It may be unacceptable for payment state, inventory reservation, access control, or account balance. The mistake is not using stale data. The mistake is using stale data without deciding where staleness is allowed.
6. Serve Static and Cacheable Content from the Edge
Many traffic spikes are dominated by assets and repeat reads. Serving static content through S3 and CloudFront keeps that load away from the application tier. Edge caching also improves latency for users far from the origin.
The practical architecture is simple: store static assets in S3, put CloudFront in front, set cache-control headers carefully, and use versioned asset names for long-lived browser and CDN caching. Immutable file names such as app.4f3a9c.js are easier to cache aggressively because a new deployment creates a new name.
For dynamic pages and APIs, CloudFront can still help when responses vary by path, header, cookie, or query string in controlled ways. The risk is cache key explosion. If every request has a unique cookie or query parameter and the cache policy varies on all of it, the CDN becomes a pass-through layer with extra complexity.
7. Protect the Database First
The database is usually the first expensive bottleneck. Compute fleets scale horizontally. Primary relational databases have harder limits around writes, locks, indexes, connection count, replication lag, and storage throughput.
Read replicas can help when the workload is read-heavy. RDS read replicas allow applications to route some read traffic away from the primary. This works well for data that can tolerate replication lag. It works poorly for read-after-write paths where the user expects to immediately see their own update.
Connection pooling is often more urgent than bigger hardware. A spike that adds application instances can multiply database connections until the database spends too much time managing sessions. Tools such as RDS Proxy can reduce connection churn for many relational workloads.
Query shape matters as much as database size. Missing indexes, unbounded scans, chatty request patterns, and repeated lookups can destroy capacity during spikes. Before scaling hardware, inspect slow queries, index selectivity, N+1 access patterns, transaction duration, and lock contention. Scaling a bad query often means paying more to fail later.
8. Add Backpressure and Graceful Degradation
A system under extreme load needs ways to say no. Without backpressure, overload moves inward until the least scalable component fails. Rate limiting, throttling, circuit breakers, bounded queues, request deadlines, and retry budgets all exist to keep overload from becoming a cascade.
Rate limiting protects shared APIs from a small number of aggressive clients. AWS WAF rate-based rules, API Gateway throttling, and application-level limiters can all play a role.
Circuit breakers stop repeated calls to a failing dependency and give it time to recover. Retries should use exponential backoff with jitter. A retry without backoff is often just a traffic amplifier. During partial failure, thousands of clients retrying at the same interval can produce a second wave larger than the first.
Graceful degradation means deciding which features can be disabled while core flows continue. Search suggestions can disappear before checkout fails. Analytics writes can queue before login fails. Personalization can fall back to defaults before the homepage becomes unavailable. These choices are product decisions implemented as engineering controls.
9. Instrument the System Around Saturation
Observability should describe where capacity is being consumed. Averages are not enough. Track p95 and p99 latency, error rates, request rate, queue depth, worker age, database connections, connection pool wait time, cache hit ratio, throttling, retry counts, and dependency latency.
CloudWatch metrics and alarms are a baseline. Distributed tracing through tools such as AWS X-Ray or OpenTelemetry-based systems can show where requests spend time. Structured logs help correlate failures across services.
The goal is not dashboards for their own sake. The goal is to answer production questions quickly: Is the edge cache helping? Are requests waiting on the database? Is queue depth rising faster than workers can drain it? Is one dependency causing retries? Are new instances actually receiving traffic? During an incident, vague visibility is almost the same as no visibility.
Trade-offs
The layered architecture looks clean on a diagram: client to CDN, CDN to load balancer, load balancer to application fleet, application to queues and workers, workers and services to databases and caches. In production, every layer introduces a contract.
Stateless services improve scaling, but shared session stores and object storage become dependencies that need their own capacity planning. Load balancers distribute traffic, but health check design can create false confidence or false removal. Auto Scaling reduces manual work, but it reacts after metrics move unless capacity is pre-warmed or scheduled. Queues protect latency, but they require idempotency, visibility timeout tuning, dead-letter handling, and operational ownership of backlog.
Caching can remove enormous load, but it asks the system to define acceptable staleness. Read replicas increase read capacity, but they introduce replication lag and routing complexity. Rate limits protect the platform, but they can reject legitimate traffic during the exact moment users care most. Circuit breakers reduce cascading failure, but a bad threshold can disable useful work too early.
That is the core engineering trade-off: resilience is not free capacity. It is a set of explicit failure modes chosen ahead of time.
A practical AWS traffic-spike design usually starts with these defaults:
- CloudFront in front of static and cacheable content.
- An Application Load Balancer in front of stateless application instances or containers.
- Auto Scaling based on request pressure and saturation metrics, not CPU alone.
- SQS or another queue for non-critical and heavy background work.
- ElastiCache for hot reads where bounded staleness is acceptable.
- RDS read replicas or equivalent read scaling where the consistency model permits it.
- Connection pooling to keep the database from drowning in sessions.
- Rate limits, retry budgets, backoff with jitter, and circuit breakers.
- Dashboards and alarms focused on p95, p99, queue depth, database pressure, and error rates.
The systems that survive sudden traffic rarely do so because one AWS service saved them. They survive because load is split into categories: cacheable requests, interactive requests, background work, reads, writes, retries, and abusive traffic. Each category gets a different path and a different failure policy.
A spike should not force every request through the most expensive part of the system. It should hit the edge first, then the load balancer, then an elastic stateless fleet, then queues and workers, and only then the database under controlled access. When that ordering is designed intentionally, a traffic spike becomes an operating condition rather than a surprise architecture review at 2 a.m.
Comments
Please log in or register to join the discussion