A CDN switch dropped API latency from 320ms to 95ms with zero server changes. The reason is a protocol decision most teams get backwards: QUIC on the lossy last mile, TCP on the stable datacenter leg.
Your API response went from 320ms to 95ms after a CDN switch. Nothing changed on the server. Same origin, same payload, same code path. The only difference: the CDN started speaking HTTP/3 to your clients. If that result feels like magic, it isn't. It's the predictable outcome of moving the right protocol to the right segment of the network, and the reasoning behind it is sharper than most architecture debates make it out to be.
The problem: where latency actually lives
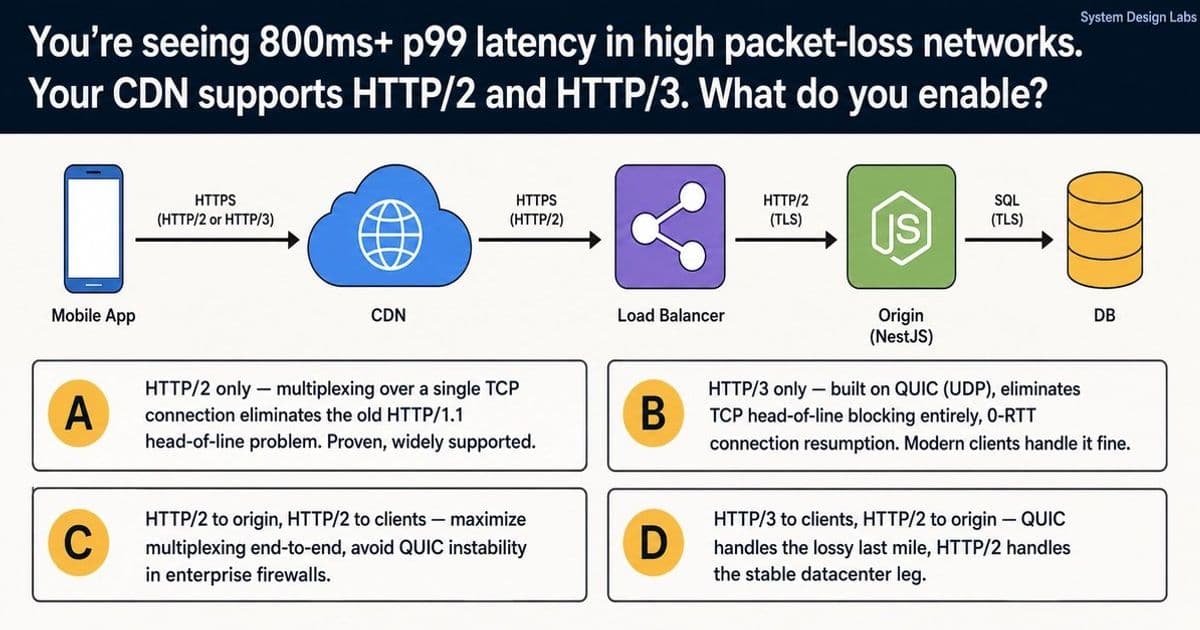
Consider a common topology. A mobile app talks to a load balancer, which forwards to a NestJS origin, which talks to a database. Every request passes through a CDN first. Under good conditions, latency is fine. The trouble shows up in high packet-loss environments: 4G-to-5G handoffs, flaky coffee-shop WiFi, long Asia-Pacific routes. That's where p99 tail latency balloons past 800ms while your median request looks healthy.
The instinct is to blame the origin or the database. Usually that's wrong. When your median is fine and only the tail degrades, and the degradation correlates with network quality rather than load, the bottleneck is the transport layer on the last mile. The fix lives in protocol selection, not in your application code.
The CDN supports both HTTP/2 and HTTP/3. The question is what to enable, and the four plausible answers expose how well a team understands what each protocol actually does.
The four options
Option A, HTTP/2 only. Multiplexing over a single TCP connection killed HTTP/1.1's head-of-line problem. It's proven and supported everywhere.
Option B, HTTP/3 only. Built on QUIC over UDP, it eliminates TCP head-of-line blocking entirely and adds 0-RTT connection resumption. Use it everywhere, including to the origin.
Option C, HTTP/2 end-to-end. Maximize multiplexing on both legs, sidestep QUIC instability inside enterprise firewalls.
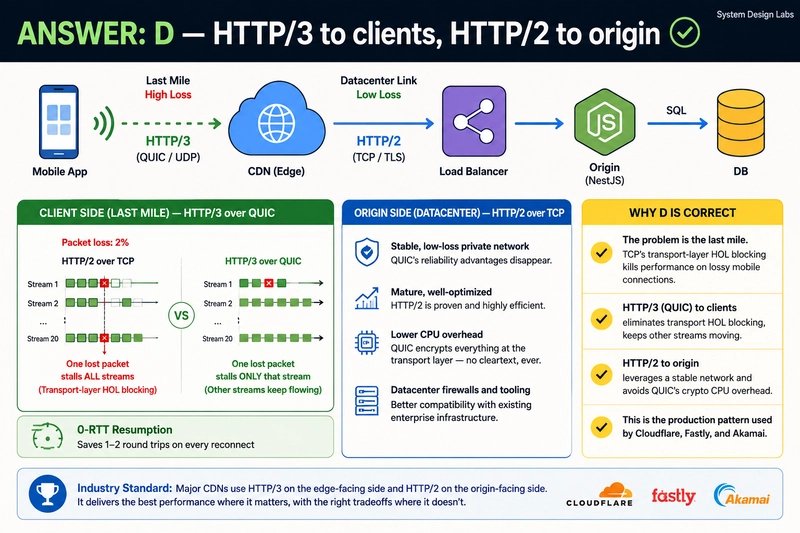
Option D, HTTP/3 to clients, HTTP/2 to origin. QUIC handles the lossy last mile, HTTP/2 handles the stable datacenter leg.
The answer that Cloudflare, Fastly, Akamai, and Netflix actually run in production is D. The reasoning is worth working through, because the wrong options fail for instructive reasons.
Why the last mile breaks TCP
HTTP/2 solved a real problem. Under HTTP/1.1, browsers opened six parallel TCP connections per origin and still serialized requests within each one. HTTP/2 multiplexes many independent streams over a single connection, so a slow response no longer blocks everything queued behind it. That fixed head-of-line blocking at the application layer.
But it left a deeper problem untouched. TCP itself enforces in-order delivery at the transport layer. When a single packet is lost, TCP holds back every byte that arrived after it until the missing packet is retransmitted. Your application sees nothing until the gap is filled. With HTTP/2, all your multiplexed streams ride one TCP connection, so one lost packet stalls all of them simultaneously.
On a clean datacenter link this is invisible. On a 4G connection dropping two percent of packets, it's catastrophic. A 20-stream HTTP/2 connection grinds to a halt every time TCP waits out a retransmission window, and on mobile networks that window can be tens of milliseconds. This is precisely the regime where your p99 lives.
What QUIC changes
HTTP/3 runs on QUIC, which sits on top of UDP and reimplements the reliability, congestion control, and ordering that TCP used to provide, but per stream rather than per connection. Each stream is independent. A dropped packet stalls only the stream that lost it. The other 19 keep flowing. That single design choice is the entire reason latency collapses on lossy networks.
QUIC adds two more wins that matter on mobile. First, connection migration: because a QUIC connection is identified by a connection ID rather than the four-tuple of source and destination IP and port, a phone can move from WiFi to cellular without tearing down and rebuilding the session. TCP would force a full reconnect. Second, 0-RTT resumption. After a client has talked to a server once, subsequent connections can carry application data in the very first packet, skipping the handshake round trips. On a flaky link that reconnects constantly, shaving one or two round trips off every reconnect is where a large chunk of your tail latency savings comes from.
There's a security consequence baked in here too. QUIC encrypts essentially everything at the transport layer. There is no cleartext QUIC, the way there is cleartext TCP. The handshake folds TLS 1.3 directly into the transport, so even most of the connection metadata is protected. That's good for clients on hostile networks and one more reason it belongs on the edge.
Why HTTP/2 stays on the origin leg
If QUIC is so good, why not run it end-to-end? Because the origin-facing leg is a completely different network. The CDN-to-origin path is a stable, low-loss, often private connection. QUIC's headline benefit, independent streams that survive packet loss, simply doesn't pay off when packet loss is near zero. You're solving a problem that doesn't exist on that segment.
Meanwhile QUIC carries real costs there. Encrypting every packet at the transport layer burns CPU, and on a high-throughput origin link that overhead is measurable. HTTP/2 multiplexing over TCP is mature, kernel-accelerated, and well understood operationally. Running it on the stable leg gives you the multiplexing you want without paying QUIC's tax where it earns nothing.
This is the actual production pattern at the major CDNs: HTTP/3 on the edge-facing side, HTTP/2 or even HTTP/1.1 with keepalive on the origin-facing side. The split isn't a compromise, it's matching the protocol to the physics of each segment.
Why the other three options miss
Option A and Option C share the same flaw. Both stop at HTTP/2 on the client side, so both leave TCP head-of-line blocking fully in place on the exact segment where it hurts. "Clean and consistent end-to-end" sounds appealing in a design review, but consistency is not a performance property. It does nothing for your p99 on a lossy connection.
Option B fails operationally. Pushing HTTP/3 all the way to the origin introduces risk for no benefit. Plenty of enterprise firewalls and some cloud load balancers block or aggressively rate-limit UDP on port 443, because UDP floods are a classic amplification vector and security teams treat it with suspicion. Your origin infrastructure isn't the bottleneck, so wrapping that leg in QUIC just adds a new failure mode and more CPU cost while fixing nothing.
The broader pattern
The lesson generalizes well beyond CDN configuration. Protocol and infrastructure choices should follow the failure characteristics of each network segment, not a desire for uniformity. A lossy, high-latency, frequently-migrating mobile link wants a transport built to tolerate loss and migration. A stable private datacenter link wants the lowest-overhead mature option available. Forcing one protocol across both means either underperforming on the hard segment or overpaying on the easy one.
When you're debating a protocol upgrade, the useful question isn't "which protocol is newer or faster in benchmarks." It's "where does the loss happen, and which segment dominates my tail latency." Answer that, and the configuration usually picks itself. For deeper background, the QUIC RFC 9000 and HTTP/3 RFC 9114 specs are the primary sources, and Cloudflare's HTTP/3 documentation walks through how they deploy the edge-to-origin split in practice.
Comments
Please log in or register to join the discussion