Intel's 1980 math coprocessor was not fast because floating-point was magic. It was fast because a carefully tuned adder, carry path, shifters, and control logic turned hard math into measured transistor-level trade-offs.
Product
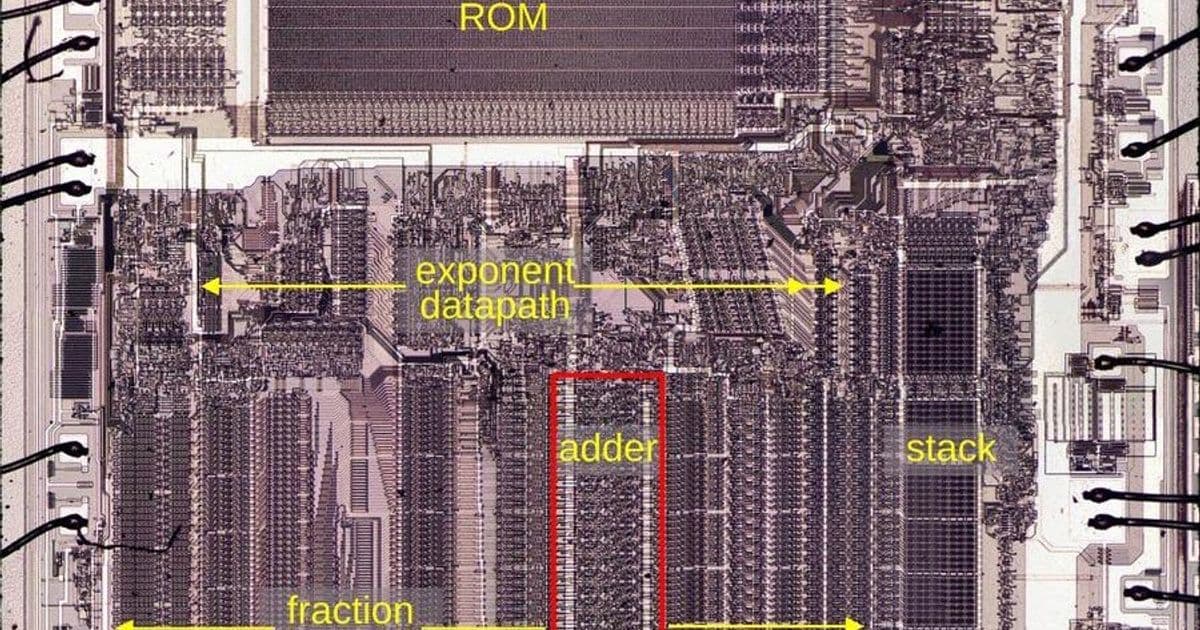
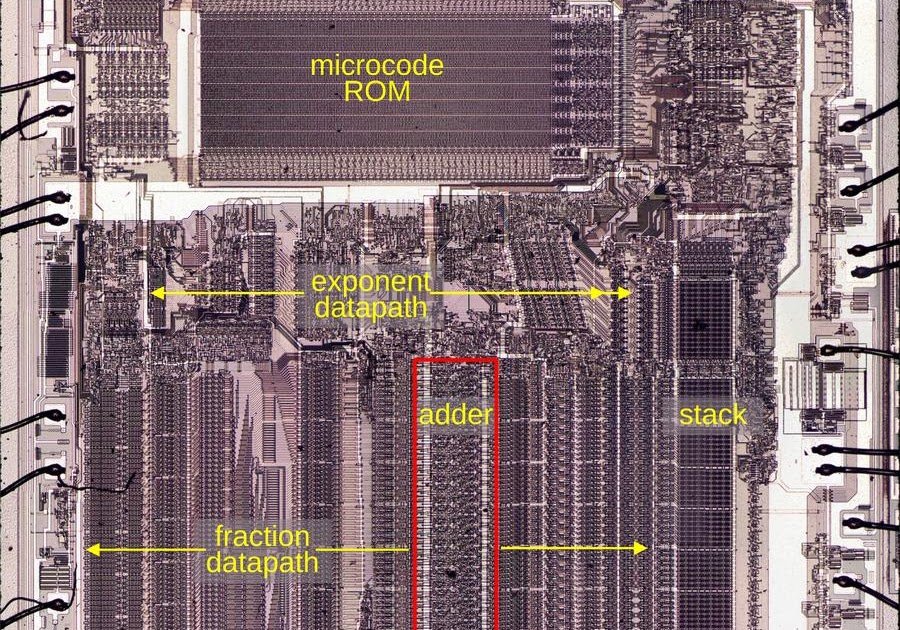
Intel's 8087 floating-point coprocessor is easy to remember as the chip that gave 8086 and 8088 systems hardware floating-point, but the more useful lesson is smaller and more physical: the machine lived or died by its adder. The reverse-engineered 8087 die work from Ken Shirriff shows a 68-bit fraction datapath centered on a carry-optimized adder, with surrounding registers, shifters, and control circuitry arranged to feed it again and again.
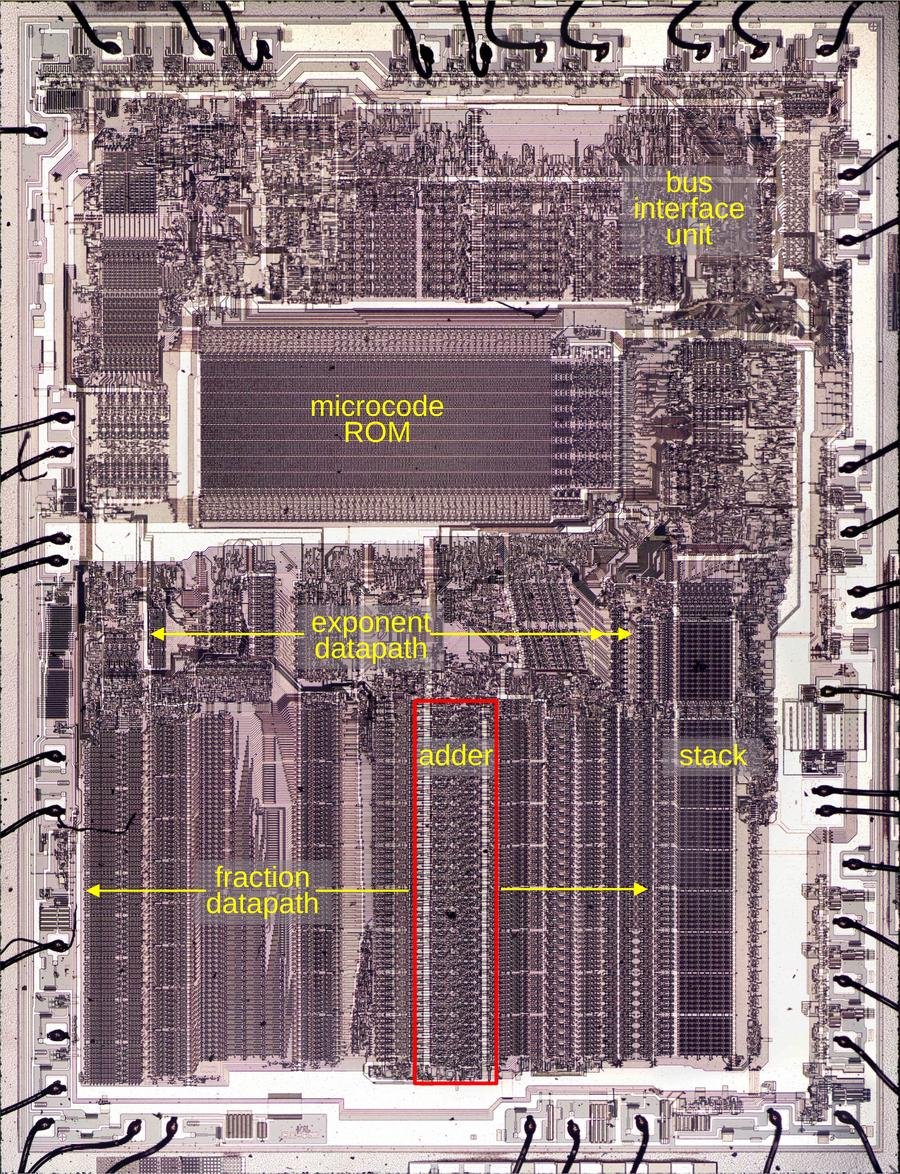
The 8087 arrived in 1980 as a companion chip for Intel's 16-bit PC-era processors. Intel's later x87 lineage is documented in the modern Intel Software Developer Manuals, but the 8087 is the awkward, fascinating first generation: separate package, separate execution engine, bus watching, DMA for long operands, and a stack-based floating-point model that shaped x86 numerical software for decades.
The headline number often attached to the 8087 is up to 100 times faster math compared with software routines. That depends heavily on the workload. Addition, subtraction, multiply, divide, square root, logarithms, exponentials, and trigonometric functions do not stress the same internal path equally. Still, the big picture is clear. On an 8088 or 8086 system, floating-point without a coprocessor meant integer instructions grinding through multiword arithmetic in software. With the 8087 installed, the numeric work moved onto silicon built specifically for wide fractions, exponent handling, rounding, normalization, and iterative math kernels.
The adder is the part that makes that claim concrete. Floating-point multiplication, division, square root, and transcendental functions all need repeated additions or subtractions somewhere inside the implementation. The 8087 did not have the transistor budget for a giant modern floating-point execution core, so Intel spent carefully. The result was not a simple ripple-carry adder and not a huge parallel-prefix monster. It was a practical middle path: a Manchester carry chain broken into 4-bit blocks, assisted by carry-skip logic, wrapped in NMOS precharge behavior.
For a homelab builder, this is the old silicon equivalent of looking past a CPU's model name and checking perf counters, package power, memory timings, and firmware quirks. The interesting result is not just that the 8087 was faster. The interesting result is how much of that speed came from managing one ugly fact: carries are expensive.
Performance Data
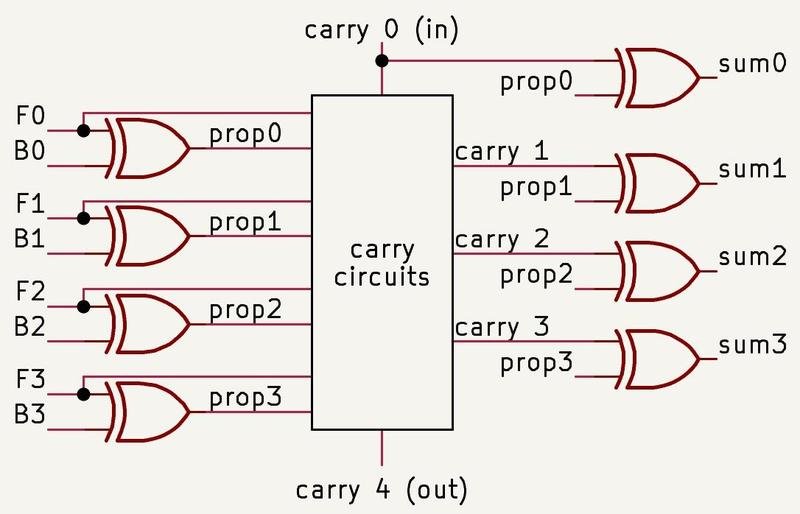
A binary adder has a simple job. Add two bit vectors and produce a sum. The performance problem is the carry path. Bit 17 may depend on bit 16, which may depend on bit 15, and so on back to the least significant bit. A naive 68-bit ripple-carry adder waits for the carry signal to march through the full width. That is easy to lay out, but poor for latency.
The 8087 splits the work into 4-bit blocks. Inside a block, the carry path uses a Manchester carry chain. Across blocks, a carry still has to move, but the number of higher-level carry steps is reduced by roughly a factor of four.
| Design choice | What it does | Performance effect | Hardware cost |
|---|---|---|---|
| Ripple carry across every bit | Carry moves bit by bit through logic | Small area, high delay | Low |
| Manchester carry chain | Carry passes through transistor switches | Faster local carry propagation | Moderate |
| 4-bit blocking | Refreshes and manages carry after short runs | Reduces voltage loss and delay | Moderate |
| Carry-skip detection | Bypasses a block when every bit propagates carry | Saves time on favorable data patterns | Extra gate logic |
| Full parallel-prefix adder | Computes carries with a tree | Much faster for wide adders | Too expensive for this chip class |
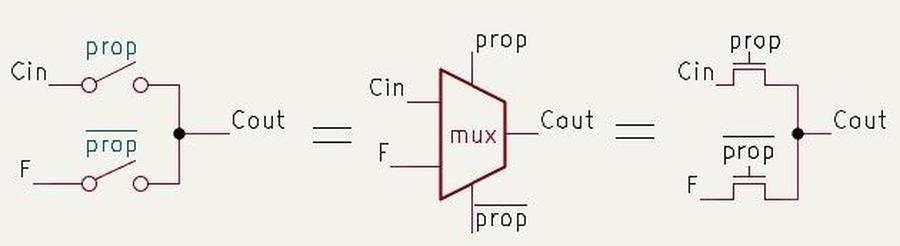
The Manchester scheme uses three concepts: generate, propagate, and delete. If a bit position adds 1 plus 1, it generates a carry no matter what came in. If it adds 0 plus 0, it deletes any incoming carry. If it adds 0 plus 1, it propagates the incoming carry to the next bit. Those states can be prepared in parallel for many bit positions, then the carry signal moves through pass-transistor paths instead of crawling through a stack of full logic gates.
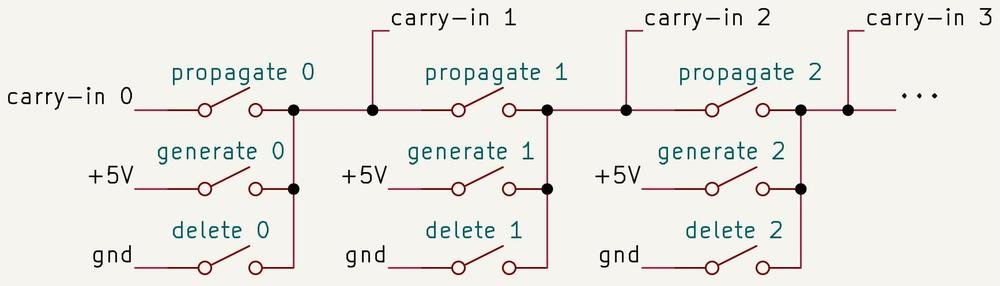
This is the kind of optimization that looks small until you put numbers next to it. The 8087's fraction datapath nominally exists to support 64-bit significands, but the adder is wider because real floating-point hardware needs guard, round, and sticky bits for correct rounding. It also needs room for shifted values, negation, two's-complement subtraction, and possible carry-out growth. The supplied reverse-engineering notes describe 69 input bits and 70 output bits around a nominal 64-bit fraction workload.
| Item | Value or role |
|---|---|
| Nominal fraction precision | 64 bits |
| Extra rounding support | Guard, round, sticky bits |
| Adder input width | 69 bits |
| Adder output width | 70 bits |
| Carry block size | 4 bits |
| Addition latency inside 8087 | Two clock cycles for the large adder operation |
| Process style | NMOS, precharged carry lines |
| External package | 40-pin DIP |
Those extra bits matter. Without guard, round, and sticky handling, a floating-point unit can be fast and still numerically sloppy. The 8087's job was not only to beat software math. It also helped establish the extended-precision habits that fed into the IEEE 754 era. The historical Intel 8087 overview is useful for the family context, but the die-level story explains why the chip needed so much local arithmetic machinery.
Power and thermals also deserve a real measurement column. The 8087 is commonly cited around 2.4 W, which sounds tiny next to a modern desktop CPU but is not tiny for a ceramic 40-pin coprocessor sitting in an early PC motherboard. A period-correct 8088 box already has limited airflow, linear power supplies in some builds, and boards that were not designed with modern thermal telemetry. Adding an 8087 is more like adding a small hot accelerator than plugging in a passive feature chip.
| Build variable | Practical impact |
|---|---|
| 8087 speed grade | Must match the host clock expectations, common parts include 5 MHz, 8 MHz, and 10 MHz classes |
| Host CPU | Intended for 8086 and 8088 class systems, with related early x86 compatibility details |
| Socket availability | Many IBM PC and compatible boards expose a coprocessor socket, but not all clones are equal |
| Cooling | A few watts can matter in cramped vintage enclosures |
| Workload | CAD, spreadsheets, scientific code, and compiled numerical programs benefit most |
| Software support | Programs must issue x87 instructions or use libraries that detect the coprocessor |
The transistor-level implementation has a performance detail modern builders will recognize: electrical behavior changes architecture. NMOS transistors pull low better than they pull high. The 8087 uses precharged carry lines so signals start in a known high state, then discharge when the logic requires it. That is not an abstract computer architecture choice. That is device physics showing up in the timing budget.
The 4-bit block size is also a measured compromise. Pass transistors lose voltage as signals move through multiple stages. A long Manchester chain without refresh would be fast in concept but electrically weak in practice. Breaking the adder into blocks keeps the carry path short enough to be usable while carry-skip logic avoids unnecessary work when all four positions propagate the incoming carry.
That makes the 8087 feel surprisingly modern in spirit. Server builders see the same kind of trade-off in CPU cache hierarchy, PCIe retimers, DDR signal integrity, and AVX frequency behavior. The spec sheet names the feature. The real performance comes from the path the electrons can actually survive.
How The Adder Feeds The FPU
The adder accepts one input from the fraction bus and another from the B register. The result lands in the Sum Register, with shifters nearby to normalize, align, and feed iterative operations. Multiplication uses radix-4 Booth-style behavior, selecting values such as 2B, B, 0, or negative B. Division and square root use repeated add, subtract, and shift sequences. Transcendental functions need still more microcoded and iterative support, but the arithmetic center remains the same.
This is why a two-cycle wide addition can still dominate the chip's character. The 8087 is not doing one giant operation per instruction and calling it done. It is sequencing smaller operations through a datapath. Improve the adder and a lot of the FPU gets faster. Make the adder too large and the die area, routing, and yield get worse.
That trade-off is visible in the die. A single metal layer forces dense routing. The fraction bus has to cross the adder region. Control signals such as precharge and force-zero need to arrive at the right places. The adder is not a neat textbook rectangle. It is a piece of silicon packed around the limits of 1980 manufacturing.
A useful comparison is the later Pentium-class use of more aggressive carry structures such as Kogge-Stone adders. A Kogge-Stone design can reduce carry delay dramatically by computing prefix relationships in parallel, but it burns routing and logic. On a chip with a larger transistor budget and more advanced interconnect, that can be a good deal. On the 8087, it would have been the silicon equivalent of filling a home server with hot accelerator cards before checking whether the power supply, airflow, and workload justify them.
Compatibility Notes
The 8087 is a coprocessor, not a drop-in speed setting. It observes instruction streams intended for the main CPU, recognizes escape opcodes, and coordinates through the 8086 or 8088 bus model. That creates several practical compatibility checks.
| Compatibility item | What to verify |
|---|---|
| Motherboard socket | Physical 40-pin coprocessor socket present and wired correctly |
| Clock pairing | 8087 speed grade appropriate for the system clock |
| BIOS and software | Numeric software or runtime libraries can detect and use x87 |
| WAIT or FWAIT behavior | Code must avoid issuing new coprocessor work before prior work completes |
| Package and thermals | Ceramic parts can run warm, especially in closed vintage cases |
| Clone behavior | Some compatible systems vary in timing, documentation, or socket quality |
For retro benchmarking, I would treat an 8087 upgrade the way I treat a used HBA or 10 GbE NIC in a homelab chassis. First verify electrical and firmware compatibility. Then run a workload that actually hits the accelerator. A word processor will not become dramatic. A spreadsheet recalculating floating-point formulas, a CAD package, a Mandelbrot renderer, or a numeric benchmark will show the point much better.
Good tests should separate integer host performance from coprocessor throughput. Run the same binary with and without the 8087 when possible. Track elapsed time, system power at the wall, package temperature by external probe if available, and result correctness. For old systems, correctness matters because software fallback paths, emulator modes, and compiler options may change precision and rounding behavior.
| Test | What it reveals |
|---|---|
| Software floating-point benchmark without 8087 | Baseline host CPU cost |
| Same benchmark with 8087 enabled | Coprocessor uplift |
| Long spreadsheet recalculation | Real application benefit |
| Repeated transcendental functions | Microcode and iterative datapath behavior |
| Wall power under load | Added platform power |
| Thermal soak over 30 minutes | Whether the case can handle sustained numeric work |
A clean measurement session would report both speedup and watts. A result like 8x faster at plus 2 W is very different from 80x faster at plus 2 W, and both are plausible depending on workload. That is the same discipline modern server tuning needs. Performance per watt is not a modern invention. We just have better sensors now.
Build Recommendations
For a period-correct IBM PC, XT, or compatible build, an 8087 is worth installing when the software stack can use it. The best candidates are CAD, engineering tools, scientific programs, statistical packages, and spreadsheets with heavy numeric recalculation. If the machine is mostly for games, text editing, terminal use, or DOS utilities, the coprocessor is historically interesting but often idle.
Buy by speed grade and board compatibility first, collector appeal second. A 10 MHz part is not useful if the board expects a lower grade or has timing assumptions around a slower host. Check the motherboard manual, oscillator arrangement, and any jumper settings. If documentation is thin, inspect the board and compare with known-good builds before powering unknown silicon.
Thermally, do not treat the 8087 as decorative. A few watts in a small vintage case can raise local temperature, especially near other warm chips. If the system has no fan, measure after a sustained run. A stick-on heatsink is not period-pure, but a quiet fan moving air across the board can preserve parts without changing the machine's behavior.
For benchmarking, build a small table for every run: CPU, coprocessor, clock, RAM wait states if known, DOS version, benchmark version, runtime, and wall power. Old machines vary enough that a number without configuration data is mostly trivia. The homelab rule applies: if I cannot reproduce the run, I do not trust the chart.
For learning, the 8087 is excellent because it exposes the whole stack. You can connect transistor behavior to carry logic, carry logic to floating-point operations, floating-point operations to application speed, and application speed to power draw. That chain is exactly what modern performance work still requires, even when the adder is buried under out-of-order execution, SIMD units, and firmware power management.
The 8087's adder is not just a historical curiosity. It is a compact case study in balanced hardware design. Intel needed more than a simple ripple-carry adder, but it could not afford a huge prefix network. The Manchester carry chain, 4-bit blocks, carry-skip logic, and NMOS precharge choices show a team spending transistors where they moved real workloads. That is the part worth carrying into modern builds: measure the bottleneck, understand the electrical limits, and spend complexity only where the numbers pay back.
Comments
Please log in or register to join the discussion