
JuiceFS delivers POSIX-compatible file operations atop object storage with Redis metadata management, targeting AI/ML workloads needing high-throughput access.

JuiceFS presents itself as a cloud-native distributed file system combining POSIX compatibility with object storage backend efficiency. Unlike traditional distributed file systems, it separates metadata management from data storage - using databases like Redis for metadata while leveraging object stores (S3, GCS, etc.) for bulk data. This architecture targets machine learning pipelines and big data workloads needing POSIX semantics without local storage limitations.
Architectural Breakdown
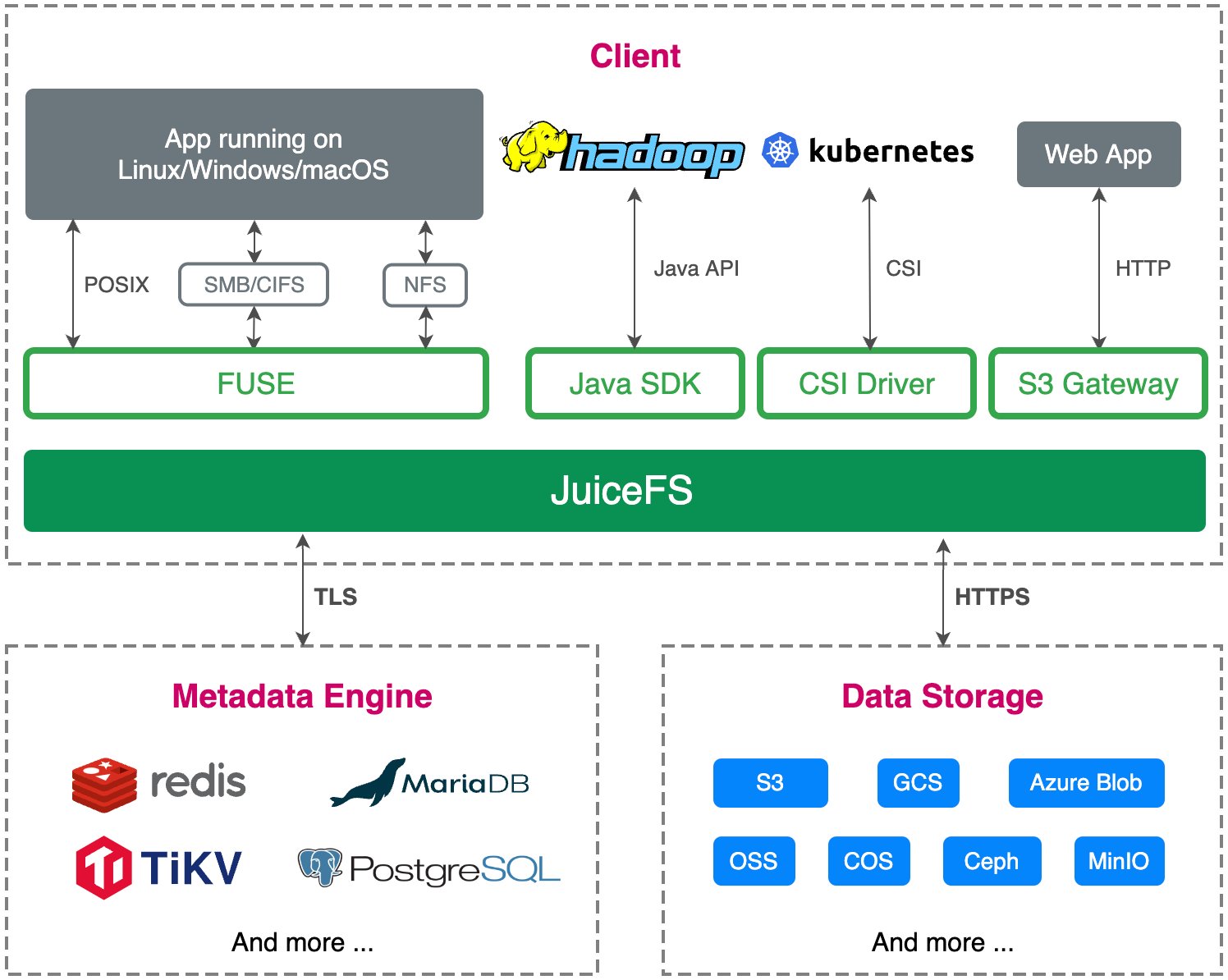
The system comprises three layers:
- Client: Handles POSIX/Hadoop/S3/Kubernetes interfaces
- Metadata Engine: Uses Redis/MySQL/TiKV for file attributes and structure
- Object Storage: Stores chunked data blocks (default 4MB)
Files undergo multi-stage decomposition:
- Split into 64MB chunks
- Divided into variably-sized slices
- Stored as fixed-size 4MB blocks in object storage
This structure enables features like:
- Close-to-open consistency guarantees
- Atomic metadata operations
- BSD (
flock) and POSIX (fcntl) record locks - Transparent compression (LZ4/Zstandard)
Performance Characteristics
Benchmarks against EFS and S3FS reveal significant advantages:
Throughput (via fio):
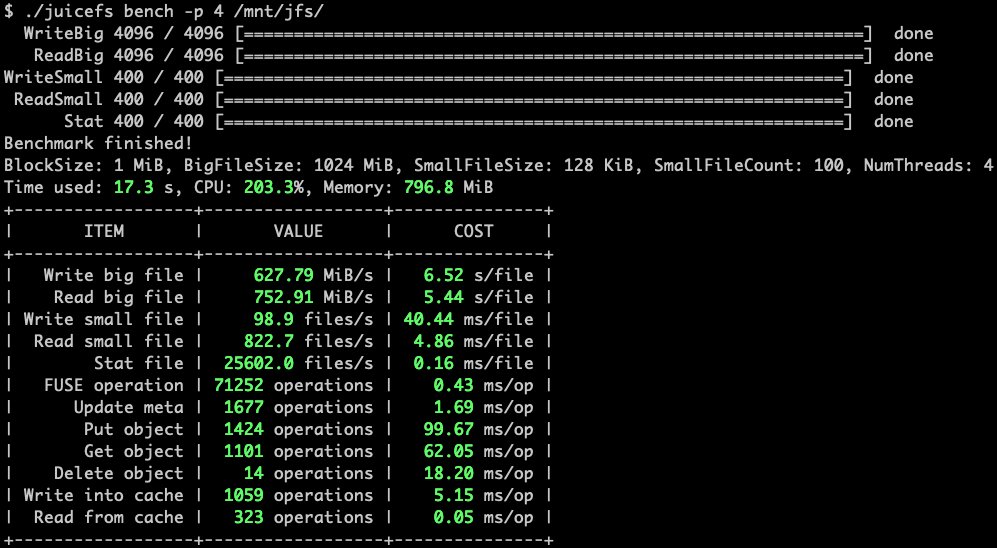 JuiceFS sustains ~10x higher throughput than alternatives in sequential operations, crucial for large dataset processing.
JuiceFS sustains ~10x higher throughput than alternatives in sequential operations, crucial for large dataset processing.
Metadata Operations (via mdtest):
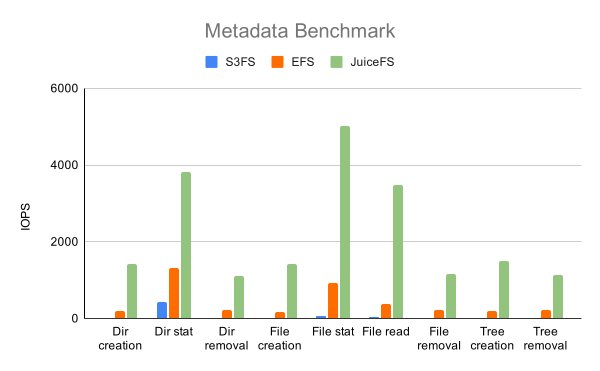 Metadata-intensive workloads show order-of-magnitude improvements in IOPS, benefiting scenarios with numerous small files.
Metadata-intensive workloads show order-of-magnitude improvements in IOPS, benefiting scenarios with numerous small files.
The architecture achieves sub-millisecond latency for metadata operations when using Redis, though performance scales with the metadata engine choice.
Practical Constraints
While supporting multiple metadata engines, Redis Cluster usage requires careful configuration: All transaction keys must reside in the same hash slot, limiting horizontal scaling of metadata operations. Users report successful deployments at thousand-client scale, though coordination overhead increases with client count.
Object storage compatibility extends beyond major clouds to MinIO, Ceph, and even local disks. However, direct object storage access reveals JuiceFS' block structure rather than original files - a tradeoff for performance optimization.
Production Considerations
JuiceFS fits scenarios requiring:
- POSIX compliance in Kubernetes (via CSI driver)
- Hadoop ecosystem integration
- Cloud storage cost efficiency
- Cross-cloud portability
Notable adopters include Bilibili for video processing pipelines. The Apache 2.0 licensed project provides:
- Usage telemetry (opt-out with
--no-usage-report) - Real-time performance monitoring
- Resumable sync operations
Comparative Position
JuiceFS occupies a unique niche between traditional distributed file systems (like HDFS) and object storage gateways. Unlike s3fs-fuse, it provides stronger consistency and POSIX semantics. Versus cloud-native solutions like EFS, it offers multi-cloud flexibility and reduced costs through separable metadata/data scaling.
The roadmap targets large-scale optimizations including enhanced read-ahead algorithms and snapshot functionality. Current limitations involve Windows support gaps and metadata engine selection tradeoffs - Redis delivers speed while SQL-based engines offer richer query capabilities.
Resources:
- GitHub Repository
- Architecture Documentation
- Performance Benchmarks
- Supported Storage Backends
- Comparison Matrix
For teams managing petabyte-scale AI training sets across cloud providers, JuiceFS warrants evaluation despite its young ecosystem. The decoupled architecture provides scaling flexibility, though metadata engine selection remains critical for workload-specific optimization.
Comments
Please log in or register to join the discussion