Uber's engineering team has transformed its data replication platform to handle over one petabyte of daily replication across hybrid cloud and on-premise data lakes, using optimized Hadoop Distcp framework with significant performance improvements.
Uber's engineering team has transformed its data replication platform to move petabytes of data daily across hybrid cloud and on-premise data lakes, addressing scaling challenges caused by rapidly growing workloads. Built on Hadoop's open-source Distcp framework, the platform now handles over one petabyte of daily replication and hundreds of thousands of jobs with improved speed, reliability, and observability, enabling analytics, machine learning, and disaster recovery at unprecedented scale.
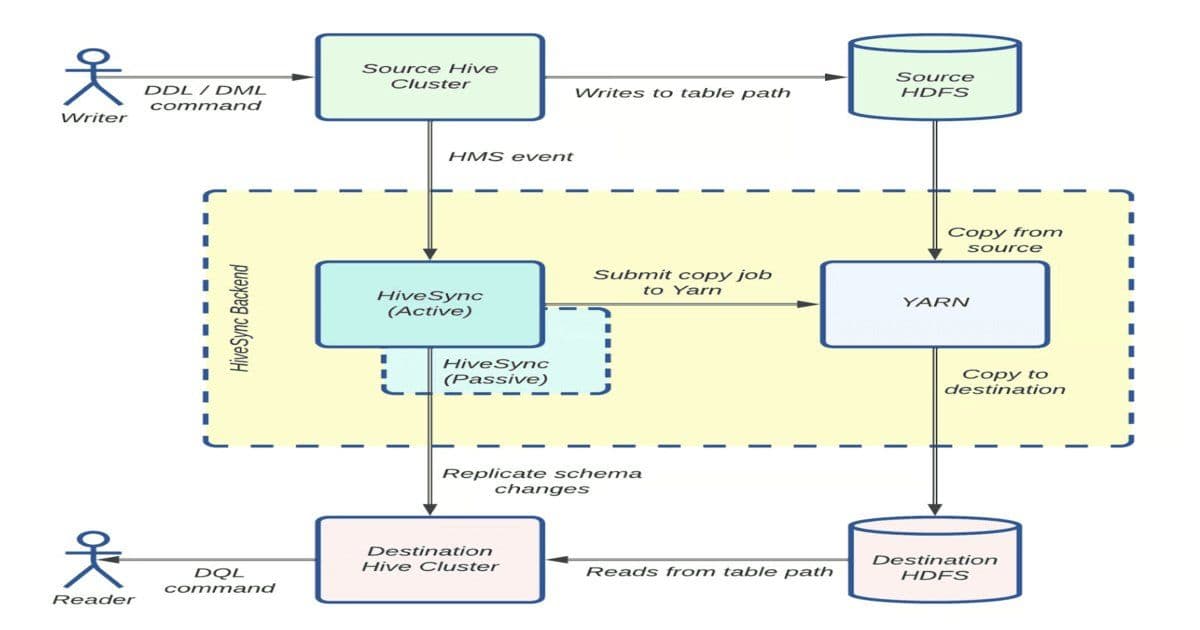
Distcp is an open-source framework that copies large datasets in parallel across multiple nodes using Hadoop's MapReduce. Files are split into blocks and assigned to Copy Mapper tasks running in YARN containers. The Resource Manager allocates resources, the Application Master monitors job execution and coordinates merges, and the Copy Committer assembles final files at the destination. Uber's HiveSync team optimized this architecture for multi-petabyte workloads by moving preparation tasks to the Application Master, parallelizing listing and commit processes, and improving efficiency for small transfers.
HiveSync, originally based on Airbnb's ReAir project, keeps Uber's HDFS and cloud data lakes synchronized using bulk and incremental replication. For datasets larger than 256 MB, it submits Distcp jobs through asynchronous workers in parallel, with a monitoring thread tracking progress. As daily replication grew from 250 TB to over 1 PB and datasets expanded from 30,000 to 144,000, HiveSync faced backlogs that threatened SLAs, emphasizing the need for operational and architectural enhancements to support cloud migration and Uber's active-passive data lake model.
To address scaling challenges, the HiveSync team enhanced Distcp by moving resource-intensive tasks like Copy Listing and Input Splitting from the HiveSync server to the Application Master, reducing HDFS client contention and cutting job submission latency by up to 90 percent. Copy Listing and Copy Committer tasks were parallelized, allowing multiple files to be processed simultaneously while maintaining block order, lowering p99 listing latency by 60 percent and maximum commit latency by over 97 percent. For smaller jobs transferring fewer than 200 files or 512 MB, Hadoop's Uber job feature ran Copy Mapper tasks directly in the Application Master's JVM, eliminating roughly 268,000 container launches daily and improving YARN efficiency.
These optimizations increased incremental replication capacity fivefold, enabling HiveSync to replicate over 300 PB during Uber's on-premise-to-cloud migration without incidents. Enhanced observability, including job submission, Copy Listing, and Committer metrics, heap usage, and p99 copy rates, helped engineers monitor workloads and preempt failures. Out-of-memory errors, high job submissions, and long-running Copy Listing tasks were mitigated via stress testing, circuit breakers, optimized YARN configurations, and reordered task execution.
Looking ahead, the HiveSync team is focusing on further parallelization, optimized resource management, and network efficiency. Planned enhancements include parallelizing file permission setting and input splitting, moving compute-intensive commit tasks to the Reduce phase, and implementing a dynamic bandwidth throttler. Uber plans to contribute these improvements as an open-source patch, extending the broader community's ability to manage extreme-scale hybrid cloud replication.
"Even small improvements can lead to significant gains at our scale," the engineering team noted. These efforts highlight the operational and engineering creativity required to sustain high-throughput, reliable performance across complex, multi-region data pipelines.
The HiveSync team's work demonstrates how thoughtful architectural optimizations can transform data infrastructure to meet exponential growth demands. By addressing bottlenecks at multiple levels—from job submission to commit processing—they've created a platform capable of supporting Uber's massive data operations while maintaining the reliability required for production workloads.
This case study offers valuable insights for organizations facing similar scaling challenges in hybrid cloud environments, showing how existing open-source frameworks can be enhanced through targeted optimizations rather than wholesale replacement.
Comments
Please log in or register to join the discussion