A detailed analysis of handling backpressure in message queues during traffic spikes, examining why producer-side rate limiting is the most effective solution.
Understanding Backpressure in Distributed Systems: The SQS Black Friday Problem
In the world of distributed systems, few problems are as common yet as misunderstood as backpressure. The scenario described is one that many engineers have faced: a system that works perfectly under normal conditions suddenly buckles under unexpected load. Let's examine this problem in depth and explore the most effective solutions.
The Problem Scenario
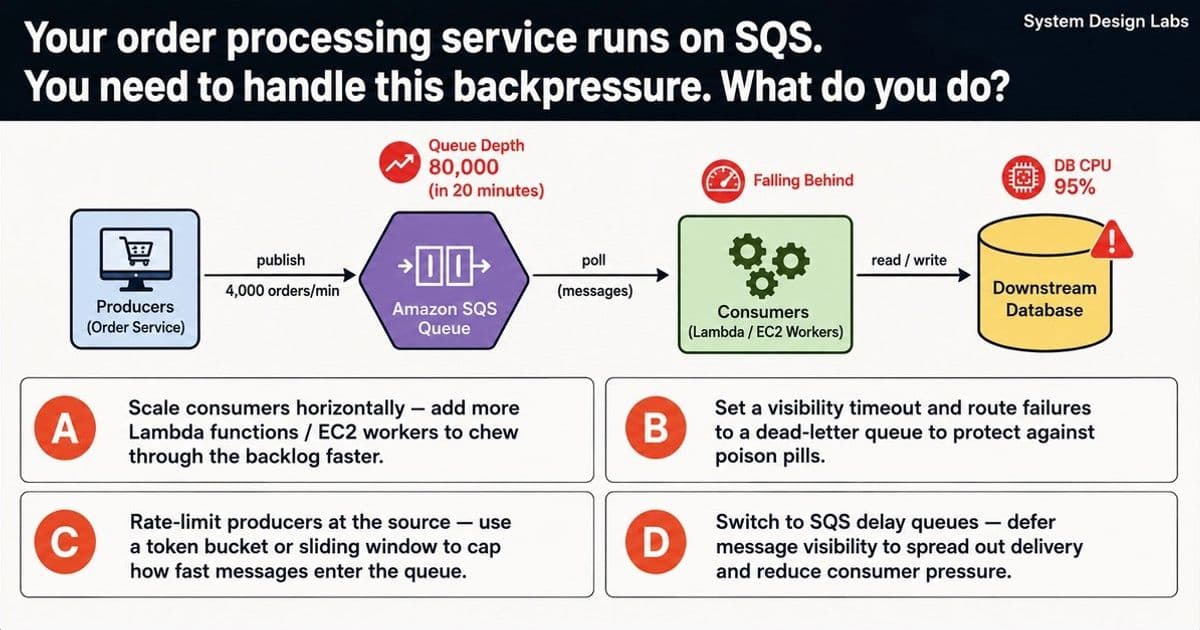
We have an order processing system with the following characteristics:
- Normal load: 200 orders per minute
- Consumers can handle this load without issues
- Black Friday hits: producers suddenly push 4,000 orders per minute
- Queue depth climbs to 80,000 messages in just 20 minutes
- Downstream database reaches 95% CPU utilization
- Consumers are falling further behind
This creates a classic backpressure situation where the upstream system is generating work faster than the downstream system can process it. The queue depth is the visible symptom of this imbalance.
Understanding Backpressure
Backpressure is a fundamental concept in distributed systems where a downstream component signals an upstream component to slow down its rate of work. This prevents system overload and maintains stability. In our scenario, the SQS queue depth is acting as the backpressure signal – it's growing because the system is overwhelmed.
Many engineers instinctively respond to backpressure by scaling consumers, but this approach often fails to address the root cause. Let's examine why.
Option A: Scale Consumers Horizontally
The instinctive reaction to a growing queue is to add more processing capacity. This approach suggests adding more Lambda functions or EC2 workers to chew through the backlog faster.
Why This Approach Fails
While scaling consumers might seem logical, it treats a rate mismatch as a capacity problem. When your producer can generate messages faster than your consumers can process them (as in our Black Friday scenario), you're in an arms race you can't win.
Consider what happens when you scale consumers:
- You might temporarily increase processing capacity
- But your producer can still generate 4,000 orders/minute
- You'll hit other bottlenecks: database write limits, connection pool exhaustion, API rate limits
- The queue continues to grow, just more slowly
- Your infrastructure costs increase significantly
When Consumer Scaling Actually Works
Consumer scaling is effective when:
- The bottleneck is compute capacity
- Processing requirements remain constant
- You have predictable, bounded input rates
- You're willing to pay for the additional capacity
In our scenario with unbounded producer rates, consumer scaling is a temporary band-aid that doesn't solve the fundamental problem.
Option B: Visibility Timeout and Dead-Letter Queues
This approach suggests setting a visibility timeout and routing failures to a dead-letter queue (DLQ) to protect against poison pills.
What These Mechanisms Actually Do
- Visibility timeout: Controls how long a message remains invisible after a consumer picks it up. This prevents double-processing while a consumer is working on a message.
- Dead-letter queue: Catches messages that repeatedly fail processing, preventing infinite retry loops.
Why This Approach Fails for Backpressure
These mechanisms address failure handling and retry logic, not backpressure. They don't:
- Slow down the producer
- Reduce the rate of messages entering the queue
- Alleviate the load on the downstream database
In fact, during high load, you might see more failures as consumers struggle to process messages, potentially increasing the number of messages sent to the DLQ without solving the underlying backpressure issue.
Option D: SQS Delay Queues
This approach suggests switching to SQS delay queues to defer message visibility and spread out delivery.
What Delay Queues Actually Do
SQS delay queues defer when messages become visible to consumers. When you send a message to a delay queue, it remains invisible for a specified period before becoming available for processing.
Why This Approach Fails for Backpressure
Delay queues don't reduce the rate of messages entering the system. They only change when those messages become visible. This means:
- Messages still pile up in the queue invisibly
- When the delay expires, messages become visible in batches
- You haven't reduced backpressure – you've deferred it
- The delivery pattern becomes spikier, potentially creating new problems
Delay queues are useful for scenarios where you need to delay processing for business reasons (e.g., waiting for additional data), but they don't solve backpressure caused by producer-consumer rate mismatches.
Option C: Producer-Side Rate Limiting
This approach suggests rate-limiting producers at the source using mechanisms like token bucket or sliding window algorithms to cap how fast messages enter the queue.
Why This Approach Works
Producer-side rate limiting directly addresses the root cause of the backpressure: the rate mismatch between producer and consumer. By limiting the producer to a rate that the downstream system can handle, you:
- Prevent the queue from growing uncontrollably
- Allow consumers to process messages at a sustainable pace
- Protect the downstream database from overload
- Maintain system stability without unnecessary cost increases
Implementation Strategies in AWS
There are several ways to implement producer-side rate limiting in AWS:
API Gateway Usage Plans
API Gateway usage plans allow you to set throttling limits on your API endpoints. You can configure:
- Request rate limits (requests per second)
- Burst capacity limits
- Per-method throttling
Lambda Reserved Concurrency
Lambda reserved concurrency ensures that your Lambda functions have enough capacity to scale without being throttled. While this doesn't directly limit producers, it ensures your consumers can scale appropriately.
Application-Level Throttle Middleware
Implementing rate limiting within your application code using algorithms like:
- Token bucket: Add tokens to a bucket at a fixed rate. Each request consumes a token. If no tokens are available, the request is throttled.
- Sliding window: Track requests over a time window and limit new requests when the threshold is reached.
Many programming languages have libraries for implementing these algorithms, such as:
The Mental Model: Slow the Tap, Don't Just Widen the Drain
The key insight here is that backpressure is a signal from the downstream system that it's overwhelmed. The appropriate response is not to make the drain bigger (scale consumers), but to slow the tap (limit producers).
In our scenario, the queue depth is the backpressure signal. Reacting to this signal by limiting the producer rate creates a feedback loop that stabilizes the system.
Additional Considerations
Monitoring and Alerting
Implement comprehensive monitoring to detect backpressure early:
- Track queue depth over time
- Monitor consumer lag (time between message arrival and processing)
- Set alerts for abnormal queue growth patterns
Graceful Degradation
Consider implementing graceful degradation strategies when backpressure occurs:
- Prioritize critical orders
- Implement queuing for non-essential operations
- Provide clear feedback to users about system status
Circuit Breakers
Implement circuit breakers to protect downstream systems during extreme load spikes. The AWS Circuit Breaker pattern can automatically route traffic away from overwhelmed services.
Conclusion
The Black Friday scenario illustrates a fundamental challenge in distributed systems: handling backpressure caused by rate mismatches between components. While consumer scaling, visibility timeouts, and delay queues all have their place in system design, they don't address the core issue in this scenario.
Producer-side rate limiting (Option C) is the most effective solution because it directly addresses the root cause by matching the producer rate to the consumer capacity. This approach stabilizes the system, protects downstream resources, and prevents unnecessary infrastructure costs.
In distributed systems design, understanding when to limit upstream components versus scaling downstream components is crucial for building resilient, cost-effective systems. The next time you see a queue growing uncontrollably, remember: the solution often lies in slowing the tap, not just widening the drain.
#SystemDesign #AWS #DistributedSystems #Backpressure #SQS #SoftwareArchitecture
Comments
Please log in or register to join the discussion