
Philip Zucker’s accepted EGRAPHS 2026 talk reframes variable context as data inside the term itself, turning a familiar nuisance of names, scope, and sharing into a structural operation on functions.

Thesis
Philip Zucker’s accepted EGRAPHS 2026 talk, titled Lifting E-Graphs: A Function Isn’t a Constant, is about a deceptively small shift in how equality saturation systems might represent expressions with variables. The shift is this: context should not be treated as the external place where a term happens to sit, but as part of what the term is.
That sentence sounds philosophical, and in a sense it is, but the payoff is concrete. E-graphs, the data structure behind equality saturation systems such as egg, are designed to compactly represent many equivalent expressions at once. They do this by aggressively sharing structure and merging equivalent terms into equivalence classes. Yet variable names and variable contexts create a subtle tension. If the system treats names too literally, it misses sharing. If it treats them too casually, it may share too much, collapsing expressions that are only superficially similar.
Zucker’s proposal, previously explored under the name Thinning E-Graphs and now reframed as lifting e-graphs, uses a semantic model of functions of the form R^n -> R to make that tension explicit. A term such as sin(x) is not one thing in isolation. It might mean the function x |-> sin(x), which has type R -> R. It might also mean x,y |-> sin(x), which has type R^2 -> R and ignores its second input. These are related, but they are not identical. Lifting is the operation that explains the relationship.
Key Arguments
The first problem is that explicit names make generative rewriting awkward. Equality saturation systems routinely apply rewrite rules again and again, exploring a large space of equivalent programs or formulas. Some valid rewrites require fresh names, such as introducing a fresh bound variable in a quantified proposition. A system can use generated symbols, Skolem-style bookkeeping, or free-variable analysis to keep this hygienic, but each technique adds machinery that is easy to get almost right and hard to make elegant.
The second problem is missed sharing. In a conventional representation, f(g(h(x))) and f(g(h(y))) may be structurally distinct because the variable names differ, even though they have the same shape. A nameless representation can recover this sharing by replacing names with positions. What used to be x |-> f(g(h(x))) and y |-> f(g(h(y))) can both become a term over the zeroth variable in a one-variable context.
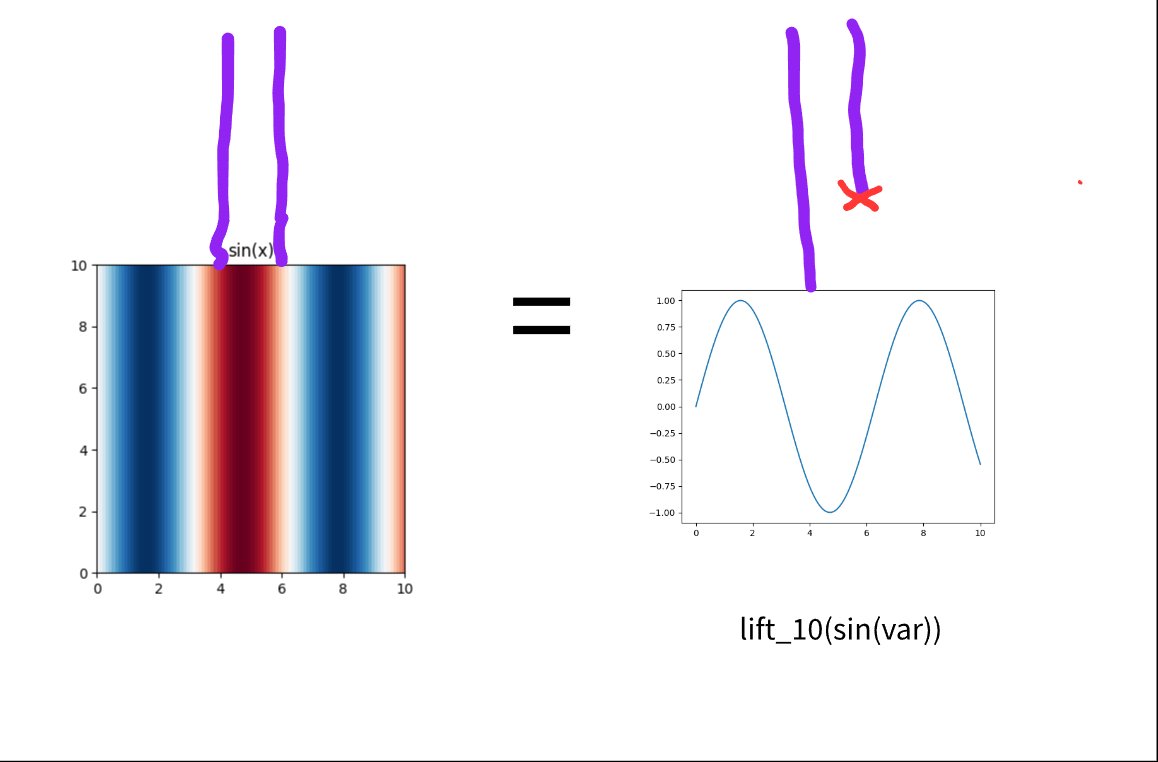
The third problem is more surprising: careless names can create too much sharing. The notation sin(x) suppresses the surrounding context, but the surrounding context changes the object. The function R -> R that maps x to sin(x) is not the same typed object as the function R^2 -> R that maps x,y to sin(x). They have different domains, different graphs, and different roles inside a typed system. The ordinary mathematical notation works because humans supply context fluidly, but an e-graph needs a representation that decides what is identical, what is related, and what is merely printed the same way.
A naive nameless solution is to index variables and function symbols by context size. The zeroth variable in a one-variable context, the first variable in a two-variable context, and the sine operator acting pointwise over R^2 -> R all become distinct typed entities. This fixes the over-sharing problem, but it creates a new sharing problem. The terms f1(g1(h1(x10))) and f2(g2(h2(x20))) are now completely separate, even though the second is just the first lifted into a larger context by ignoring an extra argument.
Lifting names that relationship directly. Given a function f : R -> R, we can form a function R^2 -> R by mapping x,y to f(x). In code, this looks like lambda f: lambda x, y: f(x). Zucker represents such operations as bitvectors, where a 1 means keep this variable and a 0 means discard it. A lift_10 operation keeps the first argument and drops the second. A lift_01 operation keeps the second argument and drops the first.
This is where the proposal becomes an e-graph design rather than only a semantic observation. Instead of storing every lifted copy of a term as a separate full term, the e-graph can store the smaller term once and attach a compact lifting annotation to the identifier that refers to it. The expression x,y |-> f(g(h(x))) can be represented as a lift of x |-> f(g(h(x))). The system preserves the distinction between different typed functions while sharing the structure that they genuinely have in common.
The algebra of liftings is simple enough to be baked into the data structure. Liftings compose. Pointwise operators commute with lifting. For example, sin(lift_i(X)) can become lift_i(sin(X)), and f(lift_i(X), lift_i(Y)) can become lift_i(f(X,Y)). These are not domain-specific optimizations. They are structural facts about how functions over larger contexts can ignore variables.
Zucker’s smart constructor idea uses this algebra during interning. When constructing an e-node whose arguments all carry a common lifting, the constructor peels that common lifting off, interns the smaller node, and then returns a lifted identifier. This gives the e-graph an alpha-aware hash-consing flavor, related to ideas in Hash Cons Modulo Alpha and to Conor McBride’s co-De Bruijn perspective in Everybody’s Got To Be Somewhere. The point is not merely to compress terms, but to make the compression respect scope and context by construction.
Union-find, the engine that merges e-classes, also has to understand lifting. If lift_i(a) equals lift_i(b), and the lift is injective, the system can peel off the common lift and conclude a equals b. This resembles the familiar reasoning that cons(a,c) = cons(b,c) implies a = b. But e-graphs also need to handle equations such as x * 0 = 0, where the two sides live in a context containing x even though the result no longer depends on x.
In Zucker’s account, the constant 0 is not bare. It begins as a zero-arity function, then gets lifted into the current context. The equation x |-> x * 0 = 0 becomes something like x10 * lift_0(0) = lift_0(0). The union-find cannot always solve these equations symmetrically. Sometimes one side can be expressed as a lift of the other, but not conversely. This leads to an asymmetric annotated union-find, where parent pointers carry lifting information, much as weighted union-find structures can carry integer offsets. Zucker has explored this line in thin monus union find and asymmetric complete.
The hardest part appears to be e-matching, the procedure that finds instances of rewrite patterns inside an e-graph. Once liftings are implicit in identifiers and union-find edges, a pattern matcher must decide whether it is matching only canonical unlifted terms, matching explicitly lifted terms, or solving for arbitrary lift insertions. The last case begins to resemble unification rather than ordinary matching.
Zucker’s pragmatic proposal is to keep the default matcher conservative: when traversal reaches a redundancy edge, do not cross it. This sacrifices some completeness, but it avoids an explosion of matches that are technically valid yet often unhelpful. For example, matching a lifted zero against ?x * ?y may enumerate many ways to insert variables that are later annihilated by multiplication by zero. Such matches are semantically defensible, but they may be computational noise.
The design also sits near several neighboring theories. It touches thinnings and weakenings from type theory, co-De Bruijn representations of binding, nominal approaches to variables, presheaf-flavored accounts of contexts, and Rudi’s work with Zucker on slotted union-find. It also has a visual affinity with congruence closure diagrams, including abstract congruence closure by Bachmair and Tiwari. In Zucker’s preferred picture, e-classes are not dotted containers around nodes, but parent arrows in a union-find graph, with thinning annotations shown as buses whose lines can end when variables are discarded.
Implications
The immediate implication is that equality saturation may need richer identifiers. A classic e-graph identifier points to an equivalence class. A lifting e-graph identifier points to an equivalence class plus a compact account of how that class has been placed into a larger context. This is a small representational change with wide consequences: construction, unioning, rebuilding, pattern matching, and visualization all need to understand the annotation.
The payoff is a more disciplined relationship between sharing and typing. Traditional sharing asks whether two terms are syntactically the same or have been proven equivalent. Lifting asks a subtler question: are these terms different objects that arise from the same smaller object by adding ignored context? That question matters for symbolic algebra, program optimization, theorem proving, and any setting where expressions under binders or variable scopes need to be rewritten without accidental capture or spurious duplication.
There is also a deeper lesson about mathematical notation and machine representation. Human notation often thrives by suppressing context. We write sin(x), trust the reader to infer the domain, and move on. Machines cannot rely on that tacit social contract. They need a representation that either makes the context explicit or chooses a global environment semantics where every expression is implicitly a function of all possible variables. Zucker’s lifting approach chooses explicit finite context, but tries to recover the convenience and sharing that the informal notation gave us.
That choice has philosophical weight. The term is not a small object floating inside a larger context. The context is part of the term’s identity. A function that ignores an input is still a function whose domain includes that input. This sounds pedantic until one tries to build a rewriting engine that must preserve soundness while compacting millions of related expressions.
For implementers, the attraction is that liftings are cheap. Bitvectors are compact, composition is straightforward, and common-lift extraction can be built into smart constructors. Zucker even points out that many e-graph identifiers have unused bit capacity in practice, leaving room to pack small lifting annotations alongside ordinary IDs. Larger contexts could fall back to allocated bitvectors or explicit lift nodes, much as small integers and big integers often coexist in runtime systems.
For researchers, the proposal suggests a route between two extremes. One extreme is fully explicit first-order encoding, where lift is just another function symbol and all its algebra is expressed through rewrite rules. That makes the idea portable to existing e-graph systems, but it pays overhead and exposes structural bureaucracy to the rewrite engine. The other extreme is baking lift into the e-graph core, which is cleaner and potentially faster, but demands new algorithms for union-find and e-matching. Zucker’s post is valuable because it keeps both views in play: the first-order model explains the semantics, while the baked-in version explains the engineering ambition.
Counter-Perspectives
The most obvious counter-perspective is that this may be too much machinery for many users. Explicit names, alpha-renaming, Skolemization, and free-variable analysis are familiar. They may be inelegant, but they are also well understood. A lifting e-graph asks implementers to modify the core identity model of the e-graph, not merely add a library of rewrites. That is a serious cost.
A second objection is that environment-passing semantics already gives a coherent alternative. One can treat every expression as a function from a large or infinite environment of variable names to values. In that world, sin(x) always means something like env |-> sin(env[x]), and unused variables are simply ignored. This model is less tightly typed by finite dimension, but it aligns with how many interpreters, SMT encodings, and symbolic systems already behave.
The lifting approach answers that infinite or global environments introduce their own conceptual burden. To talk about a function of two variables, one should not necessarily need to invoke an infinite map of names. Finite contexts make the shape of dependency explicit. The cost is that the representation must track how terms move between contexts.
A third concern is e-matching completeness. If the practical matcher refuses to traverse redundancy edges, then some valid matches will be missed. If it does traverse them, the system may enumerate large families of low-value matches involving variables that are introduced only to be discarded. This is not a small implementation detail. Pattern matching is where equality saturation spends much of its time, and a theory that is elegant at construction time can become painful if matching becomes too large or too subtle.
The best answer may be pluralistic. Some applications need sound but incomplete matching, especially if redundant-variable matches are rarely useful. Others may need explicit lifted patterns or a controlled unification mode. A mature lifting e-graph might expose several matching disciplines rather than pretending that one behavior serves every workload.
There is also the question of binding. Zucker deliberately treats lambdas as a later layer rather than the starting point. That restraint is useful, because the R^n -> R model shows that lifting is already meaningful without binders. Still, binders are where many variable representations prove themselves or fail. Lambda does not simply commute with lifting. It removes a variable from the context while changing the type of the term, which makes it closer to a projection that preserves information by turning it into a function type. Any full account of lifting e-graphs for programming languages will need to make this interaction precise.
The larger significance of Zucker’s article is not that it presents a finished library or a final theory. It is a record of a design idea becoming clearer as it is forced through examples: sin(x), f(g(h(x))), x * 0 = 0, commutativity, associativity, binder sketches, slotted e-graphs, and theorem prover experiments. The article’s rough edges are part of the substance. It shows a researcher trying to find the right abstraction without erasing the implementation grit that makes the abstraction matter.
Lifting e-graphs propose that the right way to share terms is not to forget context, and not to blindly duplicate context, but to represent movement between contexts as a first-class, algebraic fact. If that idea holds up, it could make equality saturation more precise in exactly the places where rewriting systems are most fragile: names, scopes, redundancy, and the quiet difference between two expressions that look the same on paper but live in different mathematical worlds.
Comments
Please log in or register to join the discussion