
A single OpenAI-compatible endpoint that fronts Azure OpenAI, OpenCode Zen, and a dozen other model providers, deployed end-to-end on Azure Kubernetes Service with one azd up command. Here is how the architecture comes together, what it costs, and where the rough edges still are.
The case for putting a proxy between your applications and your LLM providers gets stronger every quarter. Teams are no longer calling a single model from a single vendor. They are mixing Azure OpenAI for compliance-sensitive workloads, frontier models from Anthropic or OpenAI for hard reasoning tasks, and cheaper or free community models for everything in between. Managing API keys, budgets, rate limits, and spend tracking across all of that quickly becomes its own operational problem.
LiteLLM is the open-source answer that a lot of platform teams are landing on, and a recent deployment writeup from luke.geek.nz shows what it looks like to run it properly on Azure Kubernetes Service. The goal was a production-grade gateway you can stand up with a single azd up, with private networking, Redis caching, PostgreSQL spend tracking, and automatic TLS. The full source lives at lukemurraynz/LiteLLM.AKSGateway.

What changed
The pattern here is the multi-provider gateway moving from a convenience layer into core platform infrastructure. LiteLLM presents one OpenAI-compatible endpoint and routes to whatever backend you configure behind it, across more than 100 supported providers. Instead of distributing provider API keys to every developer, the platform team issues scoped virtual keys and controls which models each consumer can reach and what their budget is.
That consolidation is the strategic win. It turns model access into something you can govern centrally: one place to enforce authentication, one place to cap spend, one place to add caching, and one audit trail. For organizations trying to avoid lock-in to any single model vendor, a self-hosted gateway on infrastructure you already own is an appealing alternative to a SaaS routing layer that adds another vendor relationship and another data-residency question.
The architecture
The deployment uses the Azure Developer CLI with Bicep for infrastructure and PowerShell hooks for the deployment lifecycle. Everything provisions into a single resource group as a greenfield environment.
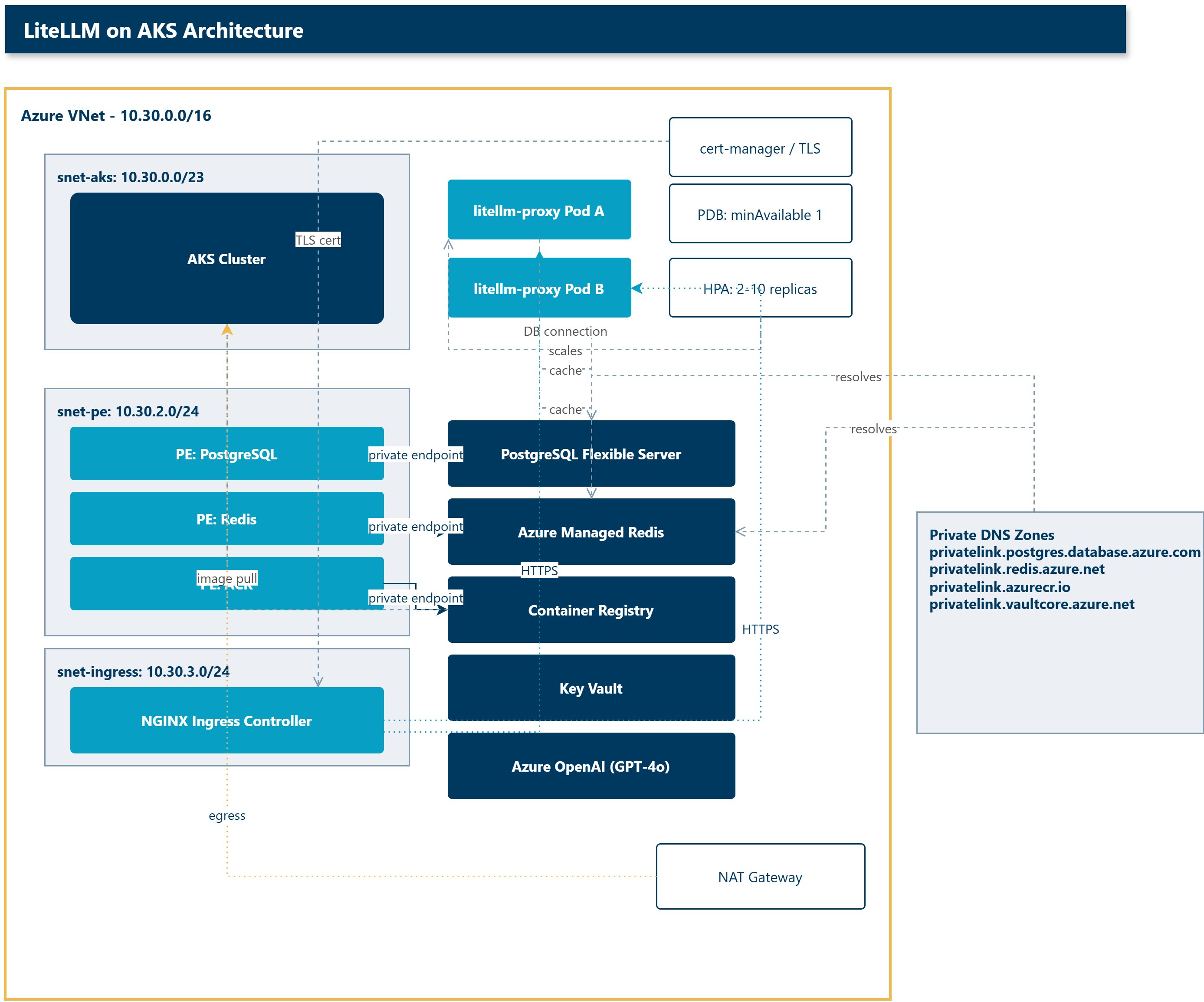
The component list reads like a checklist for a serious internal platform service. An AKS cluster on Standard tier with system and user node pools running Azure CNI Overlay. An Azure Container Registry for the LiteLLM image. PostgreSQL Flexible Server for spend tracking, virtual key storage, and user management. Azure Managed Redis for distributed caching and rate limiting across replicas. Key Vault for credential storage. An Azure OpenAI GPT-4o deployment. And the networking to tie it together: a VNet with three subnets, a NAT Gateway, and private DNS zones.
The security posture is the part worth copying. Every data service, PostgreSQL, Redis, ACR, and Key Vault, sits behind a private endpoint with no public IP on the data plane. The VNet splits into three subnets: 10.30.0.0/23 for AKS nodes, 10.30.2.0/24 for private endpoints, and 10.30.3.0/24 reserved for the NGINX ingress controller. Outbound traffic runs through a NAT Gateway using AKS userAssignedNATGateway outbound type, which sidesteps the SNAT port exhaustion that loadBalancer outbound type hits at scale. Four private DNS zones handle private endpoint resolution and link to the VNet automatically.
The public path stays cleanly separate: NGINX ingress gets a public LoadBalancer IP, and cert-manager handles Let's Encrypt TLS through the HTTP-01 challenge.
The deployment lifecycle
azd up runs through four staged PowerShell hooks. Preprovision generates the random secrets for the PostgreSQL admin password, the LiteLLM master key, and the salt key. Provision deploys the Bicep template, which takes 10 to 15 minutes. Postprovision pulls AKS credentials, patches CoreDNS, deploys the Kubernetes manifests through kustomize, and sets up ingress. Postdeploy refreshes the cluster secret with the latest connection strings, restarts the deployment, and syncs the public DNS record.
The CoreDNS detail is the kind of thing that bites everyone once. AKS pods resolve DNS through CoreDNS, which by default forwards everything to Azure DNS at 168.63.129.16. That resolves the private endpoints correctly, but it cannot resolve public domains, which breaks cert-manager's Let's Encrypt HTTP-01 challenge. The fix is a CoreDNS ConfigMap patch that sends public queries to 8.8.8.8 while keeping the Azure private zones on 168.63.129.16. The postprovision hook applies it, but knowing why it exists saves a debugging session.
Provider comparison: one proxy, many backends
The interesting test was fronting multiple providers through the same endpoint. Beyond Azure OpenAI, the deployment added OpenCode Zen and Go models. OpenCode Zen exposes an OpenAI-compatible endpoint, which makes it a drop-in addition to the model list.
The gotcha sits with the Anthropic-compatible Go models. LiteLLM's Anthropic provider appends /v1/messages to the base URL automatically. Set the base URL to https://opencode.ai/zen/go/v1 and the request goes to /v1/v1/messages, which correctly returns a 404. Setting it to https://opencode.ai/zen/go fixes it. This is the recurring tax of multi-provider routing: each provider has its own assumptions about URL construction, auth headers, and API versioning, and the proxy has to paper over all of them. The payoff is that downstream consumers never see any of it.

The single proxy ended up exposing 19 models across Azure OpenAI, OpenCode Zen, and OpenCode Go. A few Go subscription models returned a usage-limit error because the monthly quota was exhausted, but that still confirmed the routing path resolved correctly. The free Zen models stayed available through the same proxy key.
Production configuration that matters
Several settings pulled from the LiteLLM production best practices are worth lifting wholesale. The Redis configuration was the surprise: using host, port, and password separately rather than a single redis_url string is measurably faster, around 80 RPS by LiteLLM's own benchmarks.
The database tuning is less dramatic but real. proxy_batch_write_at: 60 batches spend updates every 60 seconds instead of writing on every request, which meaningfully cuts PostgreSQL write load. Paired with database_connection_pool_limit: 10 across 3 replicas and 4 workers each, that lands at 120 total connections, comfortably inside PostgreSQL defaults. Two more belong in any production gateway: allow_requests_on_db_unavailable: true keeps the proxy serving when PostgreSQL briefly hiccups during a scale event, and LITELLM_MODE: "PRODUCTION" disables the dotenv lookup that would otherwise scan for a .env file at container startup.
Multi-replica behavior
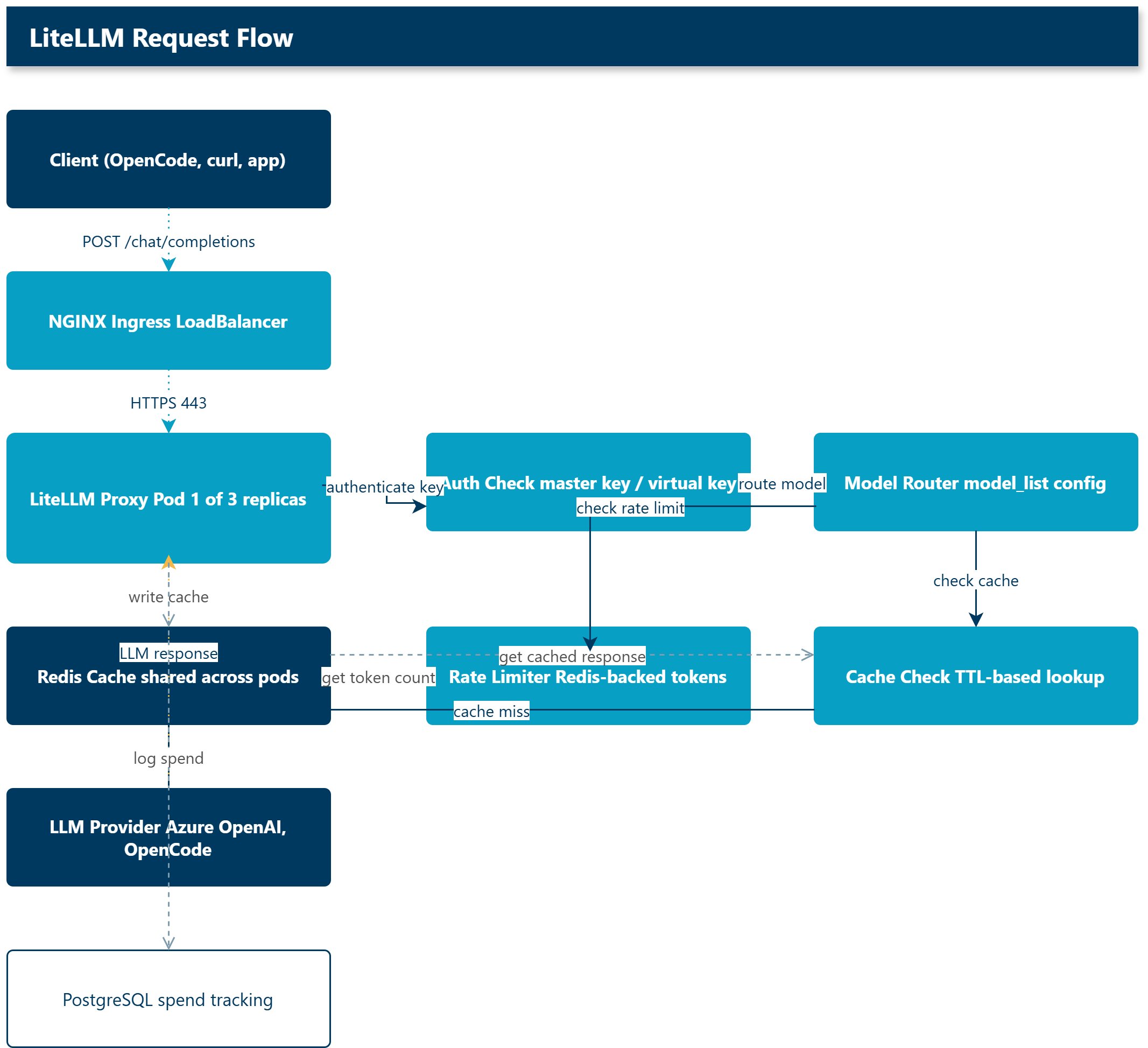
The whole point of running this on AKS rather than a single container is horizontal scale-out, and that only works if the cache is genuinely shared. The cross-pod test confirmed it: a request cached by one pod (litellm-proxy-9b9d6dffd-p2qqg, cache miss at 1.040s) was served from Azure Managed Redis by a different pod (litellm-proxy-9b9d6dffd-qjfkr, cache hit at 0.636s). Through the public ingress, a repeated short prompt went from a 0.448s miss to a 0.132s hit. NGINX distributes requests across pods transparently and Redis serves cached responses regardless of which pod handles the call. That is the behavior you need before trusting any autoscaler.
The Kubernetes deployment reflects that operational care. Rolling updates use maxUnavailable: 0 and maxSurge: 1 so the replica count never dips during a rollout. The readiness probe waits on /health/readiness, which will not pass until Prisma finishes migrate deploy, important because the first deploy runs schema migrations before serving traffic. Graceful shutdown uses a 620-second termination grace period, deliberately longer than LiteLLM's 600-second request timeout, with a 5-second preStop sleep so the load balancer can deregister the pod before SIGTERM. The HPA targets 60% CPU and 80% memory, scaling between 2 and 10 replicas, and a PodDisruptionBudget with minAvailable: 1 prevents node drains from killing the last pod.
The container also runs hardened: readOnlyRootFilesystem: true, runAsNonRoot: true, and all capabilities dropped, with emptyDir volumes mounted at the handful of paths LiteLLM needs to write to for Prisma binaries, migration state, and UI assets.
Where the rough edges are
The writeup is refreshingly honest about what is not clean yet. Kubernetes secrets do not hot-reload, so adding a new provider key meant force-deleting pods because envFrom secrets only load at pod startup. The virtual key deletion path surfaced a Redis cluster MOVED error during auth cache invalidation; the key disappeared from the list but the failure was left as a follow-up rather than papered over. And on the first deploy, cert-manager started the Let's Encrypt flow before the DNS A record had propagated, leaving a stale solver pod that needed the Certificate and CertificateRequest objects deleted to retry.
These are the normal frictions of assembling a platform service from independent moving parts, and naming them is more useful than pretending the deployment was frictionless.
Business impact
This is not a free deployment, and the cost framing matters for anyone evaluating it. AKS Standard tier with two D4s_v3 node pools, Azure Managed Redis Balanced_B0, and PostgreSQL Standard_B2ms runs roughly $400 to $500 per month in Australia East, before the pay-per-token cost of the Azure OpenAI deployment. Teardown is a single azd down --purge, with a predown hook that deletes the litellm namespace first so no orphaned load balancer resources linger. If you plan to restore later, export the PostgreSQL database and store the LITELLM_SALT_KEY safely, since you need it to decrypt stored credentials.
Whether that monthly figure is worth it comes down to scale and governance needs. For a small team calling one provider, a managed routing SaaS or direct API calls are simpler and cheaper. For an organization standardizing model access across multiple teams, enforcing budgets, keeping the data plane fully private, and avoiding commitment to any single model vendor, owning the gateway on infrastructure you already run starts to pay for itself, both in control and in the optionality it preserves. The next frontier sits with LiteLLM's MCP Gateway features, which would let the same proxy front documentation and tooling servers alongside the models, extending the central-governance argument from inference to the whole agent toolchain.
Comments
Please log in or register to join the discussion