Netflix's container runtime migration revealed surprising CPU architecture bottlenecks when launching hundreds of layered containers simultaneously, leading to global lock contention and system stalls.
When you click play on Netflix, hundreds of containers spring to life in seconds to deliver your streaming experience. At Netflix scale, efficiently scaling containers is critical—but our journey to modernize our container runtime hit an unexpected wall: the CPU architecture itself.
The Scaling Crisis
As we migrated from our old virtual kubelet + Docker solution to a modern kubelet + containerd runtime, we started seeing alarming patterns. Some nodes would stall for long periods, with health checks timing out after 30 seconds. The culprit? The mount table length was exploding, and reading it alone could take upwards of 30 seconds.
Looking at systemd's stack, it was clear the system was busy processing mount events, sometimes leading to complete system lockup. Kubelet was frequently timing out when communicating with containerd. The affected nodes were almost exclusively r5.metal instances, and they were starting applications whose container images contained many layers (50+ layers each).
The Root Cause: Lock Contention
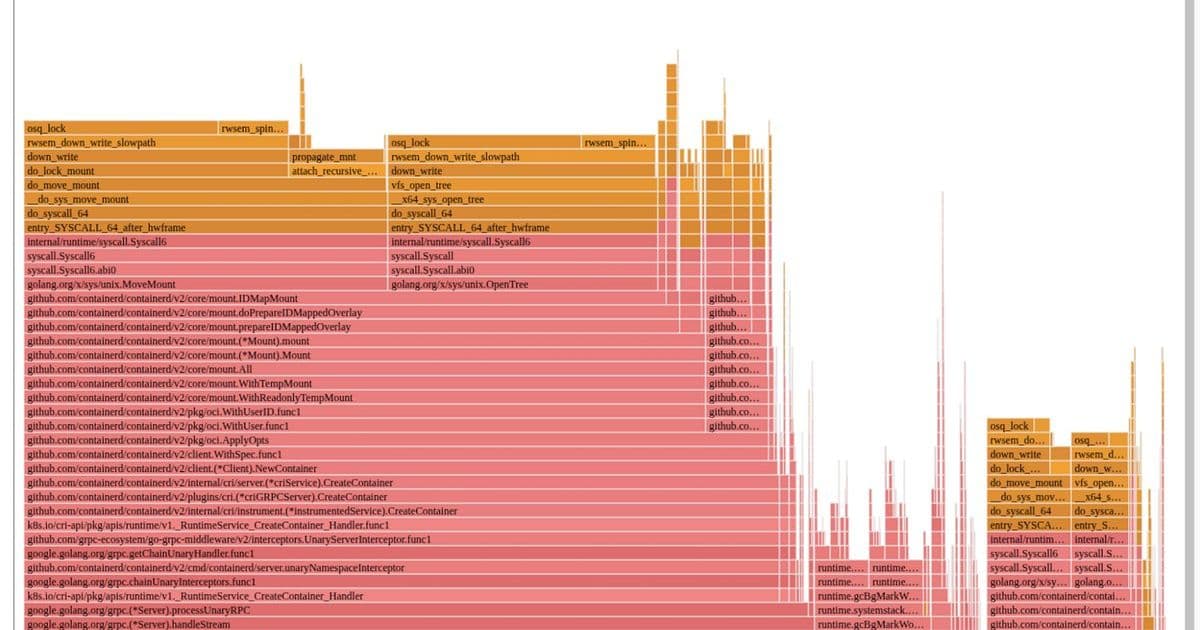
The flamegraph told the story clearly—containerd was spending nearly all its time trying to grab kernel-level locks during mount-related activities when assembling container root filesystems.
Here's what was happening: for each layer in a container image, containerd was executing:
open_tree()to get a reference to the layer directorymount_setattr()to set the idmap for the container's user rangemove_mount()to create a bind mount with the new idmap applied
These bind mounts were then used as lowerdirs to create the overlayfs-based root filesystem. Once constructed, the bind mounts were unmounted since they weren't needed anymore.
If a node was starting many containers simultaneously, every CPU ended up busy executing these mounts and unmounts. The kernel VFS has various global locks related to the mount table, and each operation required taking those locks. For 100 containers with 50 layers each, that's 20,200 mount operations all competing for the same global locks!
Why the New Runtime Changed Everything
The difference between old and new runtimes came down to user namespaces. Previously, all containers shared a single host user range, with UIDs shifted at untar time. The new runtime gives each container a unique host user range for better security—if a container escapes, it can only affect its own files.
To avoid the costly process of untarring and shifting UIDs for every container, the new runtime uses the kernel's idmap feature. This allows efficient UID mapping per container without copying files, but it requires many mount operations per container.
Hardware Matters More Than You Think
Our investigation revealed why r5.metal instances were particularly vulnerable. We benchmarked container launches across different AWS instance types:
- r5.metal (5th gen Intel, dual-socket, multiple NUMA domains)
- m7i.metal-24xl (7th gen Intel, single-socket, single NUMA domain)
- m7a.24xlarge (7th gen AMD, single-socket, single NUMA domain)
At low concurrency (≤20 containers), all platforms performed similarly. But as concurrency increased, r5.metal began failing around 100 containers, while 7th generation instances maintained lower launch times and higher success rates.
The NUMA Effect
Non-Uniform Memory Access (NUMA) design, where each processor has its own local memory but relies on interconnects for remote access, played a crucial role. Dual-socket architectures implement NUMA, leading to faster local but higher remote access latencies.
When we tested a 48xl instance with 2 NUMA nodes versus a 24xl single NUMA node instance, the extra hop introduced high latencies and failures very quickly.
Hyperthreading's Hidden Cost
Disabling hyperthreading on m7i.metal-24xl improved container launch latencies by 20-30%. When hyperthreading is enabled, each physical core is split into two logical CPUs that share execution resources. For workloads relying heavily on global locks, this competition for shared resources worsens lock contention.
Cache Architecture Matters
Some modern server CPUs use a mesh-style interconnect with centralized queueing structures (like Intel's Table of Requests), while others use distributed, chiplet-based architectures (like AMD's EPYC).
In centralized designs, all communication passes through a central structure that can only handle one request for a given address at a time. When global locks are under heavy contention, requests pile up, causing memory stalls and latency spikes.
Our microbenchmark results confirmed this: on r5.metal, eliminating NUMA by using a single socket significantly dropped latency. On m7i.metal-24xl, disabling hyperthreading further improved scaling. On m7a.24xlarge, performance scaled the best, demonstrating that distributed cache architecture handles cache-line contention more gracefully.
The Software Solution
While understanding hardware impacts was crucial, the root cause remained contention over a global lock. Working with containerd upstream, we identified two solutions:
- Use newer kernel mount APIs (
fsconfig()) to supply idmapped lowerdirs as file descriptors instead of paths - Map the common parent directory of all layers, reducing mount operations from O(n) to O(1) per container
We opted for the second approach since it benefits more of the community without requiring a new kernel. The result? Containerd's flamegraph no longer shows mount-related operations dominating—we had to highlight them in purple just to see them at all!
Lessons Learned
Our journey revealed how deeply intertwined software and hardware architecture can be when operating at scale. The best solution combined hardware awareness with software improvements:
- Route workloads to CPU architectures that scale better under these conditions
- Minimize per-layer mount operations to eliminate global lock bottlenecks
This experience underscores the importance of holistic performance engineering. Understanding and optimizing both the software stack and the hardware it runs on is key to delivering seamless user experiences at Netflix scale.
These insights should help others navigate the evolving container ecosystem, transforming potential challenges into opportunities for building robust, high-performance platforms.
Comments
Please log in or register to join the discussion