Microsoft and NVIDIA collaboration achieves breakthrough performance for the 690-billion-parameter DeepSeek-V3.2 model using NVFP4 quantization on Blackwell architecture, delivering up to 2.5x lower latency and 16x better user density compared to previous-generation H200 GPUs.
Unlocking High-Performance Inference for DeepSeek with NVFP4 on NVIDIA Blackwell
Microsoft and NVIDIA have achieved significant breakthroughs in large language model inference performance through their collaboration on optimizing the DeepSeek-V3.2 model. This 690-billion-parameter Mixture-of-Experts (MoE) model now delivers substantially improved performance on NVIDIA's latest Blackwell architecture, setting new benchmarks for efficiency and user capacity in production environments.
What Changed: End-to-End Optimization Across the Stack
The partnership focused on optimizing DeepSeek-V3.2 across three critical layers:
- Hardware Platform: Utilizing the NVIDIA GB200 NVL72 platform, which combines 2 Grace CPUs with 4 Blackwell GPUs per node
- Model Representation: Implementing NVIDIA's new NVFP4 checkpoint format for quantized model weights
- Inference Runtime: Leveraging TensorRT LLM as the production-grade serving engine
This comprehensive optimization approach addresses the inherent challenges of deploying massive MoE models at scale while maintaining cost-effectiveness and output quality.
Provider Comparison: Blackwell vs. Hopper Architecture
The performance improvements are dramatic when comparing NVIDIA's latest Blackwell architecture with the previous-generation Hopper architecture used in H200 GPUs.
Technical Specifications Comparison
| Specification | NVIDIA Blackwell (GB200) | NVIDIA Hopper (H200) | Improvement |
|---|---|---|---|
| GPU Memory | 186 GB HBM3e | 140 GB HBM3e | 32% increase |
| NVFP4 Performance | 10 PFLOPS per GPU | 2 PFLOPS per GPU (FP8) | 5x increase |
| DeepSeek Model Size | 415 GB (NVFP4) | 690 GB (FP8) | 1.7x reduction |
Performance Benchmarks
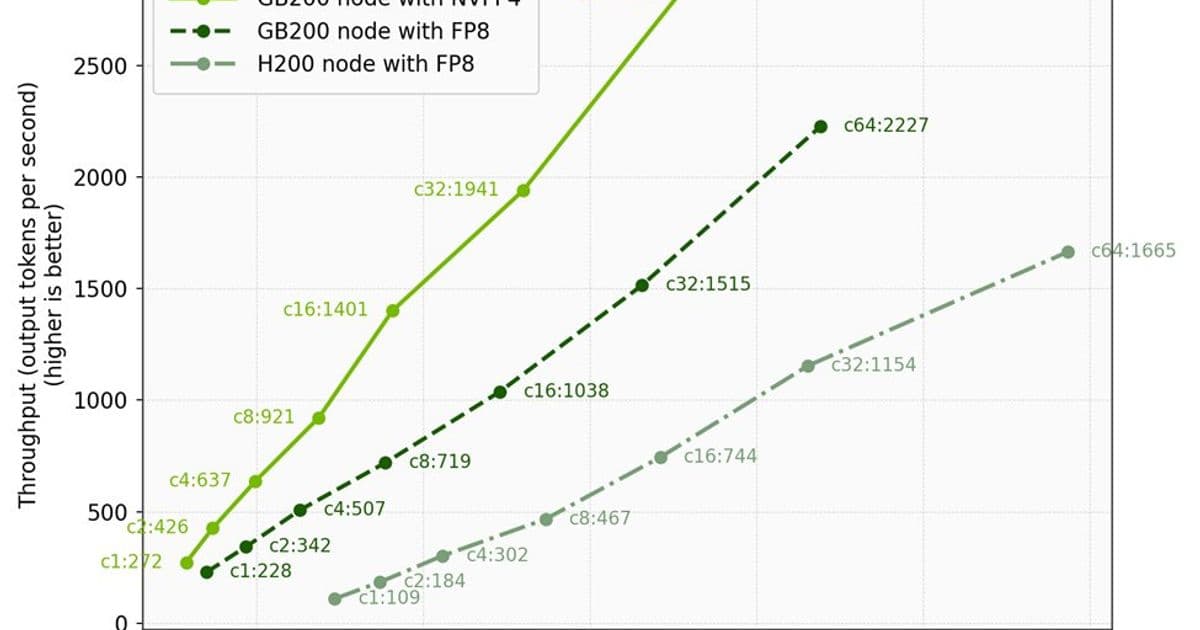
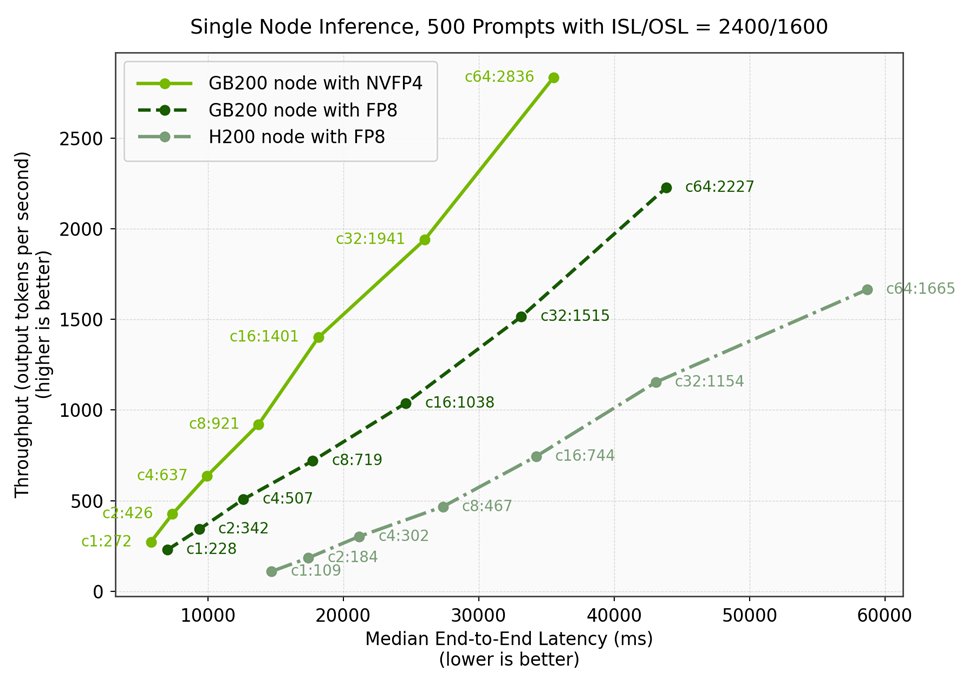
Using an aligned benchmark methodology with 2,400 token inputs and 1,600 token outputs, the results demonstrate clear advantages:
| Configuration | Concurrency | Throughput (tks/s) | Median E2E Latency (ms) |
|---|---|---|---|
| GB200 with NVFP4 | 1 | 272 | 5,801 |
| GB200 with FP8 | 1 | 228 | 7,015 |
| H200 with FP8 | 1 | 109 | 14,716 |
At single-concurrency workloads, the Blackwell configuration delivers 2.5x lower latency compared to H200 deployments. This improvement becomes even more significant when considering user capacity.
NVFP4: The Enabling Technology
NVFP4 represents NVIDIA's innovation in 4-bit floating point precision, specifically designed for the Blackwell architecture. By encoding quantized blocks with non-power-of-two scaling factors, NVFP4 simultaneously achieves:
- Higher computational throughput
- Reduced memory footprint
- Preserved model accuracy
For DeepSeek-V3.2, NVFP4 quantization reduced the memory requirements by 1.7x compared to the original FP8 format (415 GB vs. 690 GB), enabling better GPU utilization and significant cost savings.
Accuracy Preservation
Critically, NVFP4 maintains near-parity with FP8 across industry benchmarks:
| Benchmark | FP8 Score | NVFP4 Score | Difference |
|---|---|---|---|
| MMLU | 0.802 | 0.799 | -0.003 |
| GPQA | 0.849 | 0.835 | -0.014 |
| Diamond | 0.756 | 0.756 | 0.000 |
| LiveCodeBench V6 | 0.391 | 0.401 | +0.010 |
| SciCode | 0.934 | 0.923 | -0.011 |
This accuracy preservation makes NVFP4 suitable for production inference where both memory efficiency and output quality are critical.
Business Impact: Cost and Efficiency Transformation
The performance improvements translate directly to business value through two key metrics:
1. Reduced Latency
With up to 2.5x lower end-to-end latency, applications powered by DeepSeek-V3.2 on Blackwell provide significantly improved response times, enhancing user experience across various real-time applications.
2. Increased User Density
The most dramatic improvement comes in user capacity per GPU. When maintaining a consistent 15,000ms latency target:
- A single GB200 node (4 GPUs) can serve 8 concurrent users
- A comparable H200 node (8 GPUs) can serve only 1 concurrent user
This translates to 16x more users per GPU when moving from H200 to GB200 NVFP4 deployments. For organizations running large-scale inference services, this represents a fundamental shift in cost efficiency and capacity planning.
Implementation Considerations
For organizations considering migration to this new configuration, several factors should be evaluated:
Hardware Requirements
The NVIDIA GB200 NVL72 platform represents a significant investment, with each node containing:
- 2 Grace CPUs
- 4 Blackwell GPUs
- 1,712 GB of GPU memory total
Software Stack
The optimized configuration requires:
- TensorRT LLM v1.2.0rc8 or later
- NVFP4-quantized model weights (nvidia/DeepSeek-V3.2-NVFP4)
- Proper configuration of CUDA graphs, KV cache settings, and MoE backends
Migration Path
Organizations currently running DeepSeek-V3.2 on H100 or H200 GPUs should consider:
- Testing workloads on Blackwell hardware to validate performance improvements
- Planning for NVFP4 model conversion to optimize memory usage
- Updating inference serving infrastructure to leverage TensorRT LLM optimizations
Future Directions
This collaboration represents just the beginning of what's possible with the Blackwell architecture. Microsoft and NVIDIA are already planning:
- Rack-scale inference: Leveraging all 72 GPUs on the GB200 NVL72 system with disaggregated serving and TensorRT LLM's Wide EP capabilities
- Extension to additional models: Applying the same optimization approach to other model families beyond DeepSeek
- Further kernel tuning: Continued optimization of specialized kernels for MoE architectures
For organizations running large-scale AI inference workloads, this breakthrough offers a compelling path to improved performance, reduced costs, and enhanced user capacity. The combination of NVIDIA's latest hardware innovations with sophisticated software optimization techniques demonstrates the continued progress in making advanced AI models more accessible and cost-effective for production deployment.
For more information about implementing DeepSeek-V3.2 on Microsoft Foundry with these optimizations, see the official documentation.
{{IMAGE:2}}
Comments
Please log in or register to join the discussion