
Nvidia's RTX Neural Texture Compression technology leverages AI to reduce VRAM usage by up to 80% while maintaining or improving visual quality, with performance implications across GPU tiers.
Nvidia's RTX Neural Texture Compression: A Game-Changer for VRAM Efficiency

Nvidia's RTX Neural Texture Compression (NTC) represents a significant advancement in graphics rendering technology, utilizing AI-driven neural networks to compress and decompress texture data with remarkable efficiency. This innovation can reduce VRAM requirements by up to 80%, potentially revolutionizing how games and applications manage memory-intensive assets. As part of Nvidia's neural shading initiative, NTC makes portions of the graphics pipeline trainable, allowing developers to leverage small neural networks executed within shaders, accelerated by hardware through Cooperative Vector technology.
Technical Architecture of Neural Texture Compression
RTX Neural Texture Compression operates through three distinct modes in DirectX 12: Inference on Load, Inference on Sample, and Inference on Feedback. Vulkan support currently excludes Inference on Feedback, limiting available modes to Inference on Load and Inference on Sample.
The compression process transforms original textures into a combination of weights for a small neural network and latent features. During decompression, these elements are reconstructed to produce the final texture output. Each mode offers different trade-offs between performance, memory efficiency, and visual quality:
- Inference on Sample: Decompresses texels on-demand during rendering, providing the greatest VRAM reduction but incurring performance costs due to real-time neural computation.
- Inference on Load: Decompresses textures during game/map loading and transcodes them into block-compressed formats (BCn), eliminating performance penalties at the cost of VRAM savings.
- Inference on Feedback: Uses Sampler Feedback to decompress only the texture tiles required for the current view, offering a compromise between the other two modes.

Notably, NTC is deterministic rather than generative, ensuring consistent output across rendering sessions. The technology employs Stochastic Texture Filtering (STF) to reduce visual artifacts by introducing randomness during texture filtering, which is particularly effective on Blackwell GPUs that feature 2x improved point-sampled texture filtering rates.
Why Neural Texture Compression Matters
Traditional texture compression formats like BCn have significant limitations. NTC achieves higher compression ratios while supporting materials with up to 16 channels, compared to BCn's 1-4 channel limitation. This expanded channel capacity enables more complex material representations and higher fidelity textures.
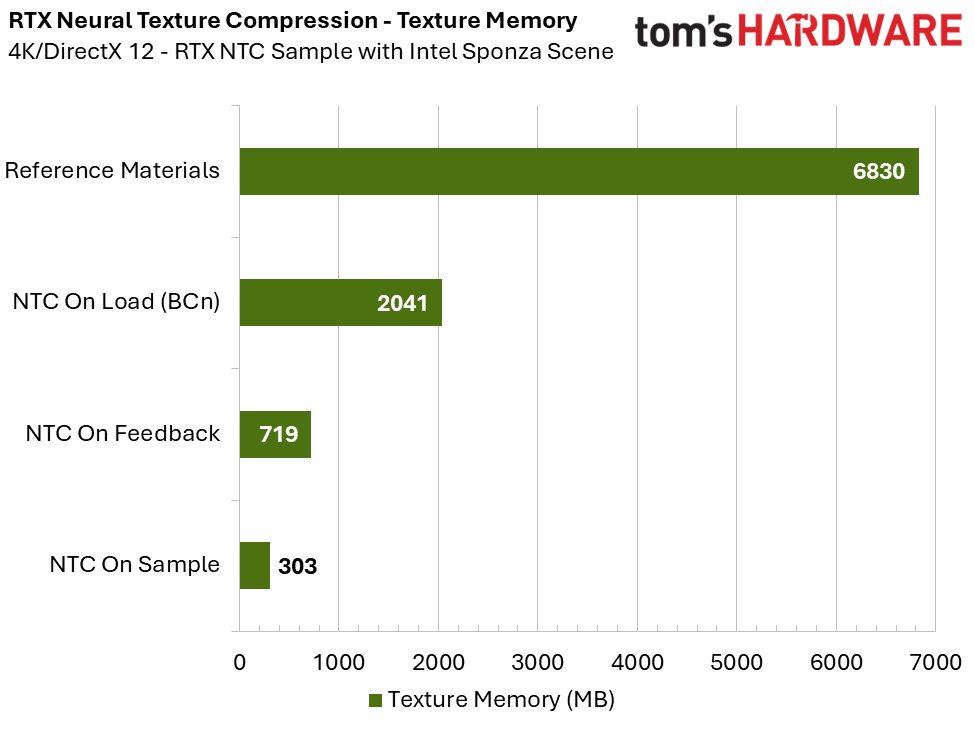
Benchmark data from the RTX Neural Texture Compression sample demonstrates the technology's effectiveness. When compared to Inference on Load (which transcodes textures to BCn), Inference on Sample mode offers an 85% reduction in required texture memory while maintaining superior image quality closer to uncompressed reference textures.
However, the technology has specific requirements. STF introduces visible noise when anti-aliasing is completely disabled, requiring either DLSS or TAA for optimal visual results. This is particularly relevant for Inference on Sample mode, which mandates STF usage.
Performance Benchmarks Across GPU Tiers
The practical implementation of NTC varies significantly across different hardware generations, as demonstrated by comprehensive testing across multiple GPUs:
High-End Performance (RTX 5090)
At 4K resolution, the RTX 5090 demonstrates minimal frametime cost for Inference on Sample when using TAA. The performance difference compared to BCn-transcoded textures is negligible, with DLSS incurring additional tensor core overhead but still providing net benefits through resolution scaling. This positions the 5090 as ideal for Inference on Sample implementation in high-resolution gaming scenarios.
Mid-Range Performance (RTX 5070)
The RTX 5070 shows a frametime cost of approximately 0.50-0.70 ms at 1440p using Inference on Sample with TAA. At 4K, this increases to roughly 1.20 ms. While these figures represent absolute increases, the relative performance impact is likely smaller in real-world games with more complex rendering pipelines and higher baseline frametimes.
Entry-Level Performance (RTX 5060)
At 1080p, the RTX 5060 incurs a 0.60-0.70 ms performance penalty with Inference on Sample. Performance degrades at higher resolutions, with costs exceeding 1 ms at 1440p and approaching 2 ms at 4K. This suggests that while the 5060 can benefit from VRAM savings at its native resolution, the technology becomes less practical at higher resolutions.
Mobile Performance (RTX 4060 Mobile)
The laptop implementation shows a 0.70-0.85 ms cost at 1080p, approaching the 1 ms threshold where perceptible performance impacts may begin. For mobile GPUs with limited VRAM (like the 8GB in the 4060 Mobile), the VRAM savings may outweigh the performance penalty in memory-constrained scenarios.

Implementation Strategies and Market Implications
According to Alexey Panteleev, Distinguished DevTech Engineer at Nvidia and NTC developer, the optimal implementation strategy varies based on hardware capabilities and game design. "Inference on Sample is only viable on the fastest GPUs," Panteleev explains. "That's why we also provide the Inference On Load mode that transcodes to BCn and only provides disk size or download size reduction, not VRAM benefits."
The technology's flexibility allows for per-texture implementation decisions. Developers can selectively apply NTC to textures where quality loss is acceptable while maintaining traditional formats for critical assets like displacement maps. This selective approach maximizes both performance and visual fidelity.

The market implications of NTC extend beyond VRAM savings. The technology enables:
- Reduced storage requirements: Games with high-resolution textures can significantly reduce their disk footprint
- Enhanced streaming efficiency: Lower PCIe bandwidth requirements improve asset streaming performance
- Democratization of high-fidelity graphics: Lower-end systems can achieve visual quality previously reserved for high-end hardware
- Future-proofing: As texture resolutions continue to increase, NTC provides a scalable solution for memory management
The Future of Neural Rendering
Nvidia's NTC represents just one component of a broader shift toward neural rendering technologies. The company's neural shading initiative aims to make portions of the graphics pipeline trainable, allowing AI models to estimate rendering results that would traditionally require complex shader code.
As this technology matures, we can expect several developments:
- Improved inference efficiency to reduce performance costs across all GPU tiers
- Wider adoption of neural compression techniques for other rendering elements beyond textures
- Integration with emerging real-time ray tracing and path tracing technologies
- Standardization of neural rendering APIs for cross-platform compatibility
The RTX Neural Texture Compression sample available on GitHub provides developers with hands-on experience implementing this technology. As the gaming industry continues to push visual boundaries, innovations like NTC will play an increasingly critical role in balancing performance, memory efficiency, and visual fidelity.
For more information on implementing NTC, developers can refer to the official Nvidia documentation and the Vulkanised 2025 presentation that outlined additional capabilities of the technology.
Comments
Please log in or register to join the discussion