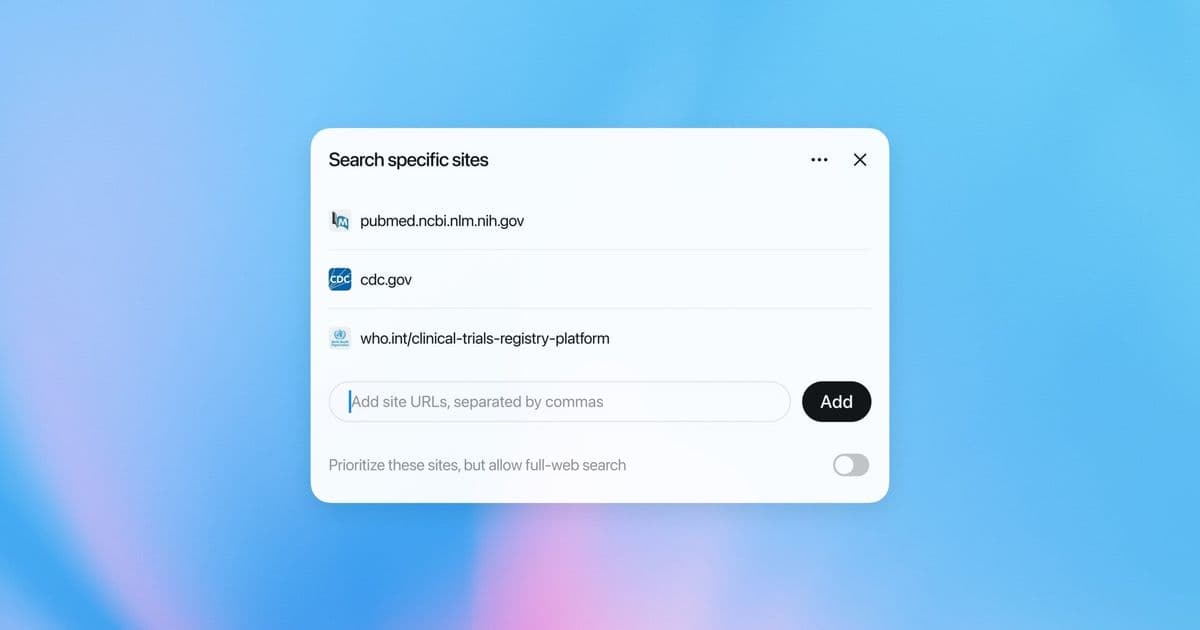
OpenAI has upgraded ChatGPT's deep research feature with GPT-5.2, introducing a full-screen reporting interface and the ability to limit searches to specific websites – enhancements that signal AI's expanding role in specialized information retrieval while raising questions about source bias and verification.
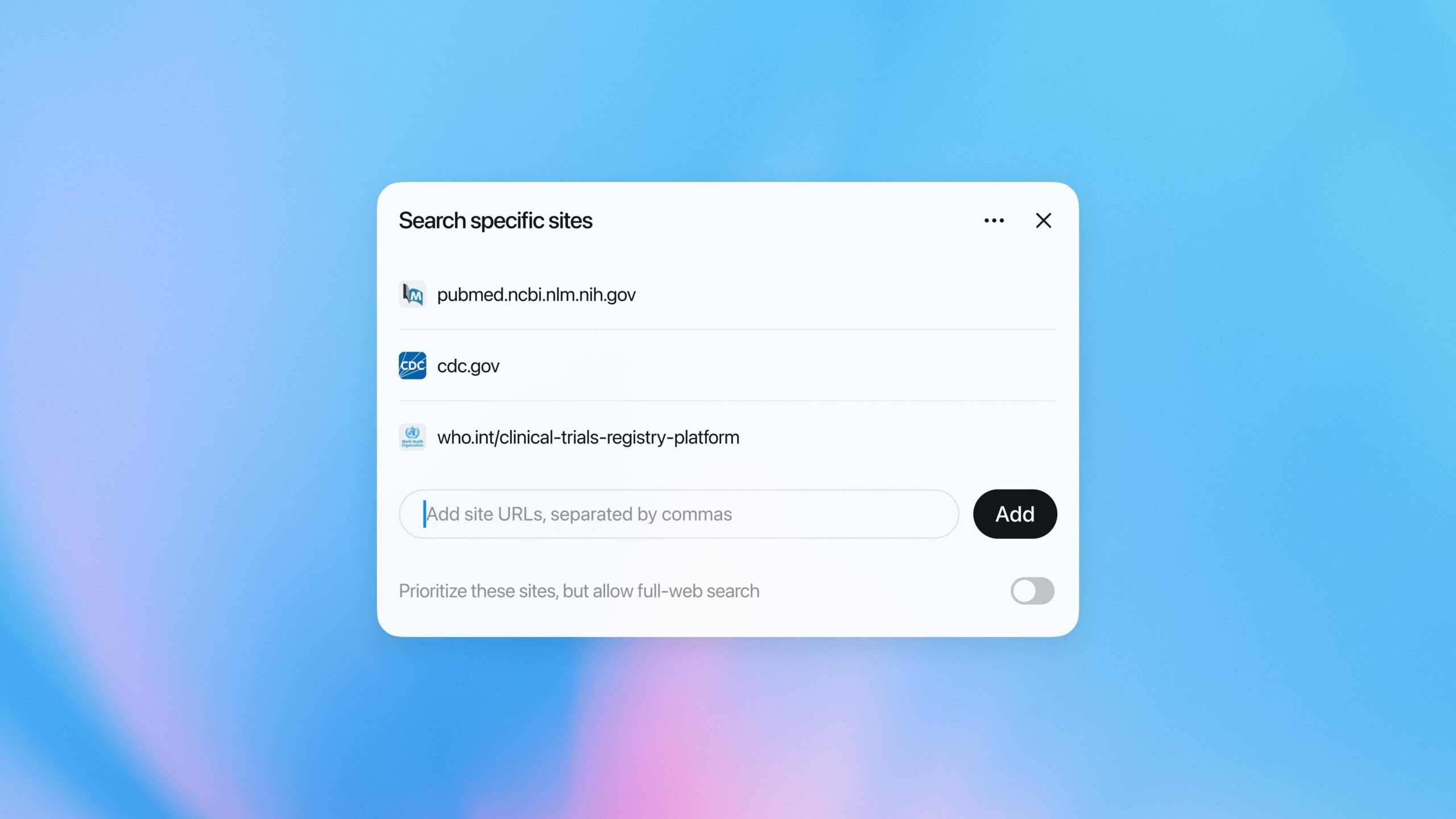
The trajectory of AI-assisted research continues its upward climb as OpenAI deploys significant upgrades to ChatGPT's deep research tool. Moving beyond broad web queries, the updated feature now operates on the GPT-5.2 model and introduces two pivotal functionalities: a distraction-free full-screen report view and the capability to constrain research to user-specified websites. These changes, announced by OpenAI, represent a deliberate shift towards more controlled and immersive analysis environments.
Key technical advancements underpin this evolution. The migration to GPT-5.2 brings measurable improvements in reasoning coherence and factual grounding compared to prior iterations, particularly for synthesizing complex technical or academic sources. Users can now generate comprehensive reports rendered in a dedicated full-screen view, minimizing interface clutter—a practical response to feedback about fragmented research workflows. More notably, the ability to anchor queries to particular domains (e.g., site:cdc.gov or site:arxiv.org) allows professionals to bypass generic results and zero in on vetted repositories. A medical researcher, for instance, could instruct ChatGPT to analyze vaccine efficacy data solely from PubMed and WHO domains, significantly narrowing the scope.
This push towards precision aligns with broader industry patterns. Tools like Perplexity AI and Scite have similarly emphasized citation accuracy and source filtering, suggesting a collective move away from the 'black box' reputation of early generative AI. OpenAI’s update explicitly acknowledges that trust in AI outputs hinges partly on constraining the universe of source material. Early adopters report efficiency gains in literature reviews and competitive intelligence, where time previously spent sifting through irrelevant results is notably reduced.
Nevertheless, critical perspectives highlight inherent tensions. Restricting searches to predefined websites transfers significant responsibility to users for source selection—a task requiring domain expertise not all possess. If a user instructs the tool to research climate policy solely using site:exxonmobil.com, the resulting synthesis, while technically accurate to the sources, would present a dangerously skewed perspective. This functionality doesn’t inherently evaluate source credibility; it merely obeys parameters. Reliability thus becomes contingent on the user’s critical judgment and the comprehensiveness of their selected domains.
Technical limitations also persist. GPT-5.2, while advanced, remains susceptible to subtle hallucination when interpreting dense or ambiguous source material, particularly in niche technical fields. The full-screen report view, while cleaner, offers no new mechanisms for fact-checking or source-weighted confidence scoring. Critics argue these updates prioritize presentation over fundamental verification—polishing the output vessel without sufficiently addressing content integrity concerns raised by researchers at institutions like MIT.
The update arrives amidst intensifying competition in specialized AI research tools. Startups like Elicit focus on rigorous academic paper analysis, while others like Humata specialize in document-centric Q&A. OpenAI’s strength lies in versatility, but its approach invites scrutiny: Can a general-purpose model truly outperform domain-specific alternatives when tasked with high-stakes research? The new website-filtering feature partially addresses this by enabling pseudo-specialization, yet the underlying model’s breadth may still dilute nuanced comprehension compared to tools fine-tuned on scientific corpora.
Ultimately, these enhancements mark a pragmatic step toward making AI research assistants more targeted and user-directed. However, they simultaneously underscore that even advanced AI cannot autonomously navigate the complexities of source credibility and contextual bias. The tool’s effectiveness will increasingly depend on symbiotic human oversight—the researcher’s discernment in defining parameters and scrutinizing outputs—highlighting that AI, at this stage, augments rather than replaces critical analysis.
Comments
Please log in or register to join the discussion