OpenBrief offers a desktop application that converts video and audio content into transcribed, summarized briefings with conversational AI capabilities, all running locally for privacy.
OpenBrief has launched a desktop application designed to transform how people interact with video and audio content, converting media files into searchable, transcribed briefings with AI-powered summaries and chat functionality. The project, available on GitHub, represents an approach to content consumption that prioritizes privacy and local processing.
The application addresses a common problem in today's media-rich environment: the difficulty of extracting and retaining valuable information from hours of video and audio content. OpenBrief allows users to import local media files or video URLs, extract transcripts, generate grounded summaries, and then chat with the content to ask specific questions or clarify points.
"The tool builds a searchable library from video links or local files, then extracts transcripts and keeps everything in one place," explains the project documentation. "Open any item to read the transcript, generate a grounded summary, and chat with the media context side by side."
Technically, OpenBrief is built as a pnpm/Turborepo workspace centered on a Tauri v2 desktop application. This architecture allows for a cross-platform desktop experience while maintaining a modular codebase. The project supports multiple AI models for different tasks:
- Speech-to-text: Whisper, Parakeet, Qwen3-ASR
- Text-to speech: Supertonic 3, Qwen3-TTS
- Large language models: OpenAI GPT, Anthropic Claude, Google Gemini, OpenRouter DeepSeek, and local Gemma 4
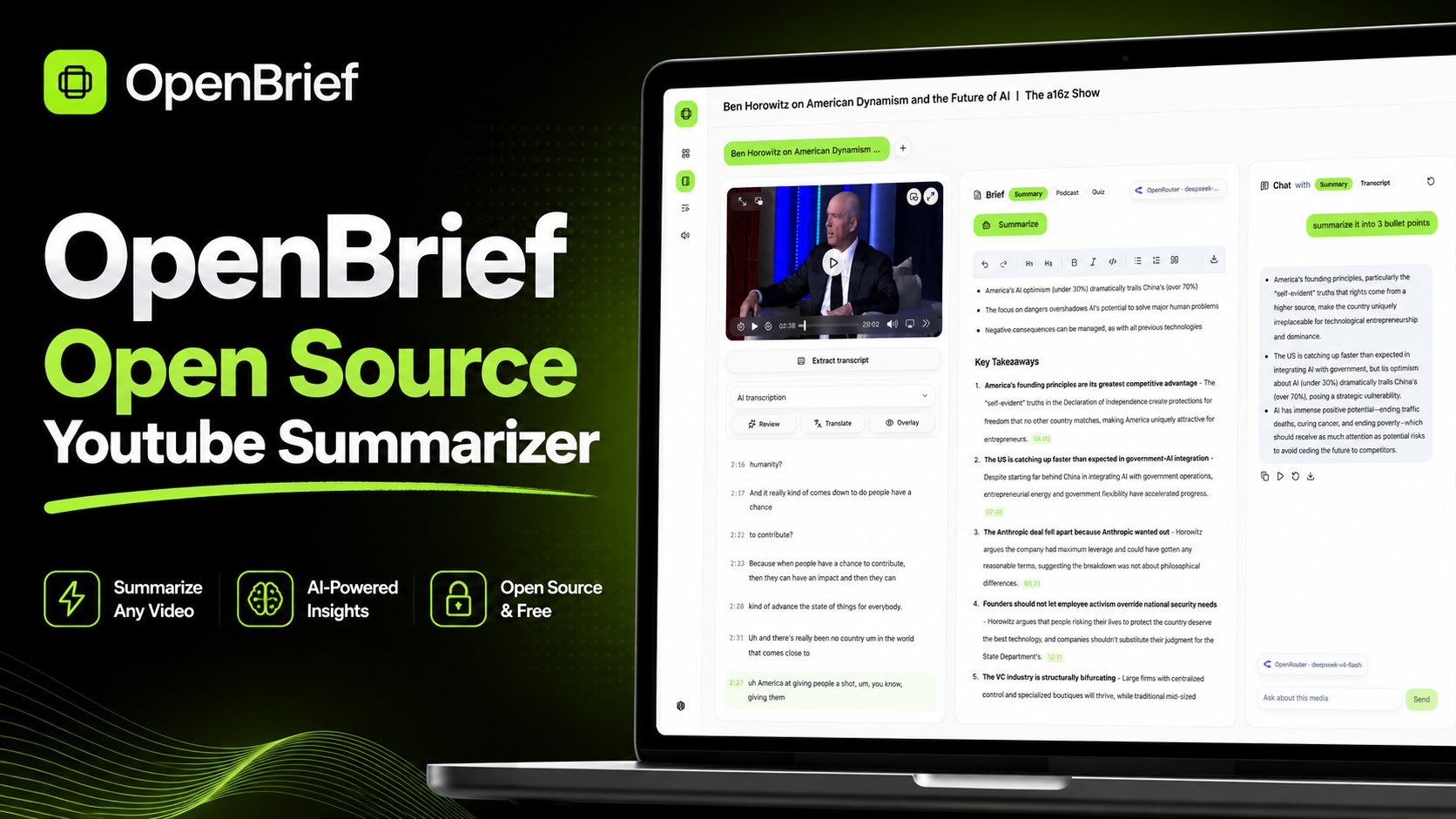
The application's core features include importing various media types, local transcription, generating blog-style markdown briefs with timestamped takeaways, conversational AI interaction, and text-to-speech conversion of summaries. Unlike many AI tools that process data in the cloud, OpenBrief emphasizes on-device processing to maintain user privacy.
The project structure reveals ambitions beyond the desktop app, with additional app shells for Next.js, TanStack Start, and React Native platforms, suggesting a future multi-device strategy. The shared packages include API routing, authentication integration, database schemas, and UI components, indicating a well-architected approach to scalability.
OpenBrief's roadmap outlines several planned improvements, including enhanced audio file support, additional document types (PDFs, HTML pages), more speech recognition and text-to-speech models, local LLM support, video embedding for semantic search, voice cloning capabilities, and sharing functionality through web and mobile apps.
The project acknowledges building on several existing open-source tools including yt-dlp for video downloads, whisper.cpp for speech-to-text, and various model implementations from organizations like Qwen and Supertonic. This approach of leveraging existing tools while creating a cohesive user experience is characteristic of many successful open-source projects.
Licensed under the GNU Affero General Public License v3.0, Open positions itself as an alternative to cloud-based content summarization services, offering users control over their data while providing sophisticated AI-powered content analysis. The project represents the growing trend of AI tools that prioritize privacy through local processing, particularly as concerns about data privacy continue to rise.
For developers interested in contributing or extending the application, the project provides detailed setup instructions and development guidance, with requirements including Node.js ^22.21.0, pnpm 11.0.9, and Rust for the Tauri components.
As media consumption continues to grow, tools like OpenBrief that help users extract value from content efficiently may find significant adoption, especially among professionals who regularly process large amounts of video and audio information.
Comments
Please log in or register to join the discussion