
A detailed exploration of how careful microarchitectural optimizations can push a single-issue RISC-V pipeline to within 2.3% of a dual-issue superscalar design, reducing CPI from 1.316 to 1.068 through branch prediction improvements, hazard elimination, and forwarding enhancements.
Optimizing a Single-Issue Pipeline: Closing the Gap with Superscalar Performance
The journey from a basic five-stage pipeline to near-superscalar performance represents one of the most fascinating exercises in computer architecture optimization. This article examines how a single-issue RISC-V core, through systematic refinement of its microarchitecture, can achieve performance levels that rival wider, more complex designs. The results challenge conventional wisdom about the performance ceiling of simple pipelines and demonstrate that much of the performance gap between single-issue and superscalar processors stems from avoidable inefficiencies rather than fundamental architectural limitations.
Understanding the RISC-V Architecture
RISC-V stands as an open instruction set architecture, distinguished by its lack of licensing fees and proprietary extensions. Unlike ARM or x86, its specifications are public, allowing anyone to implement the architecture without legal restrictions. The base integer ISA, RV32I, provides a foundation sufficient for running real software with its 32-bit address space, regular 32-bit instruction format, and reduced instruction set computing philosophy.
The M extension adds hardware multiply and divide instructions, which becomes crucial for benchmarks like CoreMark that perform multiplication operations. Without this extension, the compiler must synthesize multiplication through sequences of shifts and additions—a process that can require 10-20 instructions for a single 32x32 multiply operation, significantly impacting performance.
The processor design landscape offers multiple architectural approaches, each representing distinct tradeoffs between complexity, frequency, and throughput:
Single-Cycle Design: Every instruction completes in one clock cycle, with the period determined by the slowest instruction. This approach wastes significant time as simpler instructions wait for the worst-case completion time.
Multi-Cycle Design: Instructions take as many cycles as needed, with the clock period sized for the longest single step rather than the complete instruction. This allows a faster clock but introduces control complexity through finite state machines.
Pipelined Design: The classic five-stage pipeline (IF, ID, EX, MEM, WB) allows multiple instructions to be in different stages simultaneously. This approach balances implementation complexity against throughput, achieving one instruction retired per cycle in steady state.
Superpipelining: Aggressively increasing pipeline depth to achieve higher clock frequencies, as exemplified by the Pentium 4's NetBurst architecture with its 20+ stages. This approach trades off increased branch misprediction penalties for raw frequency.
Superscaling: Issuing multiple instructions simultaneously to increase work per cycle rather than reducing cycle time. This approach introduces significant complexity in dependency detection and resource management.
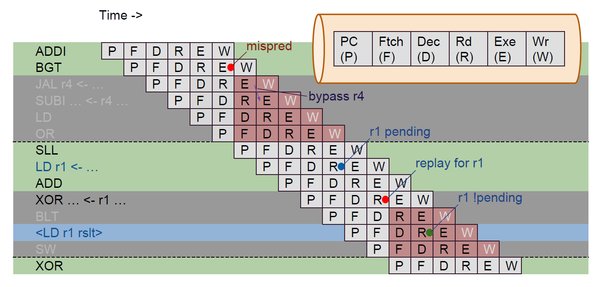
Figure: The optimization journey from a naive five-stage pipeline to near-superscalar performance
The Starting Point: Baseline Five-Stage Pipeline
The baseline implementation begins with a straightforward five-stage pipeline featuring standard forwarding and stall-on-load-use hazard handling. Without branch prediction, the pipeline stalls or flushes based on branch outcomes determined at the end of the EX stage.
Initial measurements reveal a CPI of 1.3158 and CoreMark/MHz of 2.572, indicating significant room for improvement. The overhead above the theoretical minimum CPI of 1.0 stems primarily from two sources:
- Branch penalties (approximately 0.21 CPI contribution)
- Load-use stalls (approximately 0.10 CPI contribution)
Every 0.001 reduction in CPI translates to roughly 30,000 cycles saved on this workload, establishing the value of each optimization step.
Step 1: Early Branch Resolution
The first major optimization moves branch resolution from the EX stage to the ID stage. This requires adding a dedicated comparator in the ID stage and implementing operand forwarding specifically for branch conditions. The result is a reduction in the worst-case branch misprediction penalty from two cycles to one.
Implementation Details:
- Added branch comparator in ID stage capable of evaluating all branch types
- Implemented forwarding logic to provide immediate values to the comparator
- Created redirect path for fetch stage based on early branch decisions
Results:
- Cycles: 38,877,313 → 35,812,817
- CPI: 1.315809553 → 1.212091142
- CoreMark/MHz: 2.572194225 → 2.792296400
- Improvement: +8.557%
This represents the single largest gain in the optimization journey, demonstrating the critical impact of branch penalties on pipeline efficiency. Moving branch resolution one stage earlier directly addresses a significant portion of the serial execution fraction that limits pipeline throughput.
Step 2: Branch Prediction Enhancement
While early branch resolution reduces penalties, it doesn't eliminate them completely. The next step introduces branch prediction to guess outcomes before they're known, allowing the fetch unit to speculatively continue from the predicted path.
Three predictor types were evaluated:
- Static backward-taken: Predicts backward branches as taken, forward as not-taken
- 1-bit dynamic: Records last outcome for each branch
- 2-bit saturating counter: Uses hysteresis to better handle loop behavior
The 2-bit saturating counter predictor proved most effective, providing better handling of loop exits where branches alternate between taken and not-taken states.
Results:
- Cycles: 35,812,817 → 33,466,269
- CPI: 1.212091142 → 1.132671809
- CoreMark/MHz: 2.792296400 → 2.988083315
- Improvement: +6.547%
Step 3: Branch Target Buffer Implementation
Direction prediction addresses only half the branch problem—the other half involves determining the target address when a branch is taken. The Branch Target Buffer (BTB) resolves this by caching target addresses, eliminating the one-cycle penalty even for correctly predicted taken branches.
Implementation Details:
- Direct-mapped BTB with 256 entries indexed by PC[9:2]
- Tag validation to ensure correct PC-to-target mapping
- Next PC logic incorporating BTB predictions
Results:
- Cycles: 33,466,269 → 32,347,569
- CPI: 1.132671809 → 1.094809209
- CoreMark/MHz: 2.988083315 → 3.091422419
- Improvement: +3.458%
Step 4: Hazard Detection Refinements
The baseline hazard detection logic conservatively stalls whenever the instruction in EX is a load and the instruction in ID has any register field matching the load's destination. This approach generates unnecessary stalls because it doesn't account for whether the ID-stage instruction actually uses those registers.
Implementation Details:
- Decoder now produces explicit use_rs1 and use_rs2 signals
- Hazard detection only triggers for registers actually used by the ID instruction
- Eliminates false stalls for instructions like LUI, AUIPC, and JAL that have register fields but don't read them
Results:
- Cycles: 32,347,569 → 32,346,765
- CoreMark/MHz improvement: +0.002%
While the gain is minimal, this optimization improves correctness by eliminating unnecessary stalls that technically represent a design flaw.
Step 5: Store-Data Forwarding
A specific optimization addresses the case where a load is immediately followed by a store using the loaded value. In the baseline pipeline, this triggers a load-use stall even though the store data doesn't need to be available until the MEM stage.
Implementation Details:
- Added forwarding path from MEM stage output to MEM stage data input
- Special handling for store instructions that need loaded values
Results:
- Cycles: 32,346,765 → 32,342,681
- CoreMark/MHz improvement: +0.013%
Again, the gain is small due to the relative rarity of this specific pattern in CoreMark, but the optimization eliminates a class of unnecessary stalls.
Step 6: Generalized Load-Use Forwarding
This step represents the most impactful hazard optimization, generalizing the entire load-use forwarding strategy. The key insight is that load-use stalls are only required when the consuming instruction needs the load result in the ID stage—for all other consumers (ALU instructions, stores, etc.), the operand is needed at the start of the EX stage.
Implementation Details:
- Extended forwarding network to cover MEM-to-EX paths for load results
- Only stall for ID-stage consumers (branches, JALR)
- MEM-to-EX forwarding delivers values exactly when needed for EX-stage consumers
Results:
- Cycles: 32,342,681 → 31,709,661
- CPI: 1.094643774 → 1.073219100
- CoreMark/MHz: 3.091889630 → 3.153613027
- Improvement: +1.996%
Step 7: Tournament Branch Predictor
Returning to branch prediction, a separate experiment line evaluated global branch history predictors and hybrid approaches. The tournament predictor combines local and global predictors with a chooser table that selects the more accurate prediction for each branch.
Implementation Details:
- Maintains both local and global branch history tables
- Chooser table records which predictor performs better for each branch
- Runtime selection based on chooser state
Results:
- Cycles: 31,709,661 → 31,566,209
- CPI: 1.073219100 → 1.068363941
- CoreMark/MHz: 3.153613027 → 3.167944557
- Improvement: +0.455%
Step 8: JAL Fast Path and Return Address Stack
The final optimization addresses two specific control flow patterns that standard branch prediction doesn't handle efficiently:
- JAL (Jump and Link): Unconditional direct jumps that always take the branch but still incur a one-cycle penalty without special handling
- JALR (Jump and Link Register): Indirect jumps used for function returns, which the BTB handles poorly when functions have multiple call sites
Implementation Details:
- JAL fast path that computes the target address during instruction fetch
- Return Address Stack (RAS) that tracks call/return relationships independently of the BTB
Results:
- Cycles: 31,566,209 → 31,540,922
- CPI: 1.068363941 → 1.067508098
- CoreMark/MHz: 3.167944557 → 3.170484363
- Improvement: +0.080%
Complete Optimization Journey
The cumulative effect of all optimizations demonstrates the power of systematic pipeline refinement:
| Optimization Step | CPI | CoreMark/MHz | Gain |
|---|---|---|---|
| Baseline pipeline | 1.315809 | 2.572194 | baseline |
| Early branch resolution | 1.212091 | 2.792296 | +8.557% |
| 2-bit direction predictor | 1.132671 | 2.988083 | +6.547% |
| BTB | 1.094809 | 3.091422 | +3.458% |
| False hazard cleanup | 1.094781 | 3.091499 | +0.002% |
| Store-data forwarding | 1.094643 | 3.091889 | +0.013% |
| Generalized load forwarding | 1.073219 | 3.153613 | +1.996% |
| Tournament predictor | 1.068363 | 3.167944 | +0.455% |
| JAL fast path + RAS | 1.067508 | 3.170484 | +0.080% |
Total improvement from baseline: +23.26% in CoreMark/MHz, with CPI reduced from 1.3158 to 1.0675.
Figure: RV32I processor variants showing the optimization trajectory
Closing the Gap with Superscalar Performance
The final optimized single-issue pipeline achieves remarkable performance, coming within 2.3% of a dual-issue superscalar implementation on the same CoreMark benchmark:
- Single-issue final: CPI 1.0675, CoreMark/MHz 3.170
- Superscalar: CPI 1.0435, CoreMark/MHz 3.243
- Gap: 0.0729 CoreMark/MHz (2.299%)
This striking result becomes more meaningful when examining IPC utilization:
- Superscalar theoretical max IPC: 2.000 (dual-issue)
- Superscalar actual IPC: 0.958 (47.9% utilization)
- Single-issue theoretical max IPC: 1.000
- Single-issue actual IPC: 0.937 (93.7% utilization)
The optimized single-issue core achieves 93.7% of its theoretical ceiling, while the unoptimized superscalar utilizes less than half of its own potential. This demonstrates that performance depends not just on architectural potential, but on how effectively that potential is realized through implementation quality.
Beyond CoreMark: Real-World Considerations
While CoreMark provides a standardized benchmark for comparison, it has characteristics that favor the optimizations implemented:
- Loop-heavy structure: After a few iterations, the branch predictor learns patterns and achieves near-perfect accuracy
- Regular control flow: The benchmark's predictable structure benefits from standard prediction techniques
- Limited call depth: The relatively simple call graph reduces the importance of advanced return prediction
Real-world applications with irregular control flow—such as compilers, operating systems, or servers handling varied requests—present different challenges. These applications may benefit more from the single-issue pipeline's shorter critical path, which allows higher clock frequencies or simpler timing closure.
Complexity Scaling and Practical Implications
The article raises an important question: would these optimizations provide similar benefits when applied to a superscalar design? The answer is nuanced:
- Some techniques transfer directly: Branch prediction, BTB, and RAS structures are largely independent of issue width
- Others become more complex: Hazard detection and forwarding logic scale combinatorially with issue width
- Timing challenges increase: More complex forwarding networks and dependency checking can push critical paths beyond target clock periods
For a dual-issue superscalar, the same techniques would likely yield meaningful improvements, but the implementation complexity increases significantly. The number of forwarding cases grows from approximately 2 paths in a single-issue design to roughly 8 in a dual-issue design, and verification becomes substantially more challenging.
Theoretical Framework: Amdahl's Law
The optimization journey can be formally understood through Amdahl's Law, which provides a bound on speedup when only a fraction of a system is improved:
$$S = \frac{1}{(1-p) + \frac{p}{n}}$$
Where $p$ is the fraction of execution time affected by the improvement and $n$ is the speedup factor applied to that fraction.
In the baseline pipeline, the avoidable stall fraction of total execution time is:
$$p = \frac{CPI_{baseline} - CPI_{floor}}{CPI_{baseline}} = \frac{1.3158 - 1.0}{1.3158} \approx 0.240$$
The theoretical maximum speedup from eliminating all stalls within a single-issue design is therefore:
$$S_{max} = \frac{1}{1-p} = \frac{1}{0.760} \approx 1.316$$
The realized speedup after all optimizations is $\frac{1.3158}{1.0675} \approx 1.233$, capturing roughly 73.7% of the available headroom. The residual 0.0675 CPI above the floor represents the serial fraction that single-issue techniques cannot eliminate.
Conclusion
The optimization journey from a basic five-stage pipeline to near-superscalar performance demonstrates that single-issue designs have significant untapped potential. By systematically addressing pipeline hazards and improving branch prediction, the CPI was reduced from 1.316 to 1.068—a 23.26% improvement in CoreMark/MHz.
The final result, a single-issue pipeline within 2.3% of a dual-issue superscalar, challenges conventional wisdom about the performance advantages of wider designs. It reveals that much of the performance gap between single-issue and superscalar processors stems from avoidable inefficiencies rather than fundamental architectural limitations.
This work highlights several key insights:
- Branch prediction and hazard handling are critical determinants of pipeline efficiency
- Single-issue pipelines can achieve remarkably high utilization of their theoretical potential
- The performance benefits of superscalar designs depend heavily on the quality of their implementation
- Systematic optimization, guided by performance metrics and theoretical frameworks like Amdahl's Law, can unlock significant performance improvements
As processor design continues to evolve, these principles remain relevant. Even as industry moves toward wider, more complex designs, the lessons from optimizing simpler pipelines provide valuable insights into the fundamental tradeoffs and opportunities in computer architecture.
For those interested in exploring the implementation details further, the complete project source code and additional documentation can be found at the project repository.
Comments
Please log in or register to join the discussion